.svg)



One of the things that I love about SQL is the power that it gives you to work with data in a declarative manner. I want this thing…go do it. How should it do it? Well that’s the problem for the particular engine, not me. As a language with a pedigree of multiple decades and no sign of waning (despite a wobbly patch for some whilst NoSQL figured out they actually wanted to be NewSQL 😉), it’s the lingua franca of data systems.
Which is a long way of saying: if you work with data, SQL is mandatory. There, I said it. And if you’re transforming data as part of an ETL or ELT pipeline, it’s one of the simplest and most powerful ways to do it. So let’s see how we can use it with two different platforms in the market that are both built on Apache Flink but expose their support for SQL (specifically, Flink SQL) in very different ways. The first of these is Amazon’s MSF (Managed Service for Apache Flink), and the second is Decodable.
At this point a disclaimer is perhaps warranted, if not entirely obvious: I work for Decodable, and you’re reading this on a Decodable blog. So I’m going to throw MSF under the bus, obviously? Well, no. I’m not interested in that kind of FUD. Hopefully this blog will simply serve to illustrate the similarities and differences between the two.
Let’s build something!
I’m going to take a look at what it takes to build an example of a common pipeline—getting data from a Kafka topic and using SQL to create some aggregate calculations against the data and send it to an S3 bucket in Iceberg format.
I’ll start by exploring Amazon MSF and what it takes to build out the pipeline from the point of view of a data engineer who is deeply familiar with SQL—but not Java or Python (hence this blog - Flink SQL!). After that I’ll look at doing the same thing on Decodable and what the differences are.
Running SQL on Amazon MSF
After logging into the AWS Console and going to the MSF page, I have two options for getting started, <span class="inline-code">Streaming applications</span> or <span class="inline-code">Studio notebooks</span>.
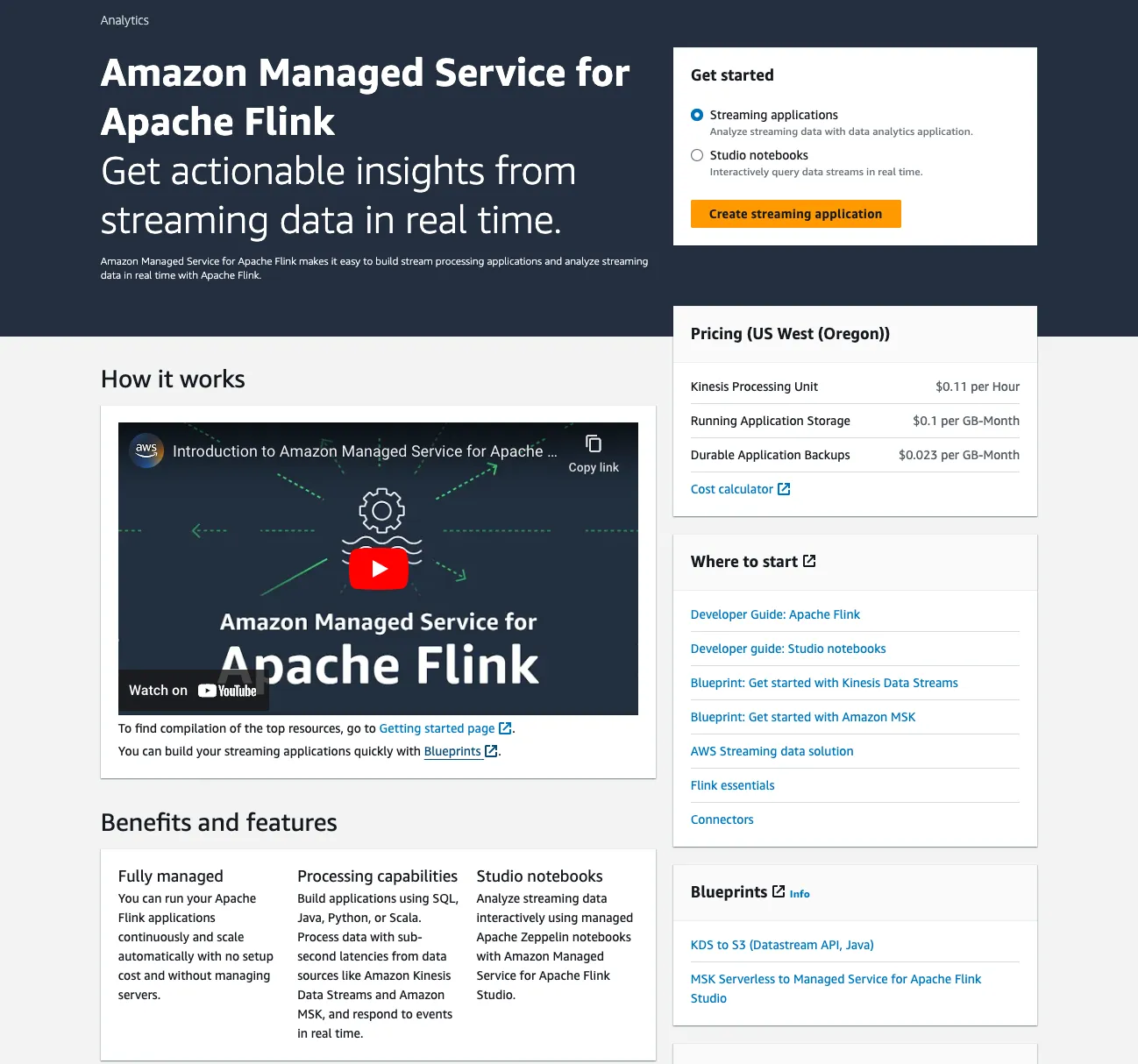
Having not used MSF before and following the logic that since I’m building a pipeline rather than just exploring data, I initially went down the route of creating a <span class="inline-code">Streaming application</span>. This turned out to be a dead-end, since it’s only if you’re writing Java or Python. Whilst you can wrap Flink SQL within these, it’s hardly the pleasant developer experience I was hoping for. I subsequently made my way over to <span class="inline-code">Studio notebooks</span>. This gives you what it says on the tin—a notebook. Beloved of data scientists and analysts, notebooks are brilliant for noodling around with bits of data, creating reproducible examples to share with colleagues, etc.
Jupyter and Apache Zeppelin are the two primary notebook implementations used, and here Amazon has gone with a pretty vanilla deployment of Zeppelin. This is what you get after creating the notebook and starting it up:
This is almost too vanilla for my liking; as someone coming to MSF with the hope of doing some Flink SQL, I’m pretty much left to my own devices to figure out what to do next. I clicked on <span class="inline-code">Create new note</span> and ended up with this:
’k cool. Now what?

(Ironically, if you were to run the latest version of Zeppelin yourself you’d find that it ships with a whole folder of Flink examples—which would have been rather useful here.)
Anyway, back on Amazon MSF I went back a screen and opened the <span class="inline-code">Examples</span> notebook. This at least made more sense than a blank page. 🙂
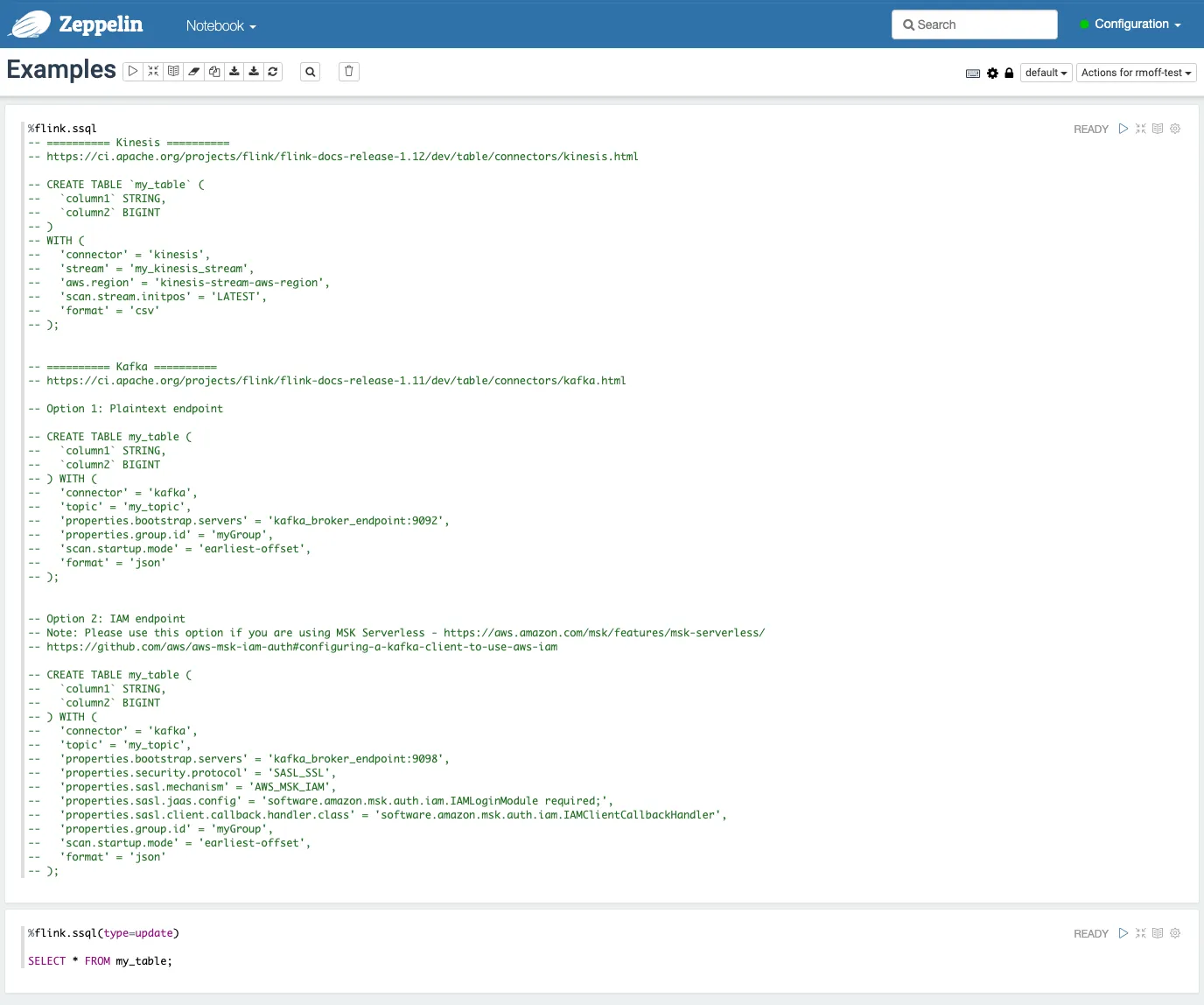
The <span class="inline-code">%flink.ssql</span> in each cell denotes the interpreter that’s used to execute the code in that cell—there are several Flink interpreters available for Apache Zeppelin.
So let’s actually give it a go. As mentioned above, the pipeline we’re building is to stream data from a Kafka topic into Apache Iceberg on S3, calculating some aggregations on the way.
Reading data from Kafka with Amazon MSF
Having explored Flink SQL for myself over the past few months I knew to go and look up the Kafka connector for Flink. Connectors in Flink SQL are defined as tables, from which one can read and write data to the associated system. The <span class="inline-code">Examples</span> notebook also gives, well, examples to follow too. To start with I wanted to just check connectivity, so I deleted out what was there in the cell and created a single-column table connecting to my cluster:
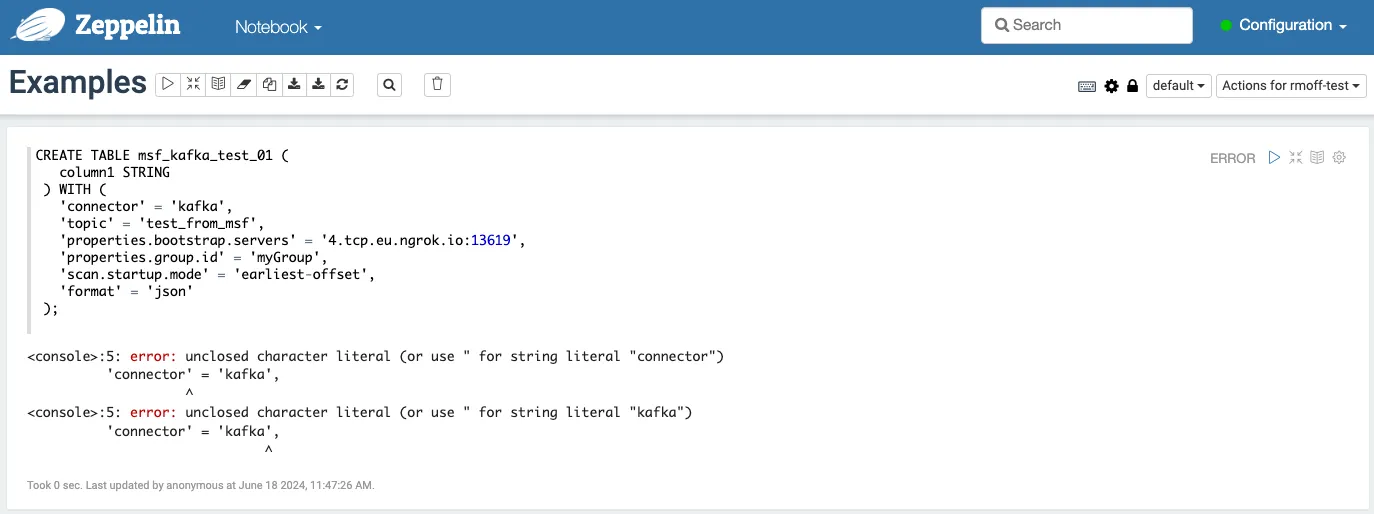
Hmmm, no good.
I mean, it looks OK to me. After some circling around, I realised that I’d not only deleted the existing example code, but the interpreter string too. With the magic <span class="inline-code">%flink.ssql</span> restored, my table was successfully created:
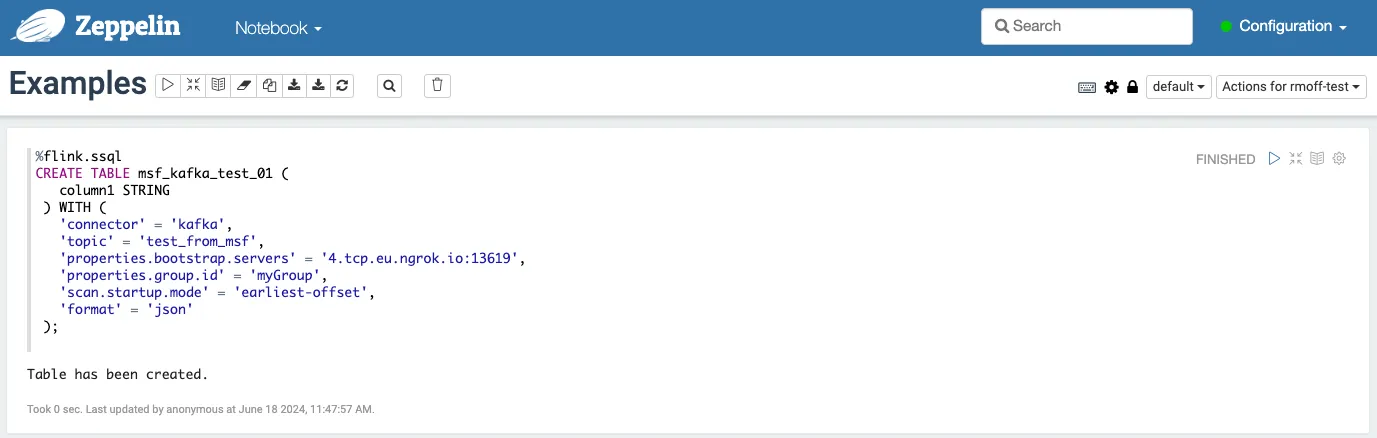
This is where the nice bit of notebooks comes in—I can build up this example step by step, and actually share the notebook at the end with you, dear reader, and you’ll be able to run it too. I can also add comments and narration, within the notebook itself.
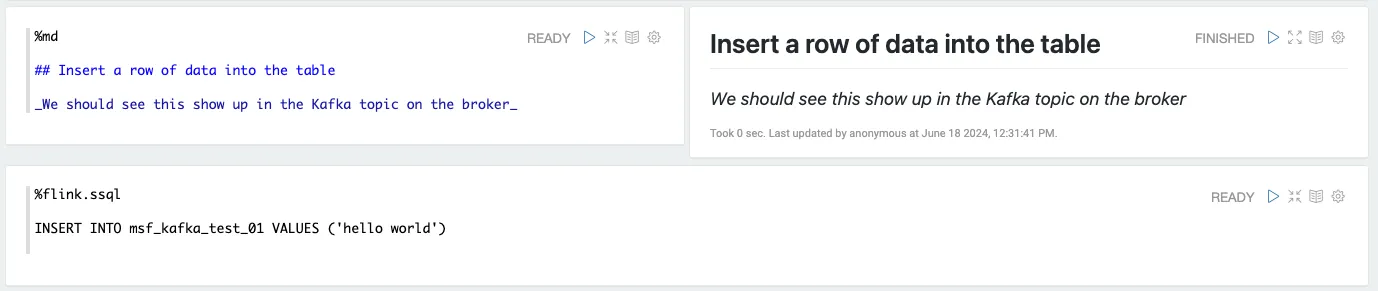
Now let’s run the <span class="inline-code">INSERT</span> shown here, which if all has gone well should result in a message in JSON format (as specified by <span class="inline-code">format</span> in the table definition) in my <span class="inline-code">test_from_msf</span> topic:
Looks good! Let’s bring in the actual Kafka topic that we want to read from. The data is simulated transactions from a chain of supermarkets and looks like this:
Our first task is to come up with the DDL to declare this table’s schema. You can do this by hand, or trust to the LLM gods—I found Claude 3 Opus gave me what seemed like a pretty accurate answer:

