.svg)


.svg)
We are excited to share another episode of Data Streaming Quick Tips by Gunnar Morling. The goal of this series is to explain one common task or challenge in the space of stream processing, for example joining data from multiple sources, running time-windowed aggregations, establishing data configurations, and much more. The series will cover upstream open source technologies like Apache Flink, Apache Kafka, Flink SQL, Debezium, as well as Decodable’s approach to stream processing. The episodes will be short and crisp, around 5 to 10 minutes.

Our third topic is Array Aggregation With Flink SQL. This article summarizes the video and covers how to aggregate the elements of an array with Flink SQL using both the built-in function JSON_ARRAYAGG() as well as a user-defined function (UDF) for emitting a fully type-safe data structure. The results of a one-to-many join are then ingested as a nested document structure into a search index in Elasticsearch.
Joining CDC Streams
The use case for array aggregation with Flink SQL is very often centered around processing change streams which are retrieved from a relational database. In the example we’ll explore today, we’ll look at multiple change streams in a one-to-many relationship and how we can emit them as a single document into an analytics engine such as Elasticsearch.
The example we’ll use is an e-commerce application driven by two data tables which contain information about the purchase orders placed by customers. The first table, purchase orders, contains one header entry for each order. The second, order lines, contains one entry for each order line of a purchase order—which means there is a one-to-many relationship between the two tables.
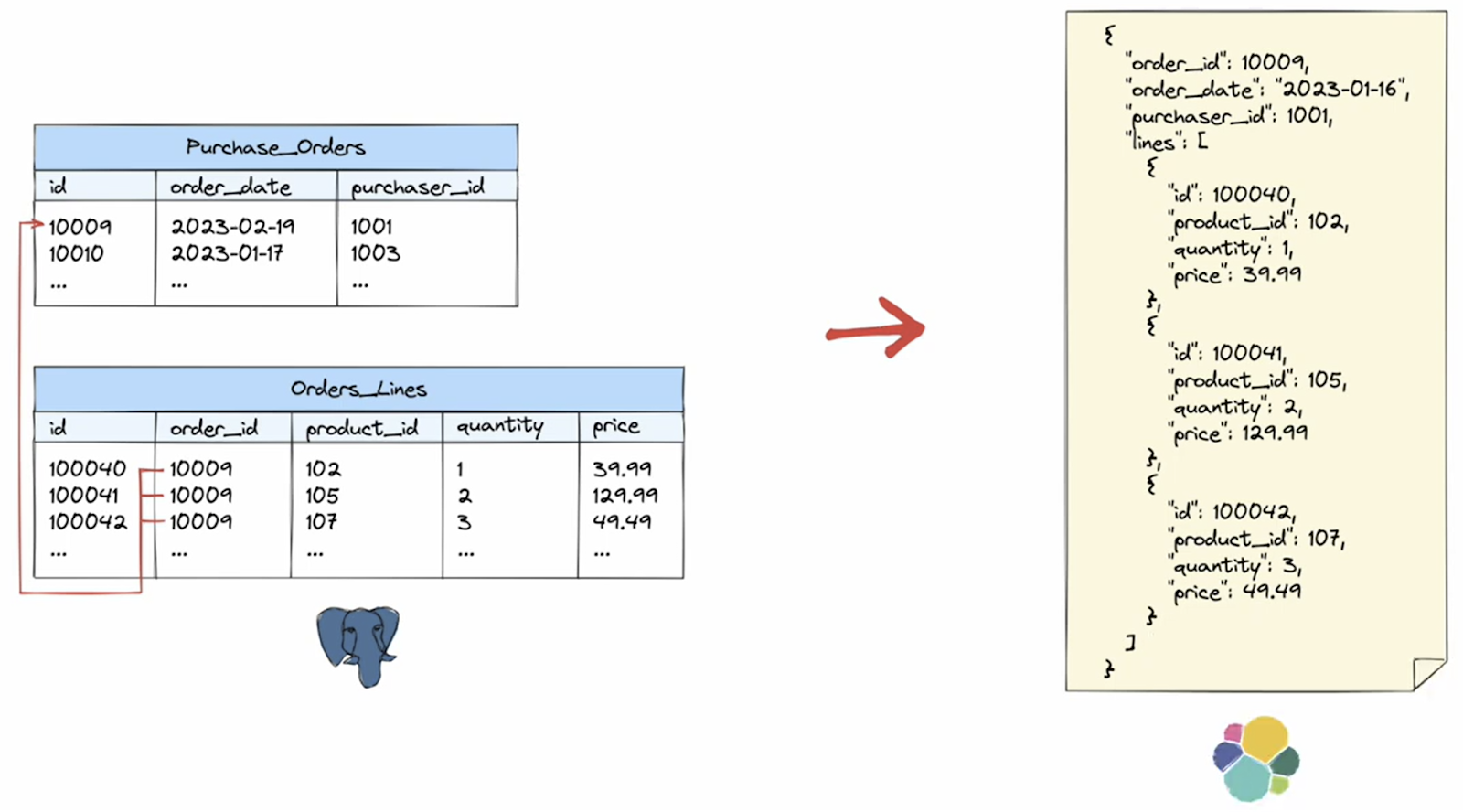
Let's assume we would like to implement a full-text search feature for orders and their associated lines using Elasticsearch. For this to work, we must compute the join between all our headers and line items, and then push one document for each purchase order to Elasticsearch which includes all the corresponding line items. This means we need to create a nested data structure with an embedded array containing the order lines.
