.svg)


.svg)
When you're using Flink SQL you'll run queries that interact with objects. An <span class="inline-code">INSERT</span> against a <span class="inline-code">TABLE</span>, a <span class="inline-code">SELECT</span> against a <span class="inline-code">VIEW</span>, for example. These objects are defined using DDL—but where do these definitions live?
If you're coming to Flink SQL from a RDBMS background such as Postgres you may have never given the storage of object definitions a second thought. You fire up <span class="inline-code">psql</span>, you <span class="inline-code">CREATE TABLE</span>, and off you go. Every time you connect to the database, there are your tables. But if you go and ask your DBA, you'll find out quickly enough about the information schema—implemented in Postgres as its system catalog and in Oracle as static data dictionary views over catalog data—and these are stored within the database itself.
Catalogs are where your object definitions live, and as a user of Flink SQL this is something you need to know about. That's because Flink is a query engine that works with numerous different sources and targets of data, and it needs to know where to find them and how to interact with them. This is what the catalog tells it.
This apparent complexity has come about as a result of the decoupling of storage and compute—a trend which began with Apache Hadoop. Unlike an RDBMS, it’s no longer self-evident where the catalog lives.
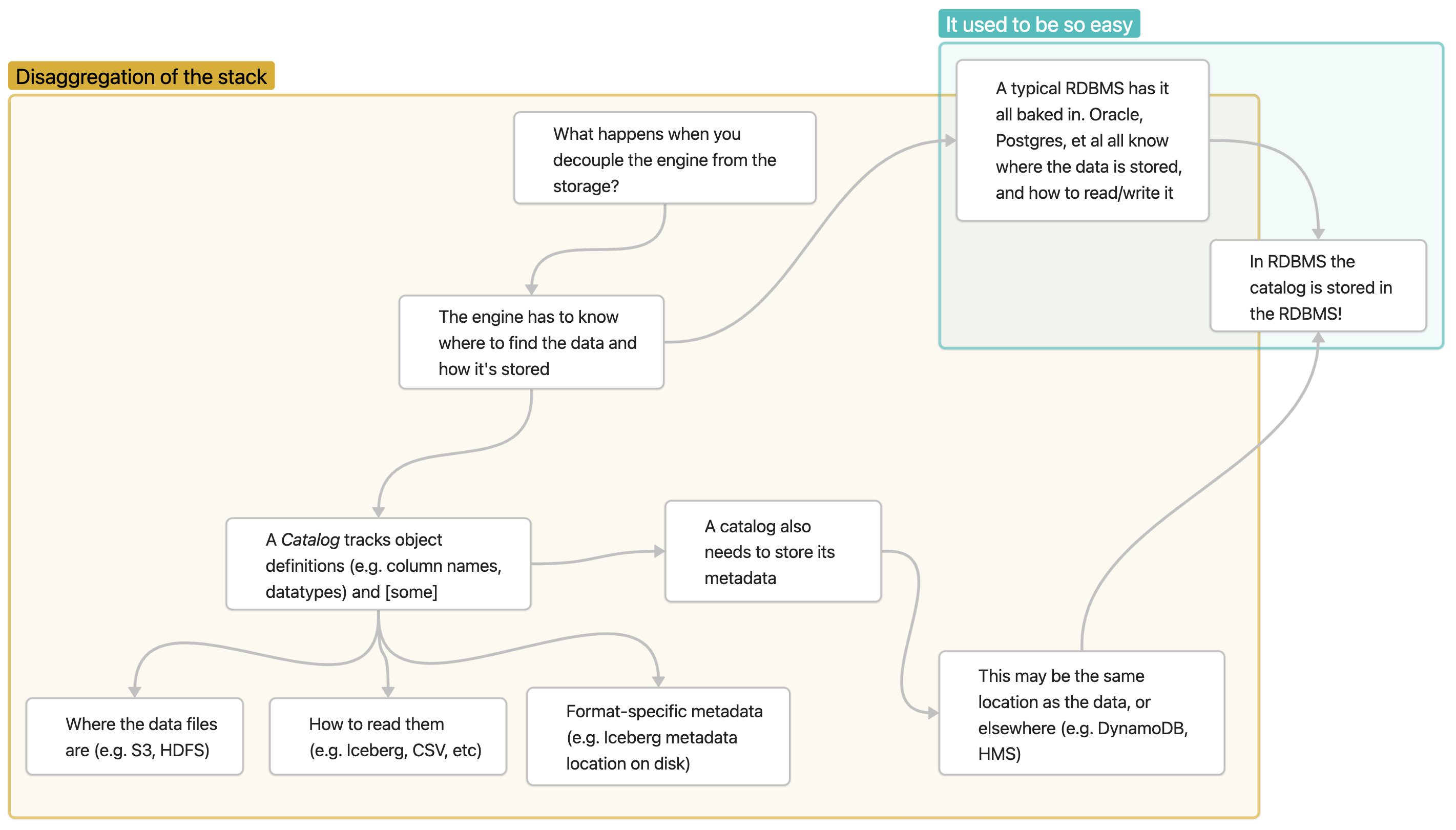
You can think of the Flink catalog in RDBMS terms like external tables. Whilst regular tables in the RDBMS have their definition and location of the data internal to the RDBMS, with external tables the RDBMS' system catalog tracks the existence of the object's definition and location of the data, but the data and possibly additional metadata exists outside of the RDBMS. In the same way, Flink itself doesn't store data but needs to know where the data behind tables that you define resides.
As we're going to see in this blog post, we get to experience the highs and the lows of an open-source ecosystem when we delve into Flink's catalogs. That's because there are catalogs, and then there are catalogs. One of the most confusing things I found in my research on Flink catalogs is that different things with the name "catalog" actually do different things, including:
- Telling a query engine about objects that the user creates and/or reads from:
• in one system only
• in multiple systems
- Telling a query engine about objects that already exist on another system, but not creating new ones
- Persisting these object definitions for re-use
Completely separate from this ambiguous mish-mash of catalog meanings is the much more distinct—and nothing to do with Flink, per se—Data Catalog which any good enterprise vendor will sell you. These literally catalog your data, less for the purpose of supporting query engines but more from a governance, discoverability, and audit/compliance point of view.