The only thing I needed to change was quoting the reserved word <span class="inline-code">timestamp</span> being used as a field name. Using this I started a new notebook that would be for my actual pipeline, and began with creating the Kafka source:
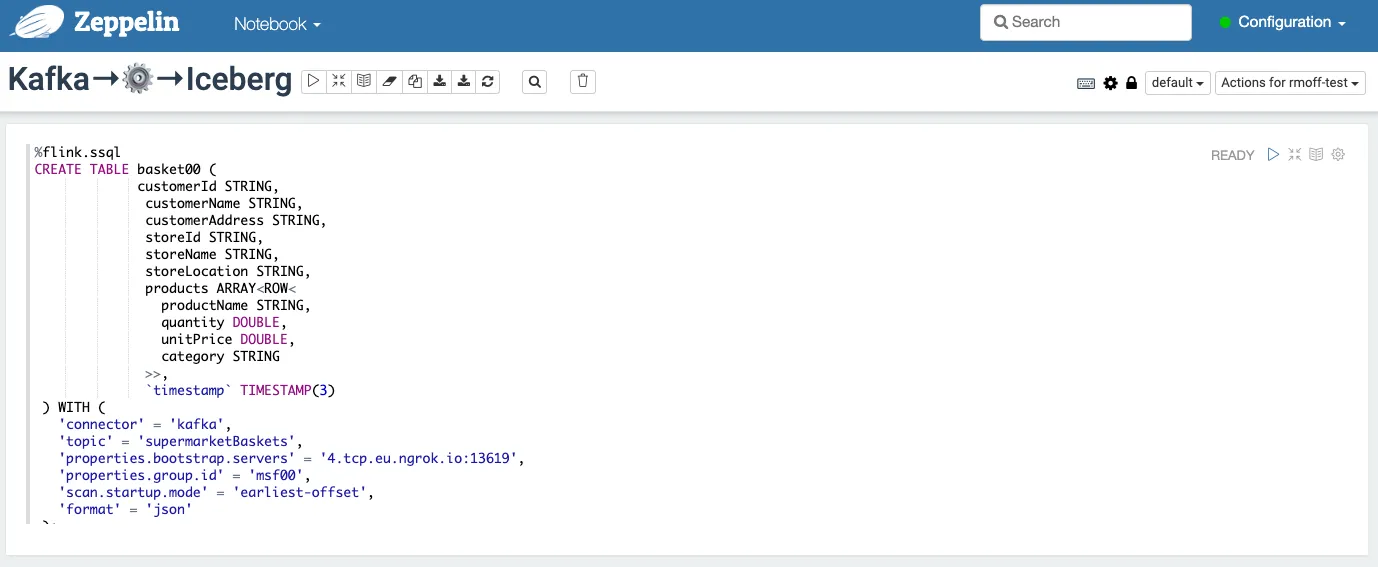
With the table created, let’s run a <span class="inline-code">SELECT</span> to sample the data to make sure things are working:

Instead of fighting with type conversions at this stage (that fun can wait!) I’m just going to make this a <span class="inline-code">STRING</span> field and worry about it later. Unfortunately, MSF has other ideas:

After some digging it turns out that <span class="inline-code">ALTER TABLE…MODIFY</span> was added in Flink 1.17 and MSF is running Flink 1.15.
Since we’re not using the table anywhere yet, let’s just drop it and recreate it.
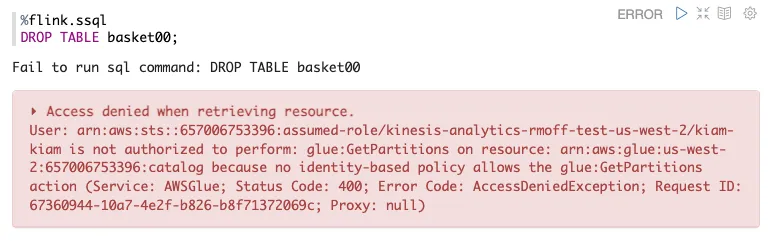
This is good, and bad. Mostly bad. The good bit is that it reminds me that when I created the notebook I selected an existing Glue catalog, and it looks like MSF is seamlessly using it. The bad? I need to go IAM-diving to figure out what the permission problem is here.
Or…sidestep the issue and just create the table with a different name 😁
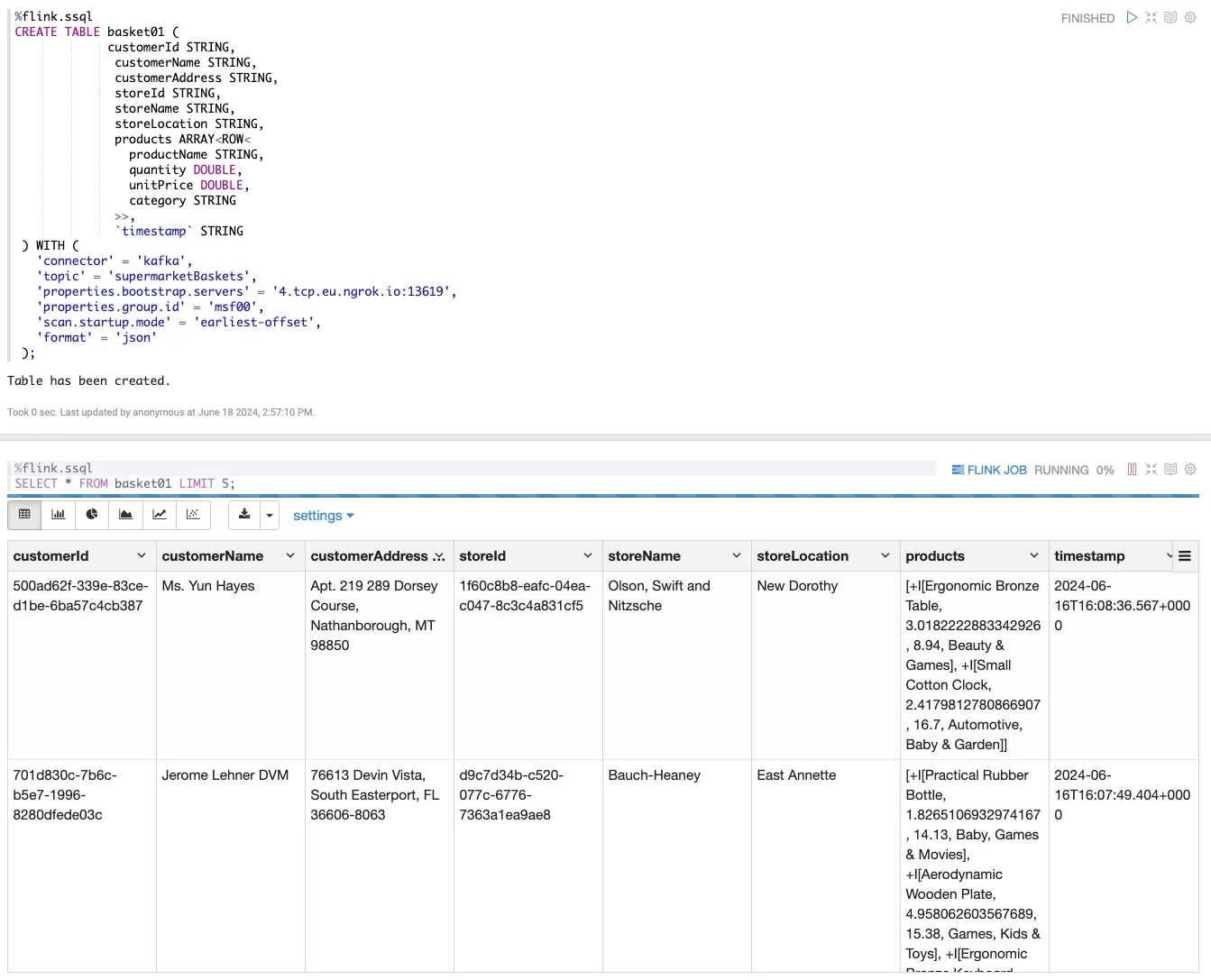
OK! Now we are getting somewhere. With data flowing in from our Kafka topic let’s build the second half of our pipeline, in which we’re going to compute aggregates on the data before sending it to Apache Iceberg.
Running Flink SQL to transform data on Amazon MSF
Whilst configuring the connection to Kafka might have been a bit more fiddly than we’d have liked, building actual transformational SQL in the Zeppelin notebook is precisely its sweet spot. You can iterate to your heart’s content to get the syntax right and dataset exactly as you want it. You can also take advantage of Zeppelin’s built-in visualisation capabilities to explore the data further:
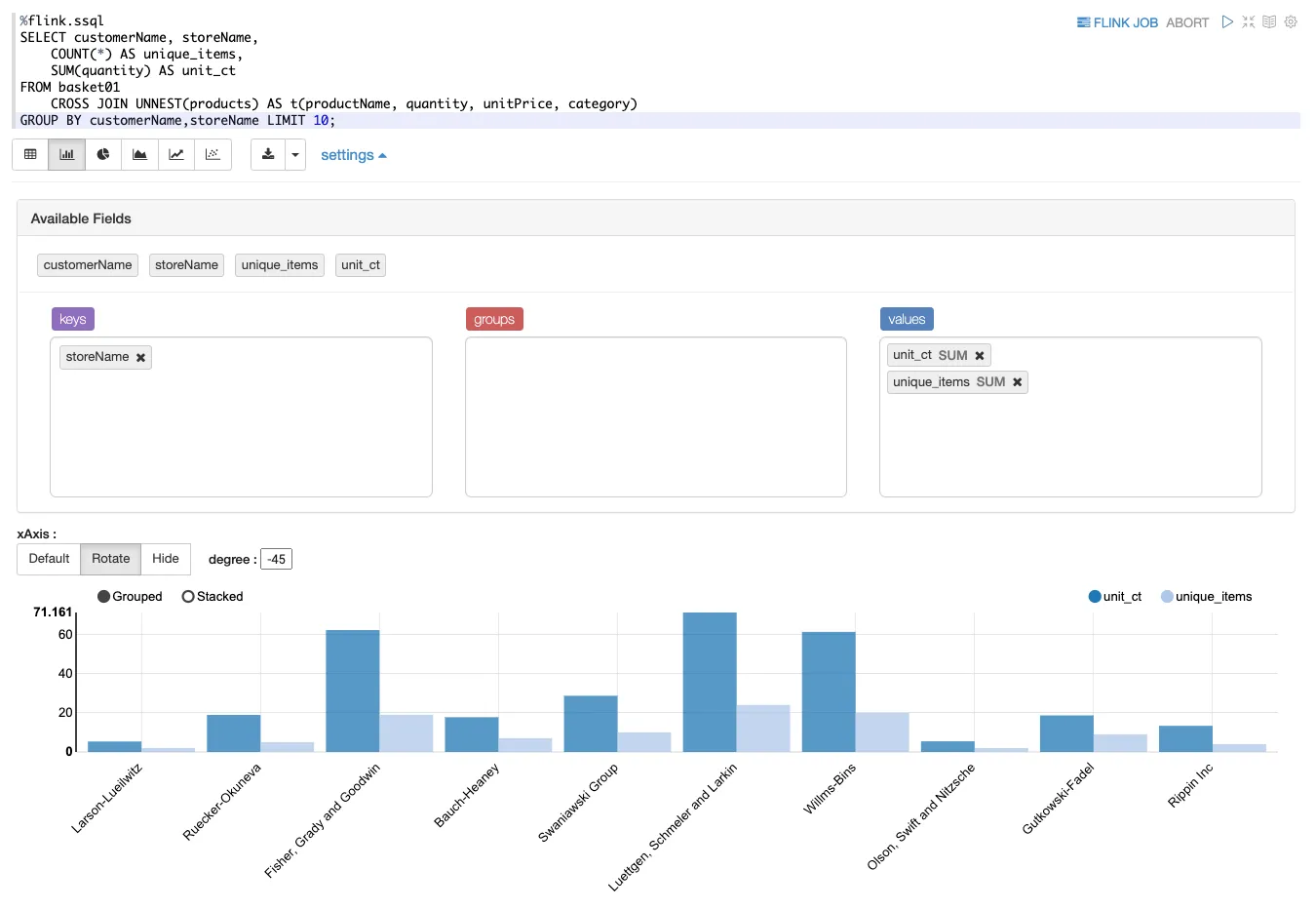
With the data exploration and noodling done, we’ll wrap our aggregate query as a <span class="inline-code">VIEW</span> to use later when we send it to Iceberg.
Here I’m using <span class="inline-code">UNNEST</span> to get at the individual records in the <span class="inline-code">products</span> array, and create a result set of the number of basket items (<span class="inline-code">COUNT(*)</span>) and total units (<span class="inline-code">SUM(quantity)</span>) broken down by customer (<span class="inline-code">customerName</span>).
Attempting to write to Apache Iceberg from Amazon MSF…
Just as we used a table to read data from Kafka above, we’ll use a table to write to Iceberg on S3.
If I were running this on my own Apache Flink cluster, I’d do this:
This is based on using Hive as a catalog metastore, whilst here I’m using Glue. I figured I’d slightly guess at the syntax of the command, assuming that I can randomly jiggle things from the resulting error to get them to work.
But I didn’t even get that far. MSF doesn’t seem to be happy with my<span class="inline-code">CREATE TABLE…AS SELECT</span>.