Ingesting CDC Data Into Flink
We can take a look at the data in our database with a simple query that takes the purchase orders and the order lines tables and joins them on the order ID. Let's see how we can ingest the same data into Flink. Will start by creating a Flink table for the purchase orders table, with a schema that matches the table in the database. The create table statement specifies a Postgres CDC connection and the information about how to connect to the source, such as hostname, username, password, etc.
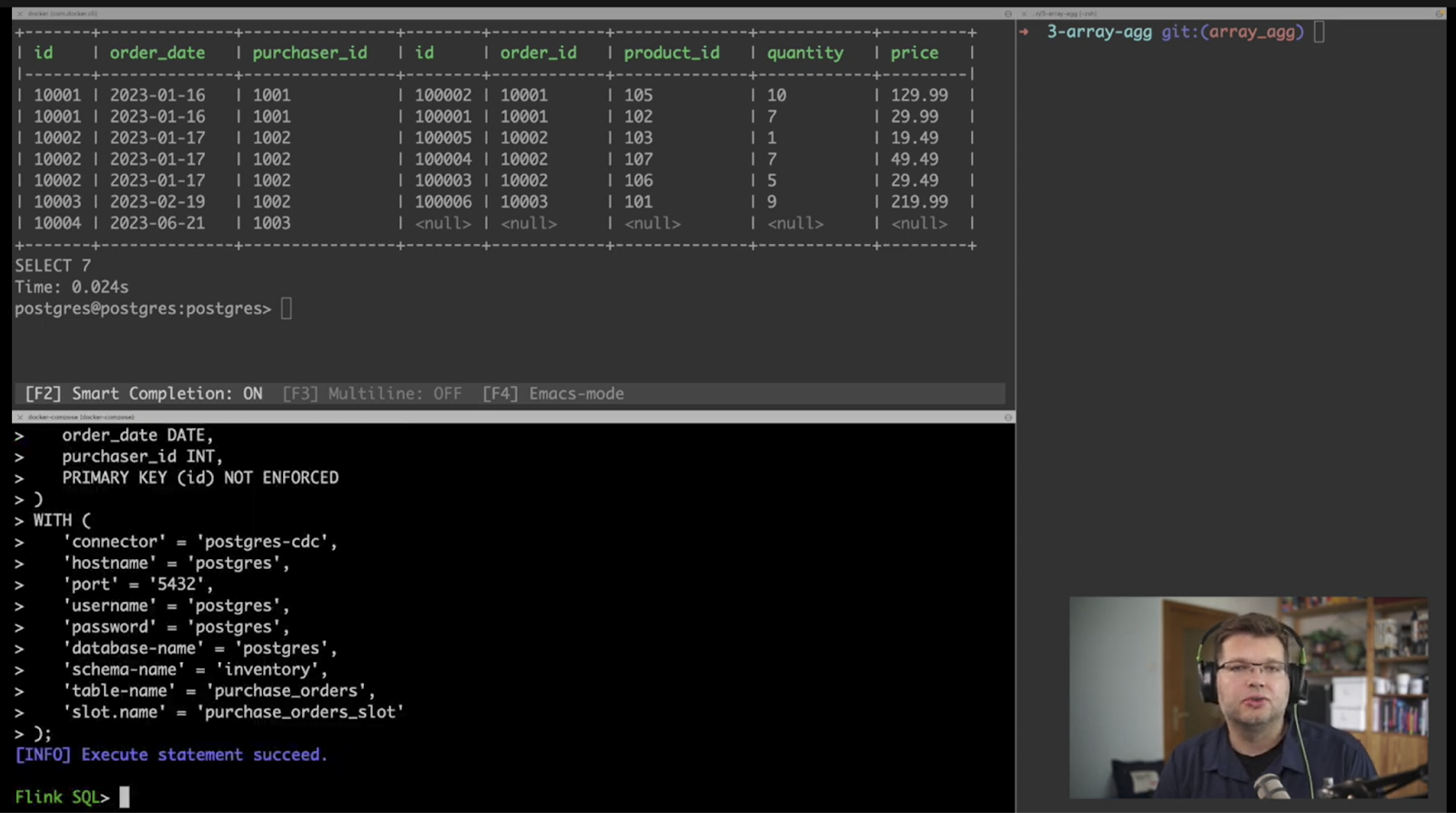
We’ll do the same for the order lines table, so we have those two tables in Flink. And just as with a relational database query, we can join the tables together. We can literally take the same SQL select statement and run this within Flink, so that now this join will be incrementally recalculated. When data changes in the source Postgres table, the Flink join query will be recomputed and we will see the new results.