We Never Said That This Would Be Easy
The fun thing about running Flink SQL for yourself is that you get to run Flink SQL for yourself. The less fun thing is that you have to run Flink SQL for yourself 😉
Flink is first and foremost a Java system, and whether you like it or not as an end user, even of Flink SQL, you're going to get exposed to that. Perhaps you've got a solid Java background and crush classpath errors with your bare fists—but perhaps not. If you're doing this locally then whether you like it or not you're going to have to understand something about the mechanics of catalogs in Flink - what they are, what they're not, and how to use them.
In this blog series I'm going to walk you through examples of setting up and using Catalogs in Flink SQL, and also point out some of the fun Java stuff along the way, usually involving JARs, CLASSPATHs, and occasionally some wailing and gnashing of teeth.
Flink's Default In-Memory Catalog
Let's get started! Out of the box, Flink is pre-configured with an in-memory catalog. That means that when you create a table, it stores it and you can see it when you list the available tables.
However, by virtue of it being in-memory, if we restart the session, the catalog contents are now empty:
Let's familiarize ourselves with a few more SQL commands before we go much further.
- <span class="inline-code">SHOW</span> can be used to list various types of object, including <span class="inline-code">TABLES</span>, <span class="inline-code">DATABASES</span>, and <span class="inline-code">CATALOGS</span>. The default catalog in Flink is the <span class="inline-code">default_catalog</span>:
- <span class="inline-code">CREATE CATALOG</span> can be used to … create a catalog. We'll see a lot more of this later. For now, let's create a second in-memory catalog:
- Now that we've got another catalog, we want to tell the SQL Client to use this one and not the other one. That's where <span class="inline-code">USE</span> comes in:
Catalogs store information (metadata) about tables. The actual data is stored wherever you tell Flink to store it. Here's a table that's just writing to a local folder (which BTW is a bad idea on a distributed system, because 'local' is relative to the process that's running it, and if those processes are not on the same machine confusing things will happen. Ask me how I know):
Inspecting the data on disk we can see it's actually stored there:
But when we query it, how does Flink know that <span class="inline-code">a, 42</span> is to be translated into two fields, called <span class="inline-code">c1</span> and <span class="inline-code">c2</span> of type <span class="inline-code">STRING</span> and <span class="inline-code">INT</span> respectively?