As with <span class="inline-code">ALTER TABLE…MODIFY</span> above, CREATE TABLE…AS SELECT (CTAS) wasn’t added to Flink until 1.16, and MSF is on 1.15. Instead, we’re going to have to split it into two stages - create the table, and then populate it.
Unlike CTAS in which the schema is inherited from the<span class="inline-code">SELECT</span> , here we’re going to have to define the schema manually. We can get the schema from a <span class="inline-code">DESCRIBE</span> against the view:
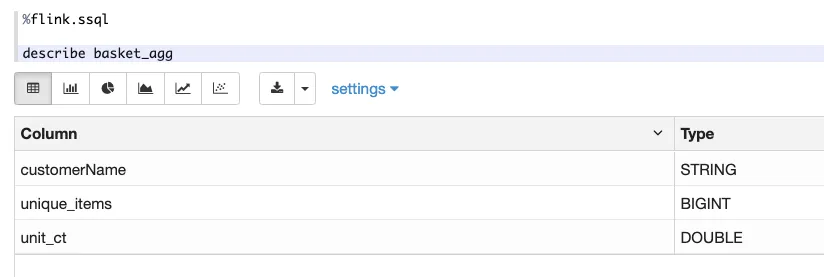
Copying this schema into our <span class="inline-code">CREATE TABLE</span> gives us this:

So now to populate it…maybe.

Ahhhh Java stack traces my old friend. How I’ve missed you.

The one we’ve got here boils down to this:
I’ve encountered this error previously. It means that the Flink installation only has a certain set of connectors installed, and not the one we want. The error message actually tells us which ones are available:
So how do we write to Iceberg? We need to install the Iceberg connector, obviously! The MSF docs explain how to do this. In essence, I need to put the Iceberg JAR in an S3 bucket, and restart the notebook with the dependency added.
Let’s grab the Iceberg JAR for Flink 1.15 (wanna know more about navigating JAR-hell? You’ll enjoy this blog that I wrote) and upload it to S3:
Now to add it as a custom connector:
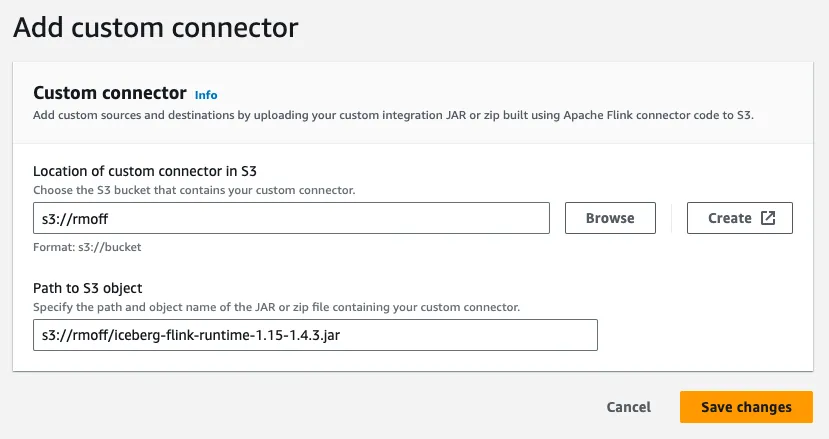
Unfortunately, MSF wasn’t happy with this. When I click on Create Studio notebook it fails after a minute or two with this:
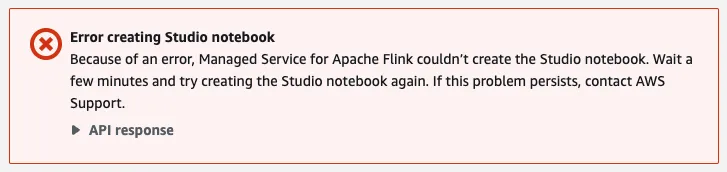
Ho hum. Since it says “please check the role” I went back a couple of screens to review the notebook’s configuration for IAM, which shows this:
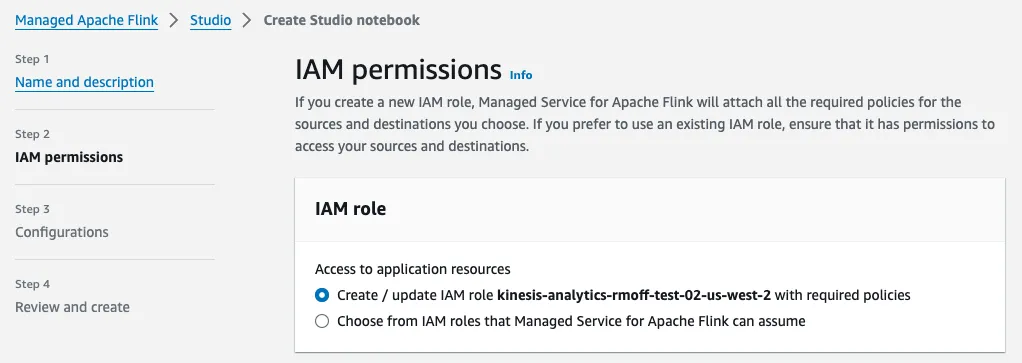
The IAM role is being created automagically, so things ought to Just Work? Right?

So down the rabbit hole we go to the IAM policy editor. Looking up the permissions attached to the policy that MSF created shows, after a bit of scratching around, the problem:
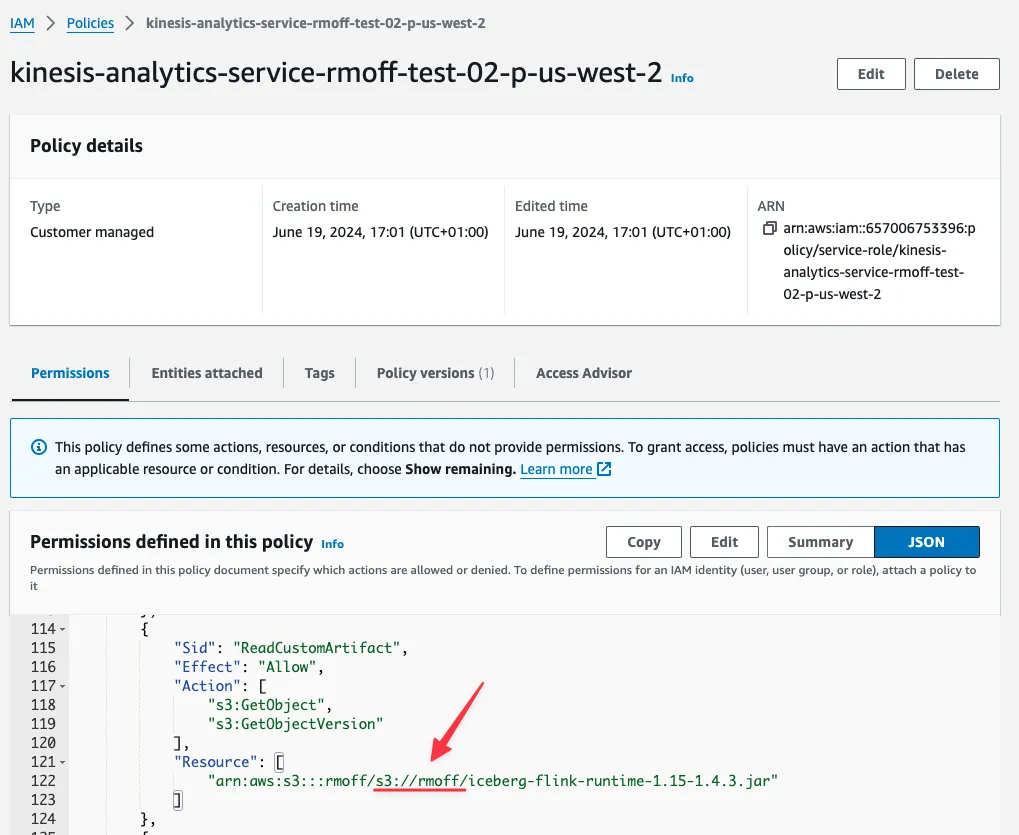
The problem wasn’t actually the IAM that MSF provisioned, but the information with which it did so.
When I specified the Path to S3 Object I gave the fully qualified S3 URL,<span class="inline-code">s3://rmoff/iceberg-flink-runtime-1.15-1.4.3.jar</span> . What MSF wanted was the path within the S3 bucket that I’d also specified (<span class="inline-code">s3://rmoff</span> ). What this ended up with was MSF concatenating the two and configuring IAM for a JAR file at<span class="inline-code">s3://rmoff/s3://rmoff/iceberg-flink-runtime-1.15-1.4.3.jar</span>. This is also confirmed if I go back to the connector configuration screen and look closely at the S3 URI shown as a result of my erroneous input:
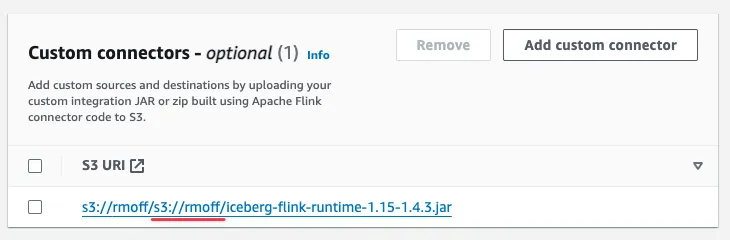
So, let’s remove that connector and re-add it with the correct path this time:
I can also click on the hyperlink to confirm that the object is there:
Having some guard rails provided by input validation would have been a nice touch here, but it wasn’t to be.
So. Back to starting the notebook up again.

Woohoo! Let’s go open that notebook and get back to where we were at before this irritating detour, and now hopefully with Iceberg superpowers 🦸. Because we’ve got the Glue catalog storing our table definitions, we should be able to pick up where we left off. This time we get a different error when we try to write to the Iceberg sink—progress!