Creating a JSON Array
The problem we face is that this sort of tabular result structure isn't well-suited for ingesting into a document store such as Elasticsearch. Right now, we have one row in our results set for each order line, whereas we actually would like to have one object structure for an entire purchase order. We need to take all the lines of an order and aggregate them into a single record. So let's see how we can go about solving this issue.
Let’s cancel the Flink join query and create a new table containing a lines string field which contains all the lines of one purchase order. In order to merge all the order lines of one order into a single string, we can use the JSON_ARRAYAGG() function which comes with Flink SQL. This takes an array of data and emits a string which contains a JSON-formatted array.
In order to populate this data, we can run a Flink insert query that selects all the purchase orders and sends them into a Redpanda topic for examination later on. For each purchase order, a subquery is used to select the associated order lines. The records which comprise the result of the subquery are converted into a JSON object using the JSON_OBJECT() function, which converts them into a single array. This is wrapped with the JSON_ARRAYAGG() function to convert the JSON array into one single string containing all the order lines for a given purchase order. We can now use Redpanda’s rpk command to examine the events which are coming into this topic, and we can see the stringified JSON lines field. Not quite ideal yet, but we are getting there.
The Power of User-Defined Functions
At this point, we have solved about half of our challenge. We have aggregated all the data per purchase order together with their order lines into a single object structure. However, this stringified JSON representation still isn't ideal—it’s not type safe and it won’t be easily ingested into Elasticsearch. So, let's see what we can do about this.
Let’s stop the existing job and drop the Flink table that has orders with the stringified order lines table. Instead, we’ll create a table using a typed structure for the order lines. So instead of just being a string, the lines field will be defined as an array of rows with a schema that describes the contents of an order line.
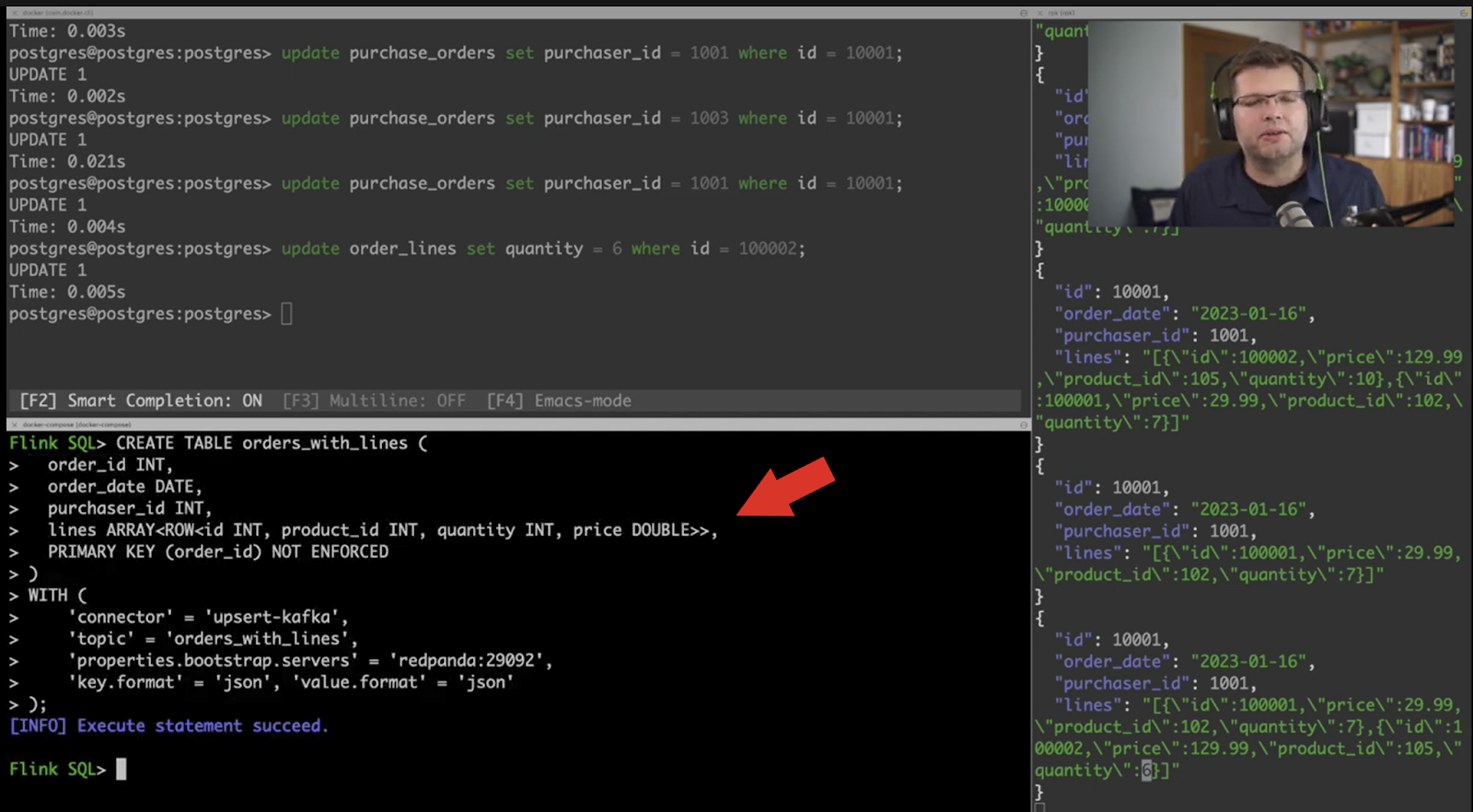
Of course now the question is, how can we actually populate this array of rows of order lines? There is no function in Flink SQL which can perform this very specific task. For this purpose we can implement a user-defined function, or UDF, which will take the rows that need to be assembled and emit them as an array. In the near future, we will do an entire separate video about UDFs and custom aggregate functions, so we won’t dive too much into the details of that at the moment. In order to use this function, it has been added to the Flink task and job manager applications and then registered in the environment as ARRAY_AGGR().