Well that's the catalog. The metadata about the data. This metadata is in essence what we define in the initial <span class="inline-code">CREATE TABLE</span> DDL statement:
- The fields: <span class="inline-code">c1 varchar, c2 int</span>
- The location of the data and how to interpret it: <span class="inline-code">'connector' = 'filesystem', 'path' = 'file:///tmp/t_foo', 'format' = 'csv'</span>
And this precious metadata—what happens if we restart the SQL Client?
As we noted above: the default catalog doesn't persist metadata across sessions, making it useless for anything other than idle twiddling. Let's now look at the options available for us to store this metadata properly.
Flink Catalog Types
The Flink project includes three types of catalog, but confusingly they're all a bit different.
- In-memory we've covered already. You can create and use new objects, but there's no persistence.
- Hive enables you to define and store objects, using the Hive Metastore which is backed by a relational database.
- JDBC is a bit different, since it exposes query access to existing objects in a database connected to by JDBC. However, it doesn't support storing new objects.
Using a centralised metastore, such as Hive's, is important if you are wanting to make the most of different tools that can work with the same format of data without having to redefine the metadata each time. For example, writing to a table using Flink, to be processed by another team using Spark, which yet another team queries it with Trino.
Catalogs in Flink are pluggable, and in addition to the catalogs that are provided by Flink there are several others that you have available to you. It's worth noting that only the in-memory catalog actually ships with Flink; to use the Hive or JDBC catalog you must include the needful dependencies (which we'll discuss below).
Additional catalogs are usually paired to a particular technology that you're using with Flink and often ship as part of the connector for that system. The JDBC one above is an example of this—it's only useful if you're connecting to a database to read data, and is included in the JDBC SQL Connector. Other catalog implementations include:
- Open-Table Formats: Apache Iceberg, Apache Hudi, and Delta Lake
- AWS Glue Catalog on EMR (with an open FLIP and PR to make it available outside of EMR)
- Apache Pulsar
- Apache Paimon
- Apache Kudu
Hold on to your seats…because this gets confusing
At a minimum, each type of catalog tells Flink about objects that are available to query. Some of them also let you define new objects. And some also persist these definitions.
Let's look at some examples.
- The Hive and Glue catalogs expose existing objects, hold definitions of new ones, and persist all of this information.
- Whether creating a table that is persisted on S3, or reading from a Kafka topic, these catalogs will store those definitions. When you start another session connecting to the same catalog, or a different user connects to these catalogs, the definitions will still be present.
- The JDBC catalog simply exposes access to objects that exist on the target.
- You can't create new ones, and thus persisting the information (a metastore) is irrelevant.
- Iceberg, Hudi, and Delta Lake provide Flink catalogs to read and write tables written in their respective formats. Each uses its own metadata, some of which is held in the catalog and other alongside the datafiles themselves.
- All of them support using Hive Metastore for persistence of the table definitions. Iceberg includes multiple persistence options should you want them, including DynamoDB, REST, and JDBC.
- Fun fact: when is a JDBC Catalog not a JDBC Catalog? When one is the JDBC Catalog provided by Iceberg to persist catalog metadata, and the other is a JDBC Catalog provided by Flink to expose existing database tables for querying in Flink 😵💫
You thought that was confusing?
Just to spice things up even more, different Catalog implementations vary in how you configure the persistence implementation.
Starting with the Hive catalog itself, you specify:
So far, simple, right? Now we get onto other catalog types, which get first claim on type, and the persistence is configured with <span class="inline-code">catalog-type</span>… ok?