To be honest, I wasn’t expecting creating an Iceberg connection to be quite as simple as what I tried:
So now onto the fun and fame of working out the correct parameters. The complication here—and the reason I can’t just copy and paste like any good developer reading StackOverflow—is that on MSF the catalog is provided by Glue, not Hive. The MSF documentation on connectors outside Kinesis and Kafka is pretty sparse, and there’s nothing for Iceberg that I could find. The documentation for Apache Iceberg’s Flink connector lists the properties required, and after a bit of poking around there I found this section about using it with a Glue catalog. There’s also this section on using Iceberg from Amazon EMR—which is not the same as MSF, but perhaps has the same pattern of access for Glue and S3 when writing Iceberg data. One point to note here is that the EMR document talks about creating Flink <span class="inline-code">CATALOG</span> objects—I’d recommend you review my primer on catalogs in Flink too if you haven’t already, since it’s an area full of ambiguity and overloaded terms.
Distilling down the above resources, I tried this configuration for the table next:
Here <span class="inline-code">catalog-name</span> matches my Glue catalog name. When I try to insert into it, I get a different error: <span class="inline-code">java.lang.ClassNotFoundException: org.apache.hadoop.hdfs.HdfsConfiguration</span>.
I mean, we’re only this far in and haven’t had a <span class="inline-code">ClassNotFoundException</span> yet…I think we’re doing pretty well 🤷? My impression of MSF is feeling like the trials and tribulations of learning Apache Flink running locally, but with one arm tied behind my back as I try to debug a system running a version of Flink that’s two years old and with no filesystem access to check things like JARs.
Back to our story. I spent a bunch of time learning about JARs in Flink so was happy taking on this error. <span class="inline-code">ClassNotFoundException</span> means that Flink can’t find a Java class that it needs. It’s usually solved by providing a JAR that includes the class and/or sorting out things like classpaths so that the JAR can be found. Searching a local Hadoop installation (remember those?) turned up this:
But now I’m a bit puzzled. We’re hoping to write to S3, so why does it need an HDFS dependency?
On a slight tangent, and taking a look at the table DDL I’m running, it’s using the Flink Iceberg connector as described here to directly create a table, sidestepping the explicit Iceberg catalog creation usually seen in examples. Let’s try creating a catalog as seen here:
But, same error:<span class="inline-code">java.lang.ClassNotFoundException: org.apache.hadoop.hdfs.HdfsConfiguration</span> .
Looking at the Iceberg docs again it seems I’ve perhaps missed a dependency, so back to creating a new notebook, this time with <span class="inline-code">hadoop-aws</span> and <span class="inline-code">iceberg-aws-bundle</span> added. I’d wanted to include <span class="inline-code">aws-java-sdk-bundle</span> since I’ve needed that when running things locally, but I guess that one wasn’t to be:
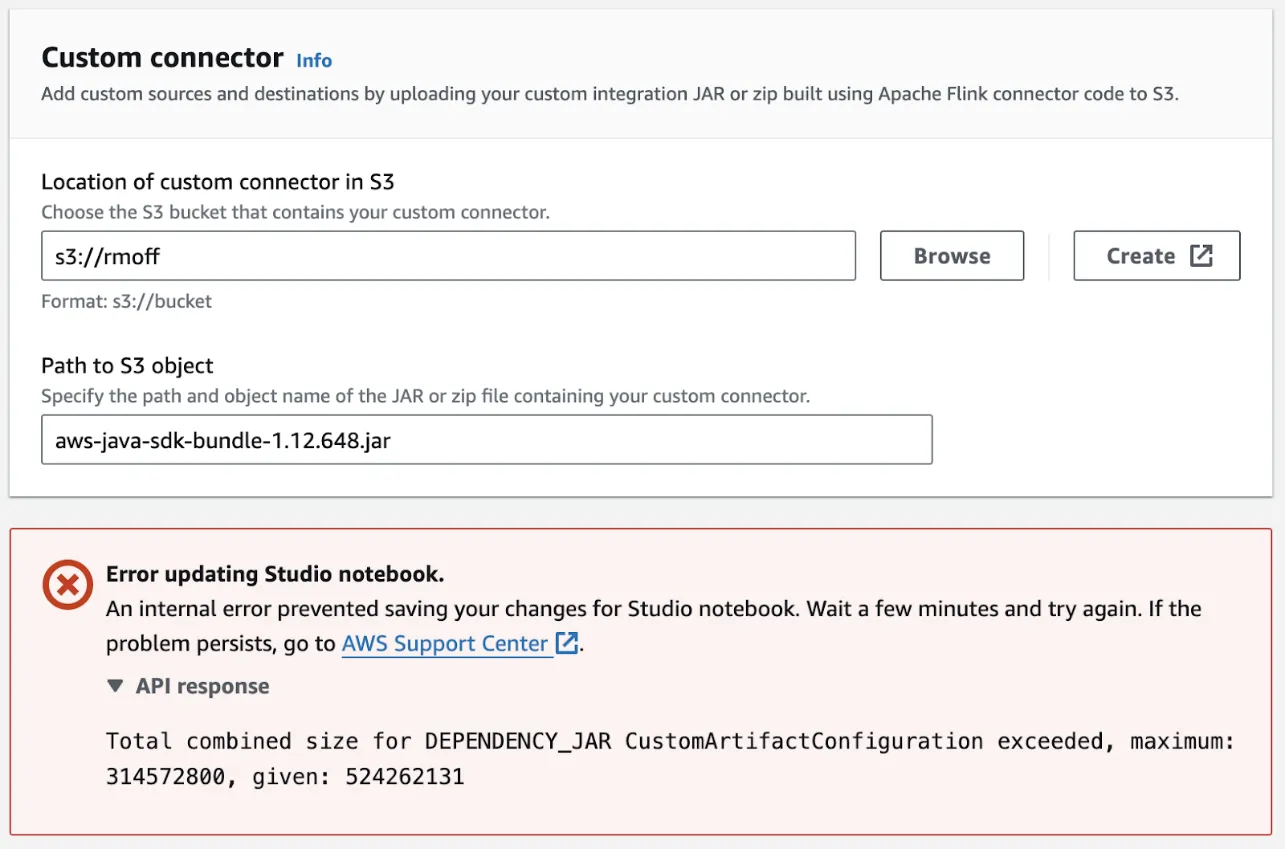
So this is what I’ve got for this notebook’s attempt:
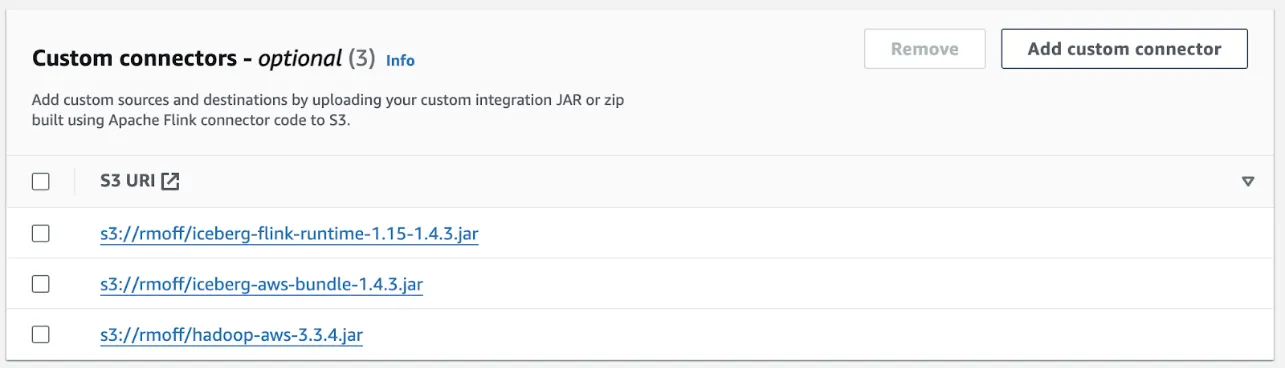
Still no dice—same error:<span class="inline-code">java.lang.ClassNotFoundException: org.apache.hadoop.hdfs.HdfsConfiguration</span>. Let’s take the bull by the horns and add the specific JAR file that contains this (<span class="inline-code">hadoop-hdfs-client</span>):
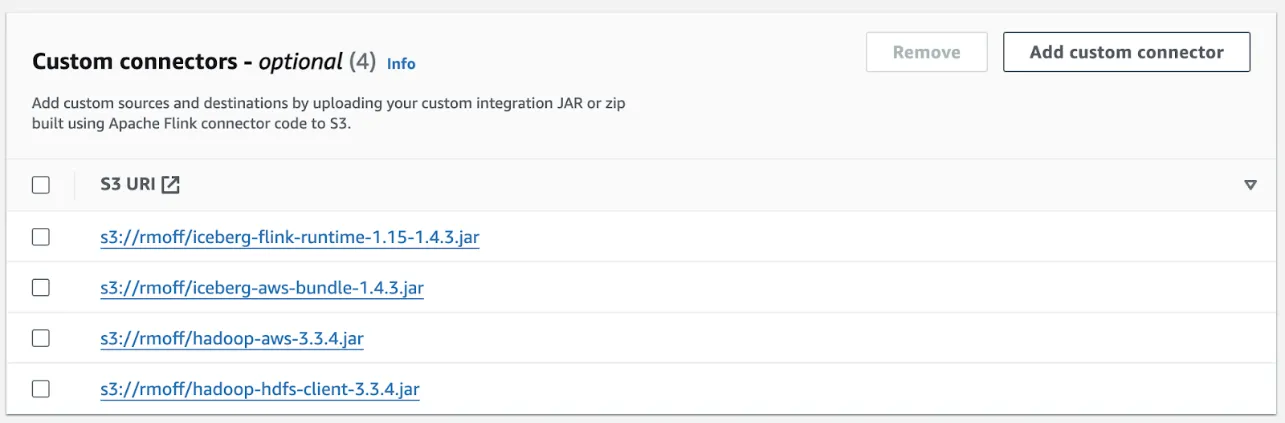
After restarting the notebook I can see the JARs picked up in Zeppelin’s <span class="inline-code">flink.execution.jars</span> :
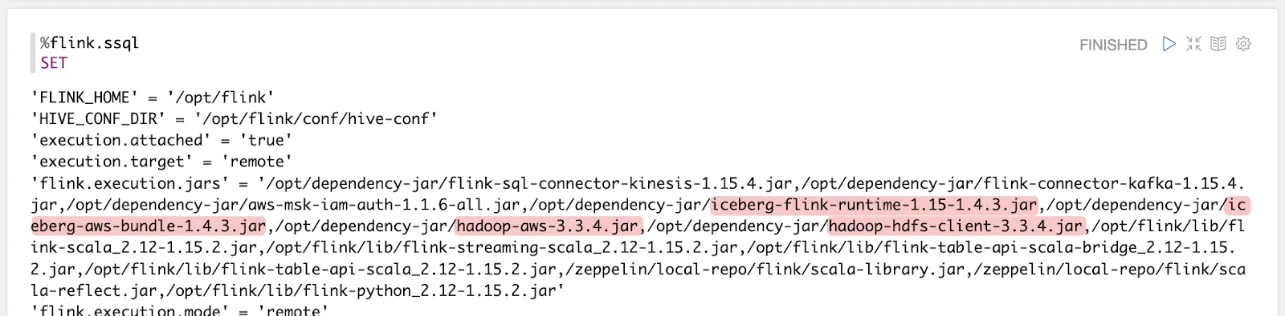
But… still… when I try to create an Iceberg catalog as above, the… same… error…<span class="inline-code">java.lang.ClassNotFoundException: org.apache.hadoop.hdfs.HdfsConfiguration</span>.