Now we can populate our Flink table by running an insert query which uses this custom array aggregation function to collect and consolidate all the order lines of each purchase order. When we look at the topic in Redpanda, the lines are no longer a single string but they are an array of those order line structures. And if the source database is changed, we can see how this update gets reflected properly and can now be easily ingested into Elasticsearch.
UDF Compute Frequency
One final area to discuss is how often this aggregation actually gets computed and the corresponding events get emitted to our topic in Redpanda. Let’s insert a new purchase order which has three order lines and then take a look at the events on the topic to see how often the results are emitted. What we see is for those three lines, the aggregation function was run three separate times. However, emitting all those intermediary events isn't ideal. It would for instance produce unnecessary load on the Elasticsearch cluster.
However, there is a feature in Flink SQL which can help us with this, and it is called mini-batching. Let’s stop the current job and enable mini-batching, which gives us some control over how long and how many events we would like to buffer before emitting an aggregation. Let’s recreate the query and once again insert some new order lines. This time there is only a single update event emitted and it contains all the new lines without any of the intermediary events, which is much more efficient.
Ingest into Elasticsearch
Okay, let's finally ingest the data into Elasticsearch! To make things a bit more interesting we’ll also join our order data with the customers’ data as well as their phone number data. Let’s create two more Flink CDC tables, the customers table and the customer phone numbers table, so we can also ingest any changes to those two tables. Then we can recreate the table which will send the data stream into Elasticsearch. The table now has two arrays, one for the order lines and a second one for the customers’ phone numbers, using our UDF aggregation function to create both those arrays.
Taking a look at the data in Elasticsearch we can see the order data with the purchases information, the customer phone numbers, and the order lines. So let's make sure it works when we insert another phone number record, and yes, indeed it does. We can also see if delete events are propagated, and that works just as well.
So that is a quick look at how to aggregate the contents of an array using Flink SQL, either using the built-in JSON_ARRAYAGG() function or using a custom UDF. In the coming weeks, we’ll show you how to take a custom UDF and deploy it as part of a pipeline in the Decodable platform so that you can avoid building, managing, and maintaining your own enterprise-ready Flink stream processing environment.
Additional Resources
- Check out the example code in our GitHub repository
- Have a question for Gunnar? Connect on Twitter or LinkedIn
- Ready to connect to a data stream and create a pipeline? Start free
- Take a guided tour with our Quickstart Guide
- Join our Slack community





.svg)