Here's Iceberg:
and Delta Lake:
To really keep you on your toes, Hudi switches this up, and instead uses <span class="inline-code">mode:
Finally (I hope), just to really wrangle your wossits, Iceberg also uses <span class="inline-code">catalog-impl</span> for catalogs that don't support <span class="inline-code">catalog-type</span>:
…and breathe
Let's zoom waaay back up to the surface here, and reorientate ourselves. I’m sure the reasonings and rationale for the above state of catalog implementations are good ones, but in a way it doesn't matter. As humble SQL monkeys we just need to know which catalog we'll use, and how to configure it. That's going to be dictated by the technologies we're using, and perhaps existing catalogs (e.g. Hive Metastore, AWS Glue) in our organisation.
Once we know the catalog, we can dive into the docs to understand the specific configuration to use. And then rapidly move on to actually running Flink SQL with it, and forget we ever cared about the inconsistencies and frustrations of <span class="inline-code">CREATE CATALOG</span> with a <span class="inline-code">type</span> but that <span class="inline-code">CATALOG</span> whose <span class="inline-code">type</span> we defined also having a <span class="inline-code">catalog-type</span> 😉
Catalog Stores: It's Metadata all the way down
Let's take a moment for a brief tangent. We've talked about tables having data, and metadata, and catalogs storing that metadata or at least pointers to it. But who watches the watchers? Who stores the metadata about the catalogs? As mentioned, catalogs are not pre-configured in Flink (except for the in-memory one).
Each time you start the SQL Client, you'll see this:
So each time—assuming you want to access and persist metadata about the objects that you're creating—you'll need to go and <span class="inline-code">CREATE CATALOG</span>. Which gets kinda tedious. This is where a Catalog Store comes in. Whilst the catalog [metastore] holds the metadata about the objects in the catalog, a catalog store holds the metadata about the catalogs.
By default, Flink will use an in-memory catalog store, which sounds fancy until you realise that it isn't persisted and when you restart your SQL Client session the catalog store will be empty. The alternative (out of the box, at least) is the FileCatalogStore which writes details about your catalog(s) to disk. Note that it writes details about the catalog, and not its contents. So if you’re using the in-memory catalog, you still can’t persist table definitions across sessions. With a CatalogStore configured you’d just persist the definition of that in-memory catalog.
NOTE: in older versions of Flink you could store SQL Client configuration, including catalog definitions, in <span class="inline-code">sql-client-defaults.yaml</span>. This was deprecated in 1.15 as part of FLIP-163 and should not be used.
To use the FileCatalogStore with Flink SQL add these lines to your <span class="inline-code">conf/flink-config.yaml</span> in your Flink installation folder:
Now launch the SQL Client and define your catalog:
Check out the metadata about the catalog definition:
Launch the SQL Client and leap with delight as your catalog is present:
Fortunately in Catalog Stores there's nothing much confusing. It's clear why we need it, it works, and the configuration is straightforward. If only life were that simple back in the land of Catalogs themselves! In my next post I’m going to look at the use of the Hive and JDBC catalogs that are part of Flink, as well as a couple of others in the ecosystem.
Wrapping up Part One
One of the reasons I enjoy blogging is that it forces me to get a real handle on something that I’m trying to explain. What started off as a big ball of very confusing mud to me has clarified itself somewhat, and I hope the above writing has done the same for your understanding of catalogs in Flink SQL too.
In the next post I’m going to show you how to use the built-in Hive catalog for Flink SQL, the JDBC catalog that is a catalog—but not how you might think—and also look at the wider ecosystem of catalogs that are supported in Flink including Apache Iceberg.
I’ll wrap up the series with a magical mystery tour through the desolate landscape of troubleshooting Flink SQL catalog deployments and configurations. Stay tuned for all the fun!
Fun fact: if you use Decodable’s fully managed Flink platform you don’t ever have to worry about catalogs—we handle it all for you!
Cover photo credit: Daniel Forsman






.svg)