So what am I going to do? What any sensible data engineer given half the chance would at this point…give up and try something different. Instead of writing to Iceberg on S3, we’ll compromise and simply write parquet files to S3. This should hopefully be easier since the Flink filesystem connector is one of the connectors that is included with MSF.
Attempting to write Parquet files to S3 from Amazon MSF…
This should be much simpler:
But simple is boring, right?
Up and over to the dependencies again, since we need to add the necessary JAR for parquet format.
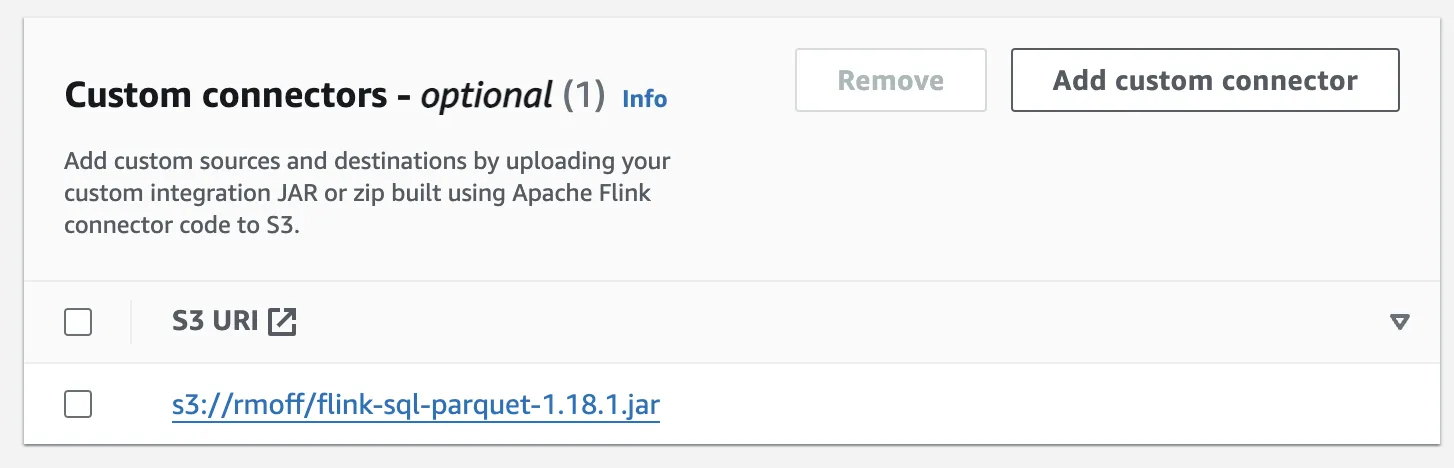
But can you spot what might be the problem?
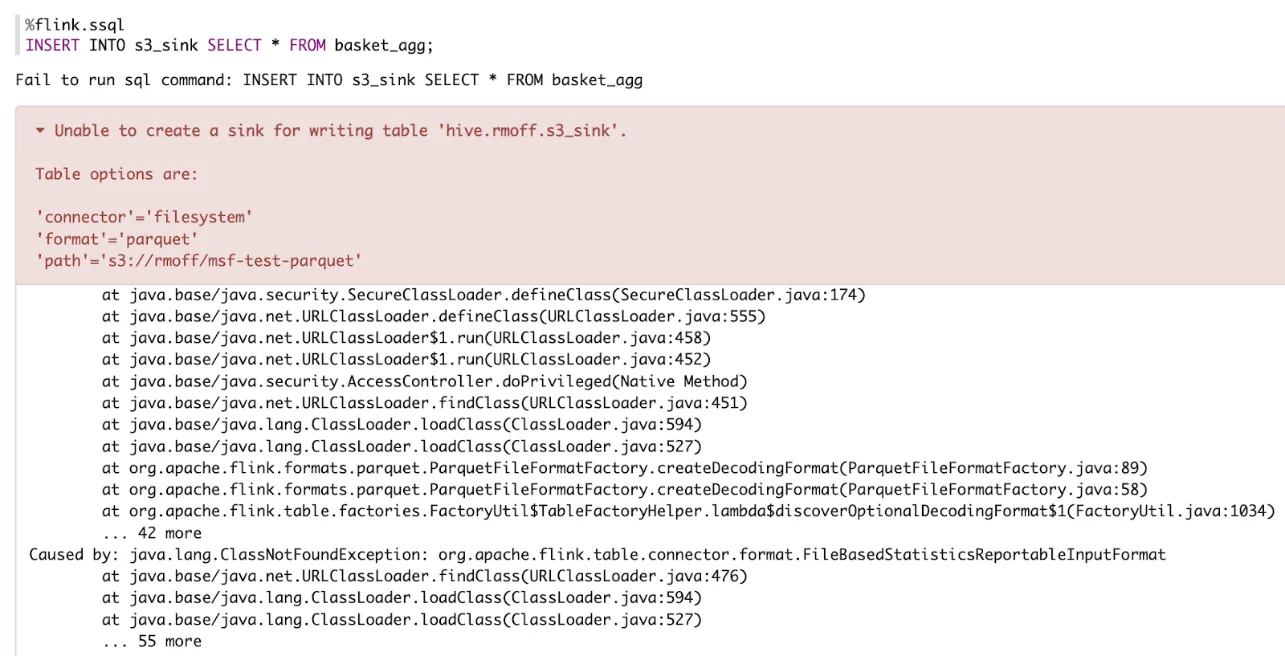
I’d picked up the JAR for Flink 1.18.1—and MSF is running Flink 1.15. I don’t know for certain that the version difference is the problem, but from experience aligning versions is one of the first things to do when troubleshooting.
So, stop the notebook, update the JAR (it’s called “Custom Connectors” in the UI, but it seems to encompass any dependencies), start the notebook… and progress (of sorts):
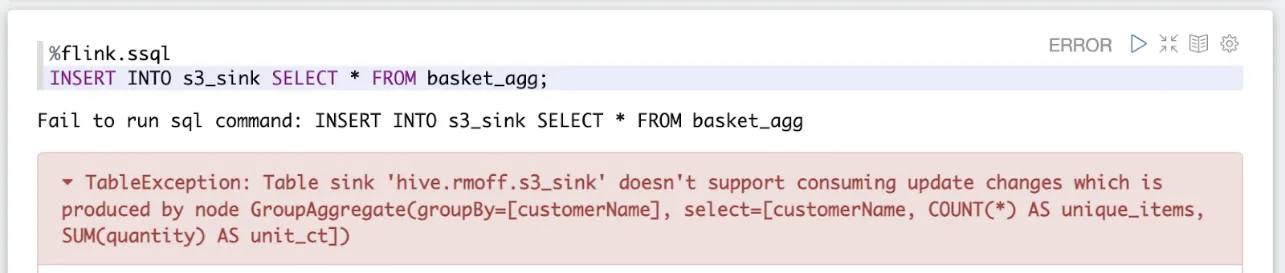
Of course…we’ve created an aggregate, and we’re trying to write it to a file type which doesn’t support updates. Parquet is append-only, so as the aggregate values change for a given key, how can we represent that in the file?
So that we’ve not completely failed to build an end-to-end pipeline I’m going to shift the goalposts and change the aggregate to a filter, selecting all customers from the Kafka source whose names begin with the letter “b”:
Now let’s write the filtered data to Parquet on S3:
This works! For ten glorious seconds! And then…
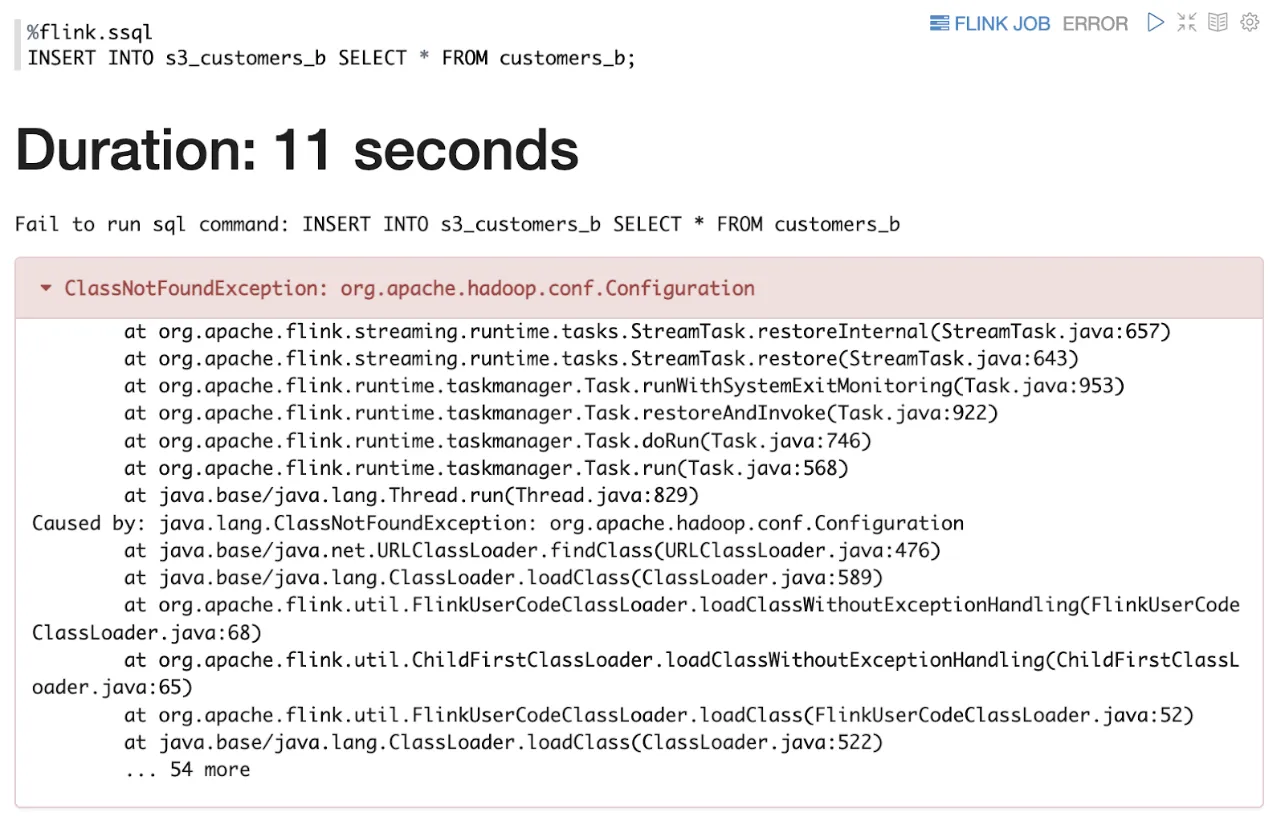
A couple of StackOverflow answers suggest that even with the Parquet JAR I still need some Hadoop dependencies. So back to the familiar pattern:
- Close the notebook
- Force stop the notebook (it’s quicker, and I don’t care about data at this point)
- Wait for the force stop to complete
- Add hadoop-common-3.3.4.jar to the list of Custom connectors for the notebook
- Wait for the notebook to update
- ‘Run’ (start) the notebook
- Wait for the start to complete
- Open the notebook
- Rerun the failing statement
Unfortunately I’m now just off down the same whack-a-mole route as I was with Iceberg, this time with<span class="inline-code">java.lang.ClassNotFoundException: com.ctc.wstx.io.InputBootstrapper</span> :
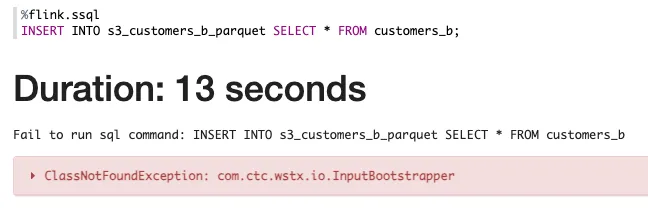
Even after adding <span class="inline-code">hadoop-client-runtime-3.3.4.jar</span>, I get the same error. So now I’m wondering about the versions. What version of Hadoop dependencies is Flink 1.15 going to want? I failed to find anything in the Flink docs about versions, so instead went to Maven Repository and picked a Hadoop version based on the date that was fairly close to the release of Flink 1.15 (May 2022)—3.2.2.
This was the last roll of the dice…
Still no dice.

Writing CSV or JSON files to S3 from Amazon MSF
So now I’m going to fall back from Iceberg…to Parquet…to CSV…something…anything…
Here’s the CSV table and<span class="inline-code">INSERT</span>:
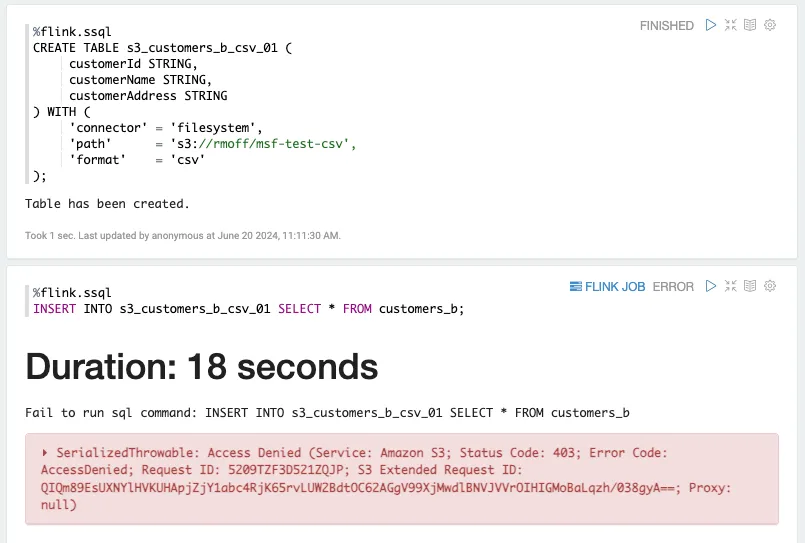
But hey—a different error 😃 And this one looks less JAR-related and probably more IAM.
This actually seems fair enough; looking at the IAM details from the AWS console, the IAM role that MSF automagically configures only has access on S3 to the three JARs that I uploaded when I was trying to get parquet to work:
I added a second policy just to try to get things to work for now. It’s very permissive, and overlaps with the <span class="inline-code">ReadCustomArtifact</span> one (which arguably is redundant anyway if we don’t need any of the parquet and dependency JARs):
Back to the notebook and things are finally looking hopeful:
Two minutes and no error yet! But also…no data yet:
Twiddling my thumbs and clicking around a bit I notice this little FLINK JOB icon appeared a short while after running the statement:
Clicking on it takes me to the vanilla Flink web dashboard:
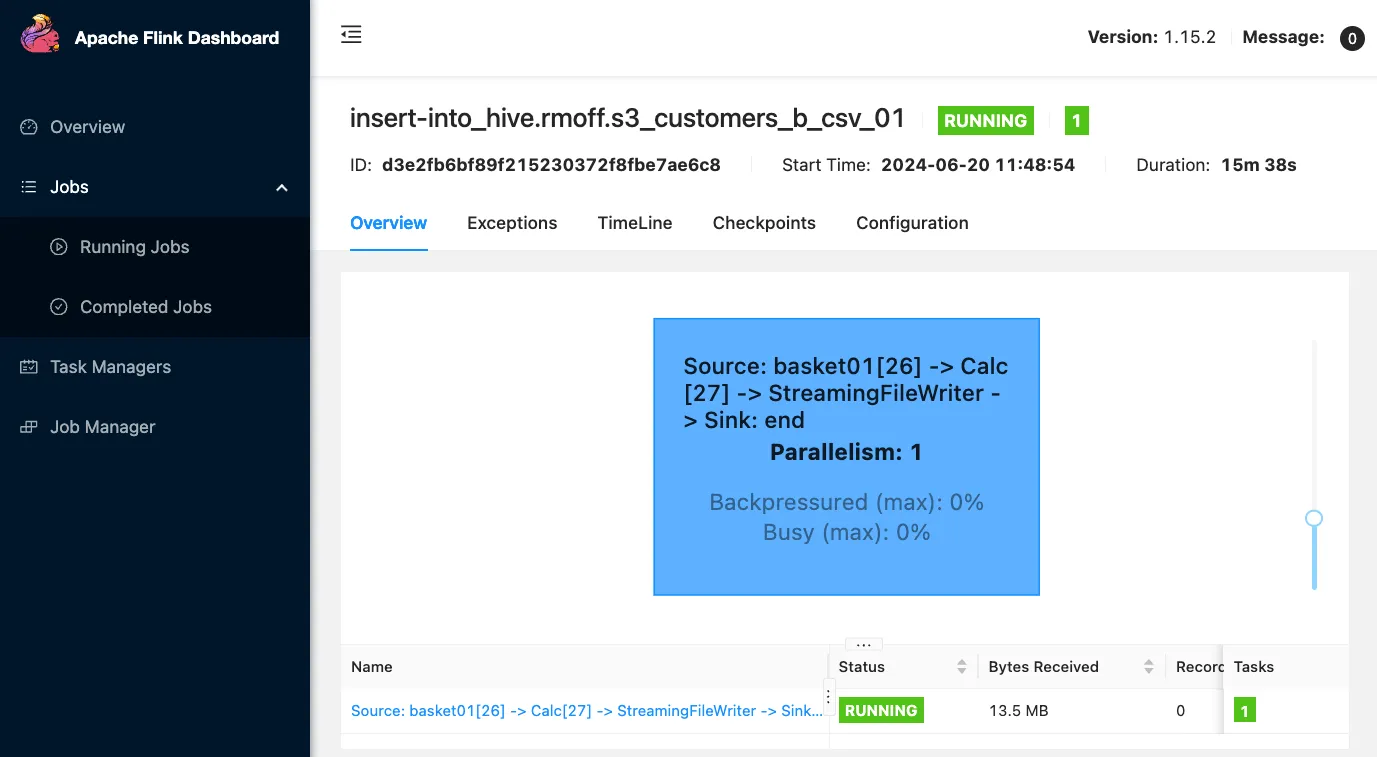
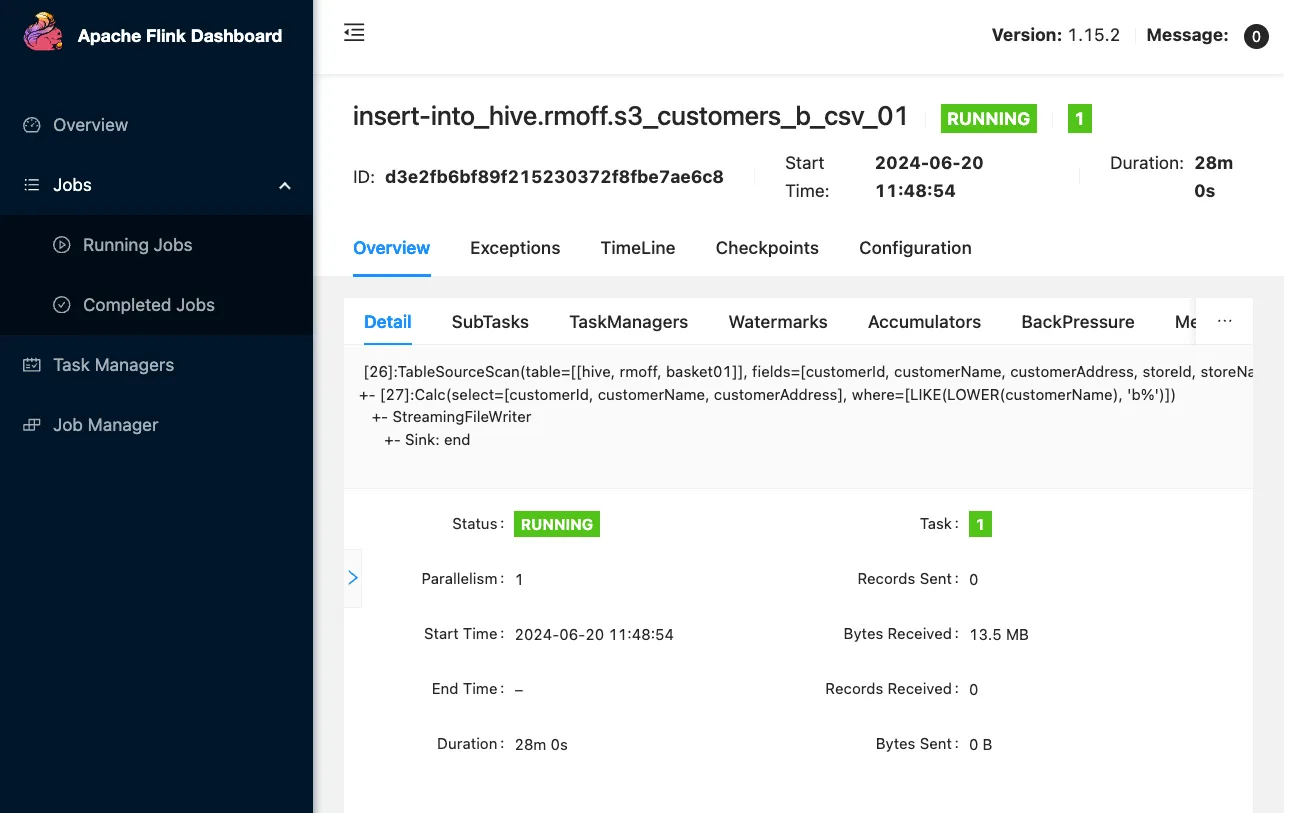
This is nice, but doesn’t help me with where my CSV files are. A bit more digging around leads me to the FileSystem documentation and specifically the section about when the part files are written. The <span class="inline-code">sink.rolling-policy.rollover-interval</span> defaults to 30 minutes. Sure enough, after 30 minutes (ish) something does happen:

Funnily enough, I’ve hit a very similar error previously, which then leads me to FLINK-28513. Unfortunately this is a bug from Flink 1.15 which has been fixed in 1.17 and later…but MSF is on 1.15, so we’re stuck with it.
Continuing our descent into oblivion of finding a file format—any file format!—to successfully write to S3, let’s try JSON:
I’ve also overridden the default <span class="inline-code">sink.rolling-policy.rollover-interval</span> to 30 seconds. If I understand the documentation correctly, then every 30 seconds Flink should start a new file to write to on disk.
Let’s try it!
After a break for tea, I came back to find the job still running (yay!)
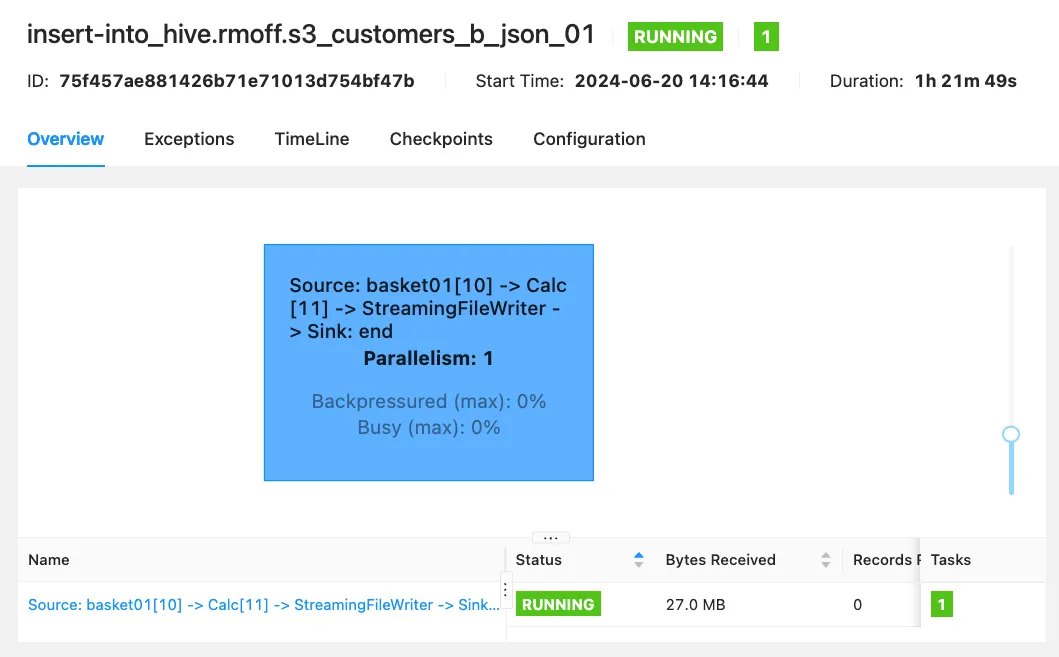
but no data on S3 (boo!)
The final piece of the puzzle that I’ve been missing is checkpointing. By default this is disabled, which can be seen here:

I can’t see a way to force a Flink SQL job to checkpoint, so canceled the <span class="inline-code">INSERT</span> and re-ran it with checkpointing enabled:
Ten seconds is pretty aggressive for checkpointing, but then I am pretty impatient when it comes to testing that something is working as I hope. And the good news is that eventually, mercifully, it has worked.

How frequently you set your checkpointing and file rolling policy depends on how many smaller files you want, and how soon you want to be able to read the data that’s being ingested. Ten seconds is almost certainly what you do not want—if you need the data that soon then you should be reading it from the Kafka topic directly.
📓 You can find the source for the notebook here.
Wrapping things up on MSF
Well, what a journey that was. We eventually got something working to prove out an end-to-end SQL pipeline. We had to make a bunch of compromises—including ditching the original requirement to aggregate the data—which in real life would be a lot more difficult to stomach, or would have more complicated workarounds. But we’ve got a notebook that defines a streaming pipeline. Yay us! The final step with something like this would be to run it as an application. Notebooks are great for exploration and experimentation, but now we have something that works and we don’t want to have to launch Zeppelin each time to run it.
Running an MSF notebook as an application
MSF has an option to deploy a notebook as a streaming application, although the list of caveats is somewhat daunting. The one which I’m stumbling on is this one:
we only support submitting a single job to Flink.
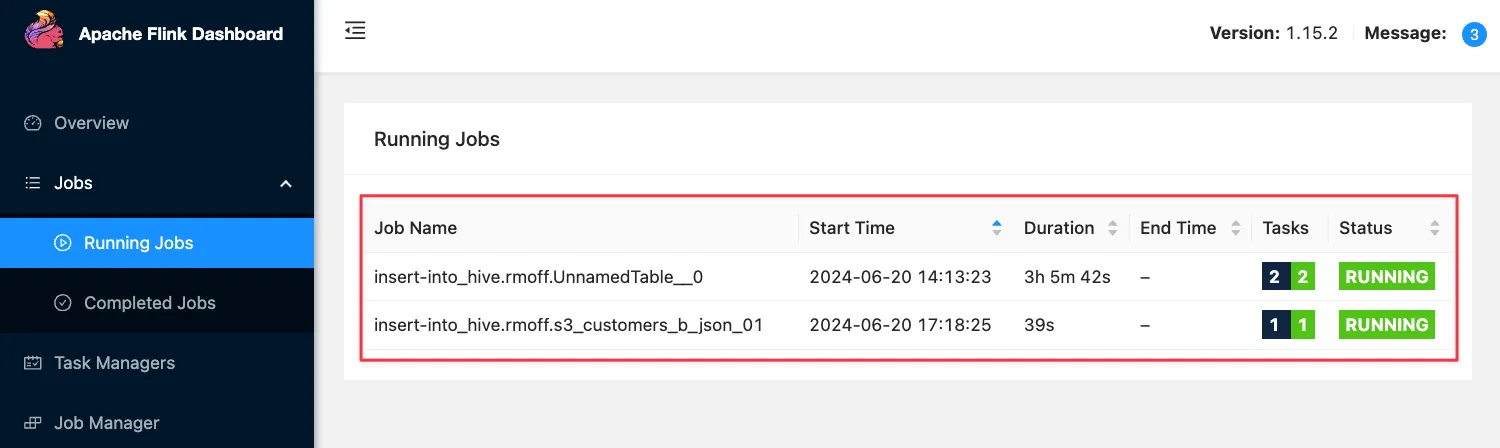
Looking at the Flink Dashboard I can see two jobs; the Kafka source, and the S3 sink:
Let’s give it a try anyway. After stopping the notebook from the console, there’s the option under Configuration for Deploy as application configuration which after putting my bucket name in looks like this:
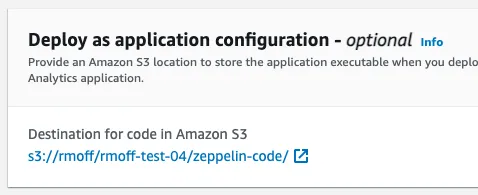
Now after clicking Run on the notebook it starts up again, and I figure it’s deployed it as an application? Maybe? But there’s nothing in the S3 bucket, and the notebook seems to just open as normal, so I’m a bit puzzled as to what’s going on.
It turns out that what’s not mentioned on the docs page itself—but is in a related tutorial—is that there are more steps to follow. First, build the application from the notebook:

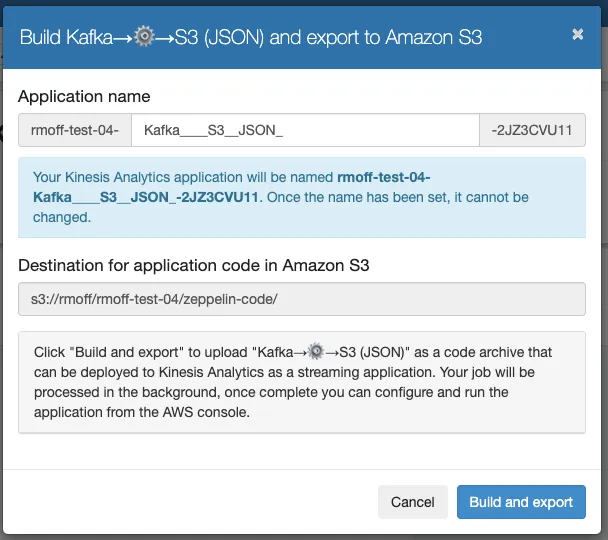
…but at this point it already has a problem.
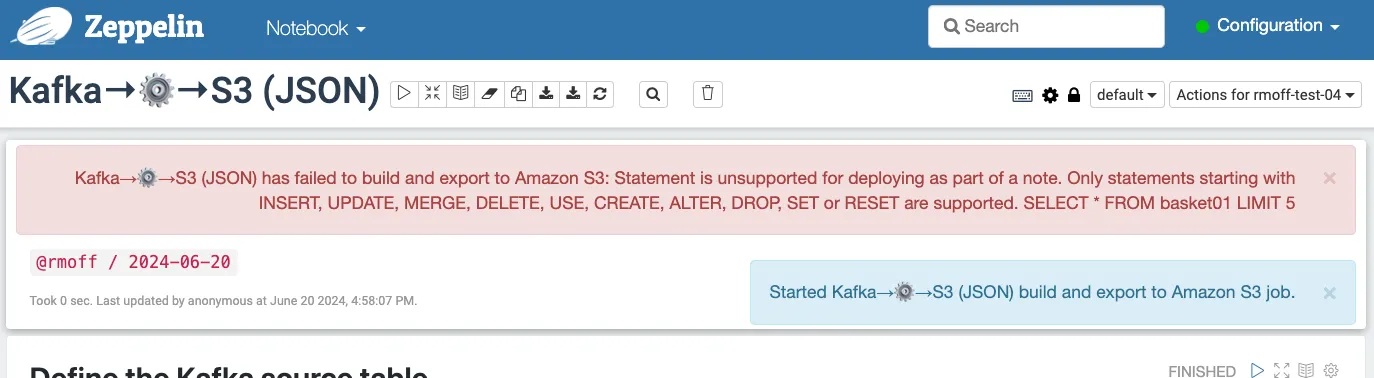
So, it looks like my notebook—in which I’ve done what one does in a notebook, namely to explore and iterate and evolve a data processing pipeline—is not ok as it is. I need to go back through it and trim it down to remove the interactive bits (the ones that made it useful as a notebook, really).
The Kafka source and S3 sink tables and the view that I’m using to filter the data for the sink are held in the Glue catalog:
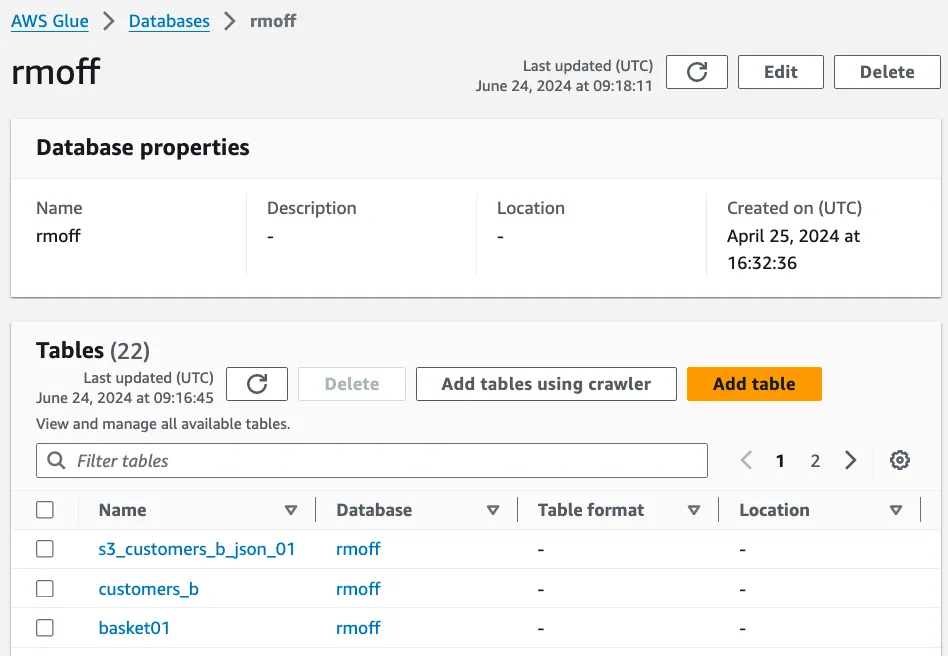
So all I need in my notebook now is the actual ‘application’—the <span class="inline-code">INSERT INTO</span> streaming SQL that connects them all together. I’ve stripped it back and saved it as a new note:
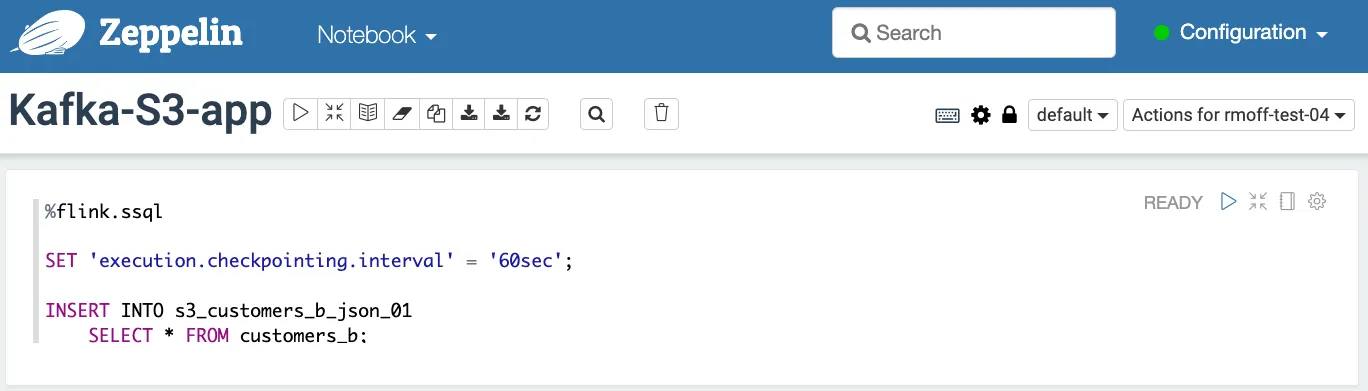
Now when I build it MSF is happy:

in my S3 bucket I can see code:
Being of a curious bent, I of course want to know how two SQL statements compile to an application of 400Mb, so download the ZIP file. Within a bunch of Python files is this one, <span class="inline-code">note.py</span>:
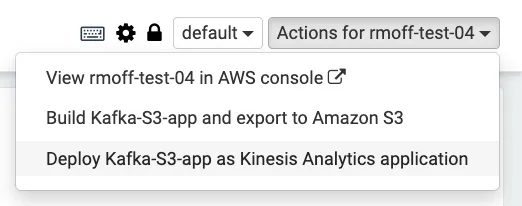
So with the note built into an application ZIP on S3, we can now deploy it. Somewhat confusingly for a product called Managed Service for Apache Flink, we’re now going to deploy the application as a “Kinesis Analytics” application—harking back to the previous name of the product.
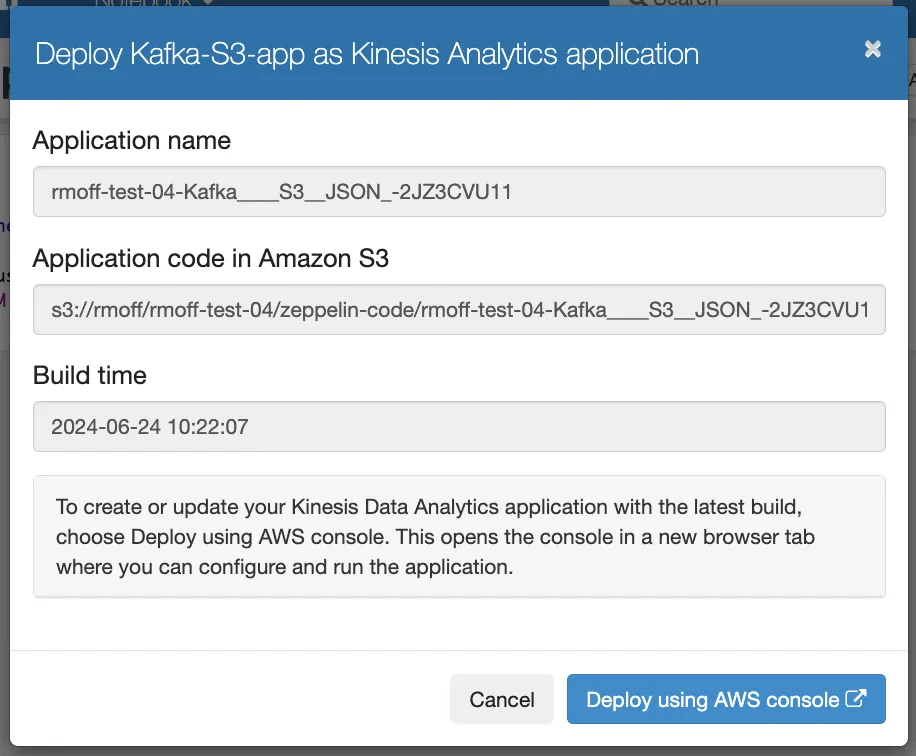
This isn’t a one-click deploy, but takes me through to the “Create streaming application” page of MSF with pre-populated fields.
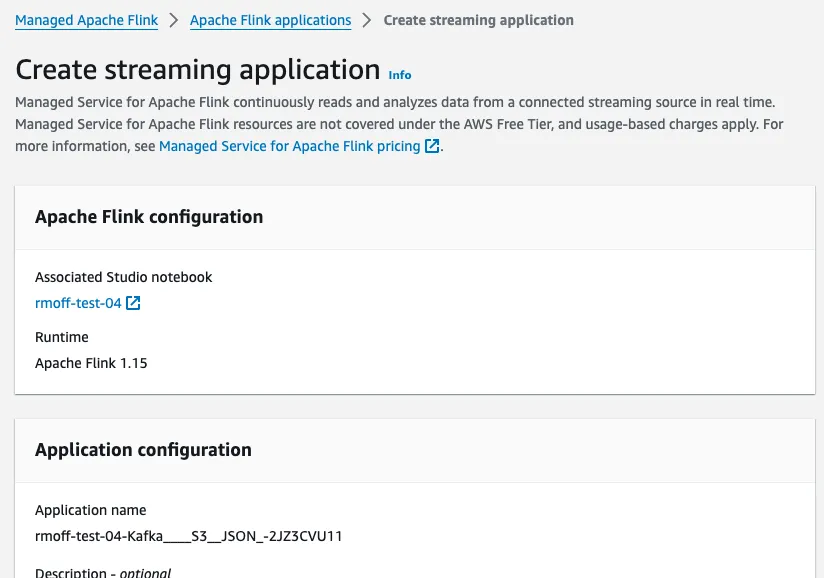
The next step is to click Create streaming application, which deploys the Python app that was built from our notebook.

Finally, we can Run our application:
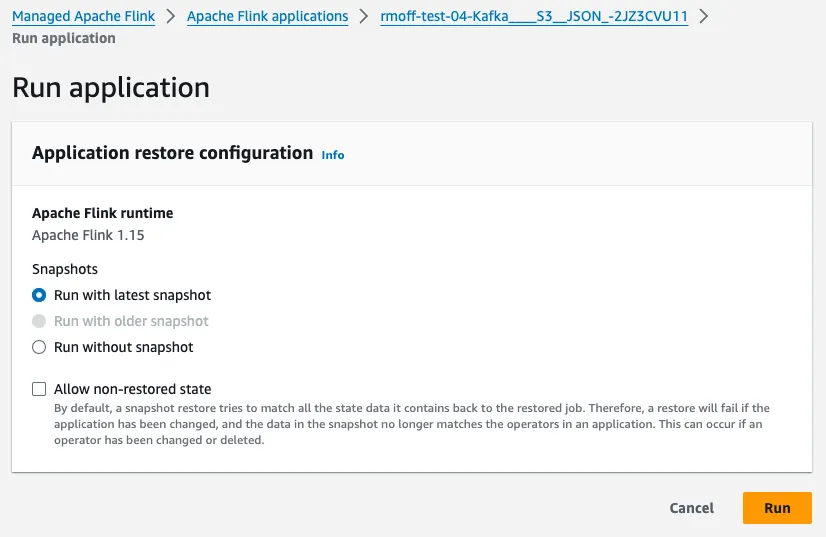
At this stage, in theory, we should see the records from our Kafka topic come rolling into the S3 buckets, filtered for only customers whose name begins with <span class="inline-code">b</span>…
The application is running:

But on the Flink dashboard that’s available with MSF applications, I don’t see any jobs:
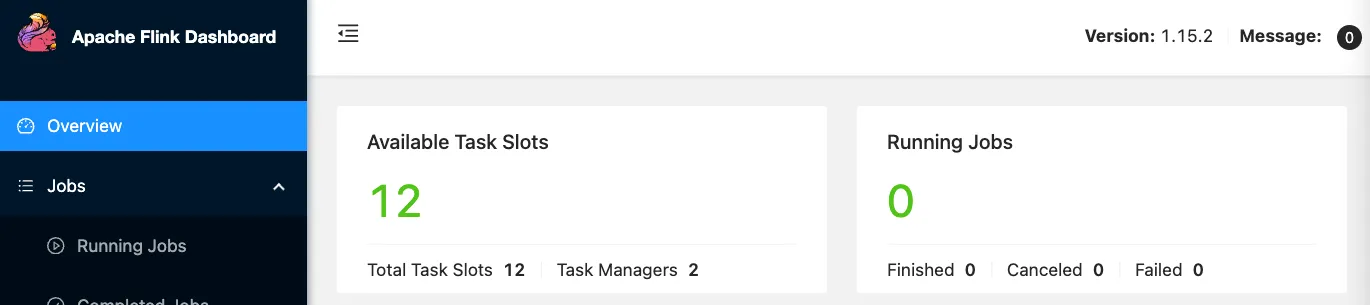
Looking closely at the MSF application dashboard I can see under Monitoring the Logs tab, so click on that—and there are some errors.
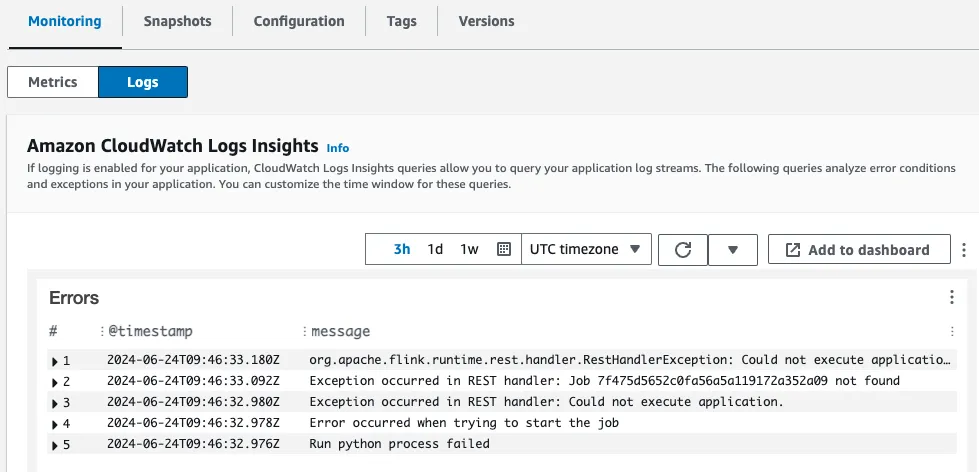
It looks like <span class="inline-code">Run python process failed</span> is the root error, and unfortunately there’s no detail as to why, other than<span class="inline-code">java.lang.RuntimeException: Python process exits with code: 1</span>.
At this point I YOLO’d out—getting some Flink SQL to work in the notebook was trouble enough, and deploying it as an application will need to be a job for another day…if ever.
The final and most important step in my MSF exploration was to stop the streaming application and the notebook, since both cost money (even if they are not processing data).
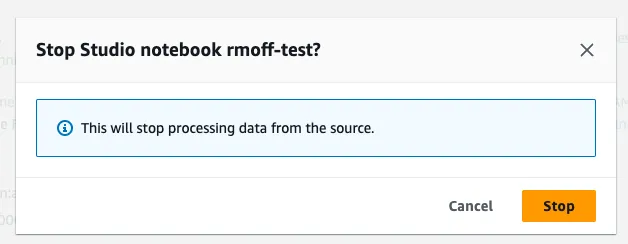
Phew…so that was Amazon MSF (neé Kinesis Analytics). What does it look like getting started with Flink SQL on Decodable?
Running Flink SQL on Decodable
Decodable is all about doing things the easy—but powerful—way. Not because you’re lazy; but because you’re smart. Where’s the business differentiation to be had in who can write more boilerplate Flink SQL? So things like connectors don’t even need SQL, they’re just built into the product as first class resources.
Reading data from Kafka with Decodable
From the home page of the product I’m going to connect to Kafka, and I’ll do it by clicking on the rather obvious “Connect to a source”:
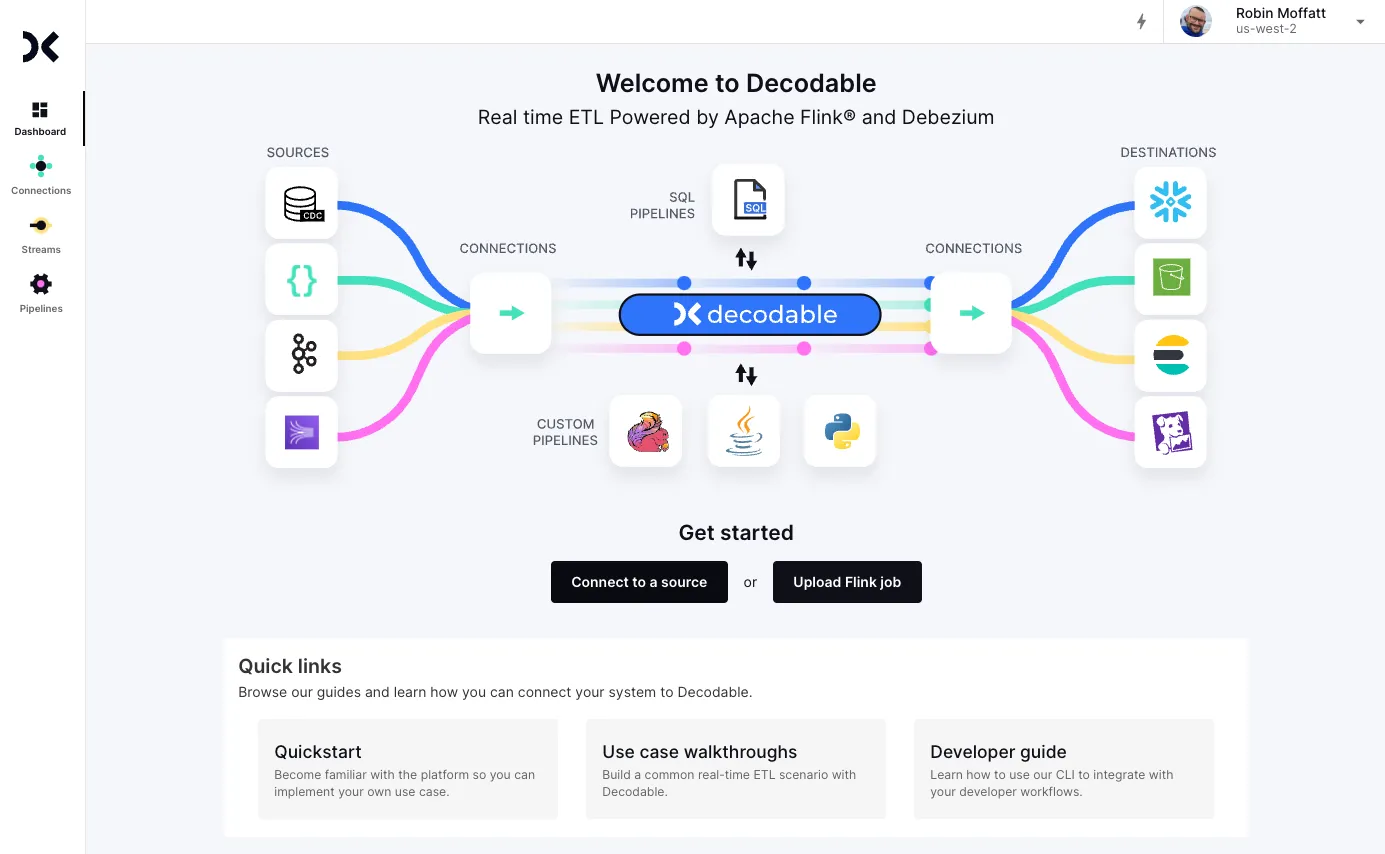
From the list of source connectors I click on the Kafka connector…
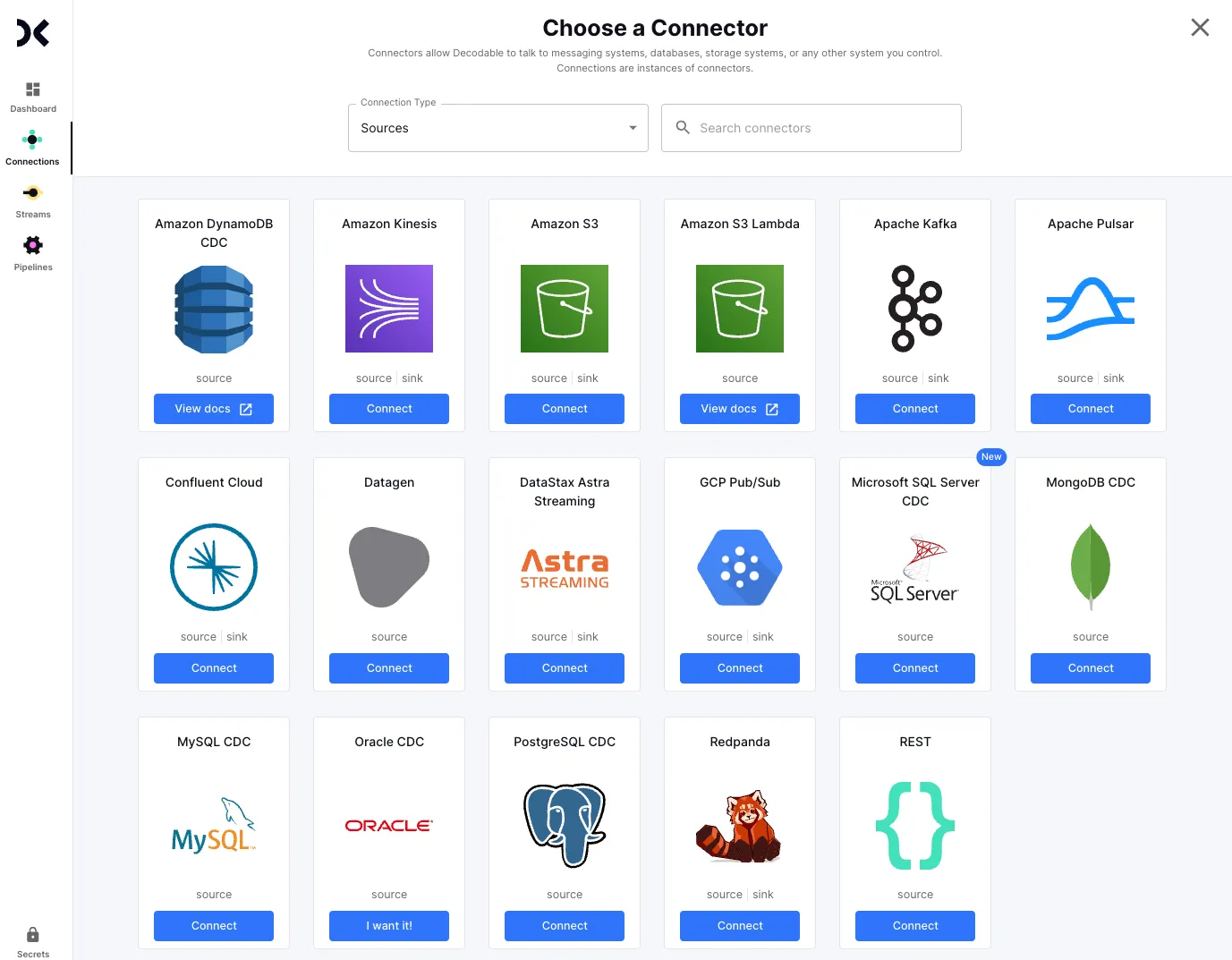
and configure the broker and topic details:
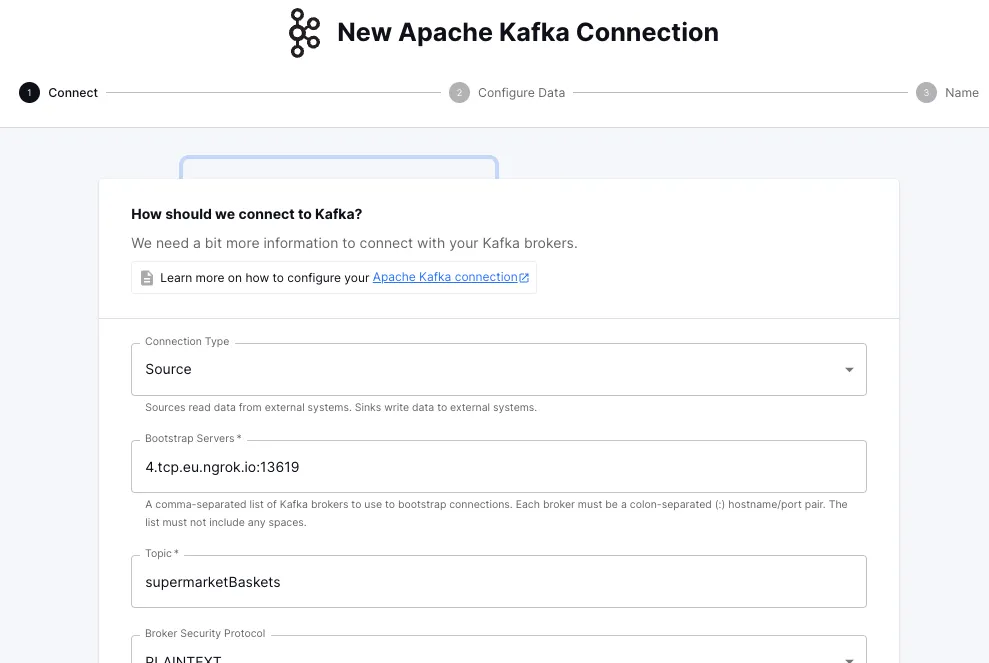
Next I need to give Decodable a destination for this data:
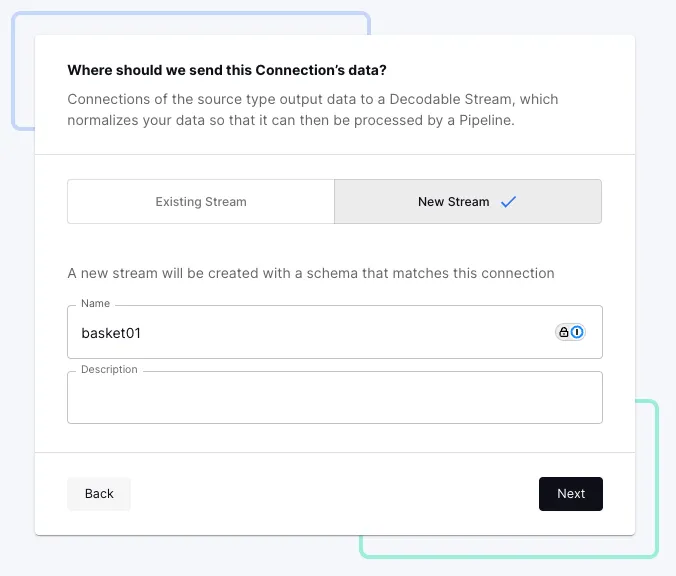
On the next screen I need to provide the schema. If I had a proper schema to hand I’d use it; for now I’ll take advantage of the schema inference and just give it a sample record:
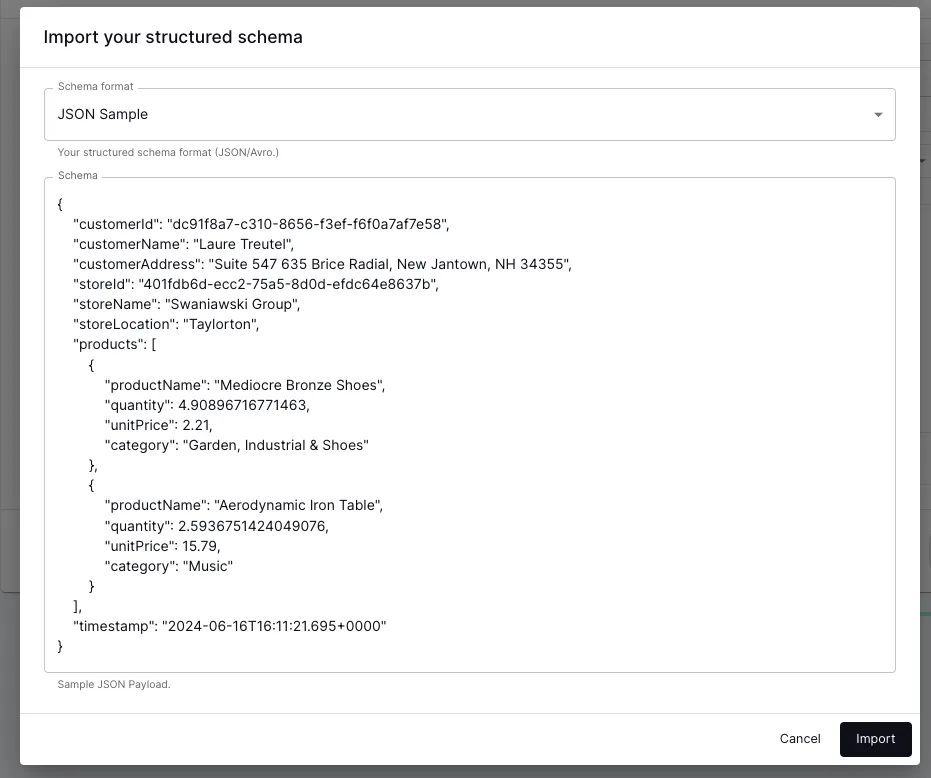
From this it picks up the schema automagically–I could further refine this if necessary, but it’s good for now:
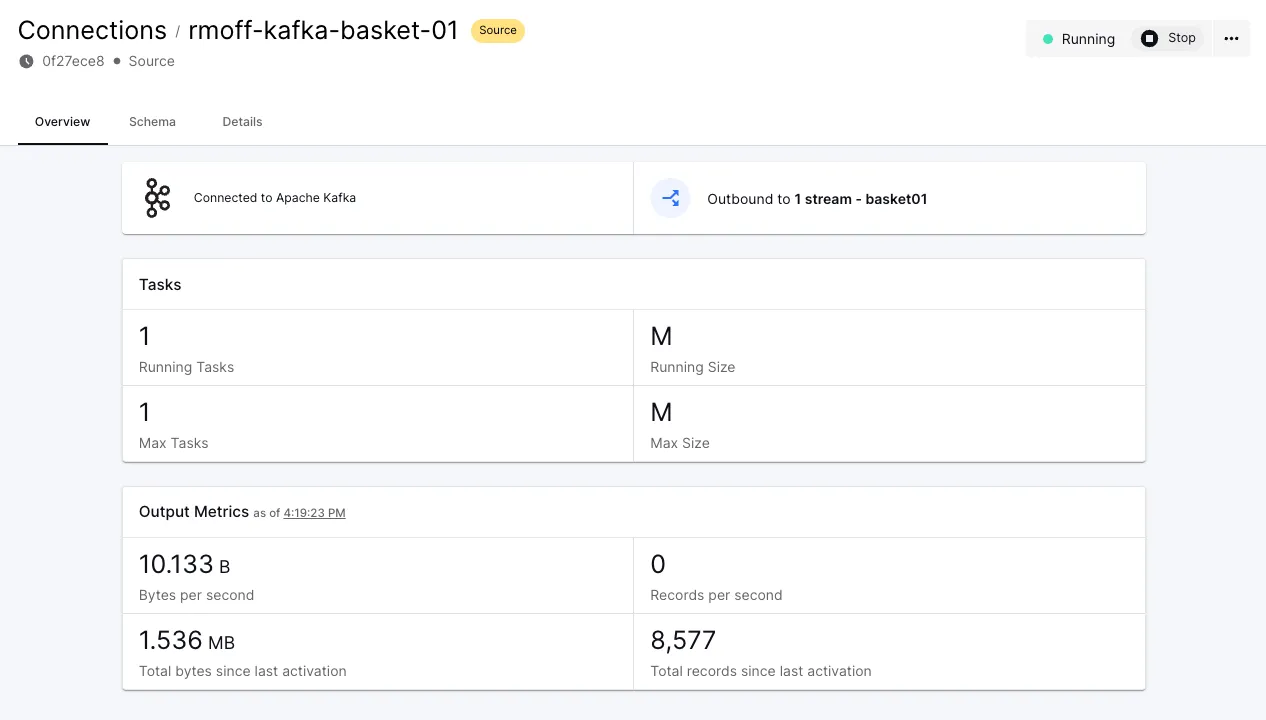
Once I’ve created the connection I click Start and shortly after the metrics screen confirms that data is being read successfully from Kafka.
Let’s check that we can indeed see this data by clicking on the stream that’s linked to from the connector page and using the preview feature:
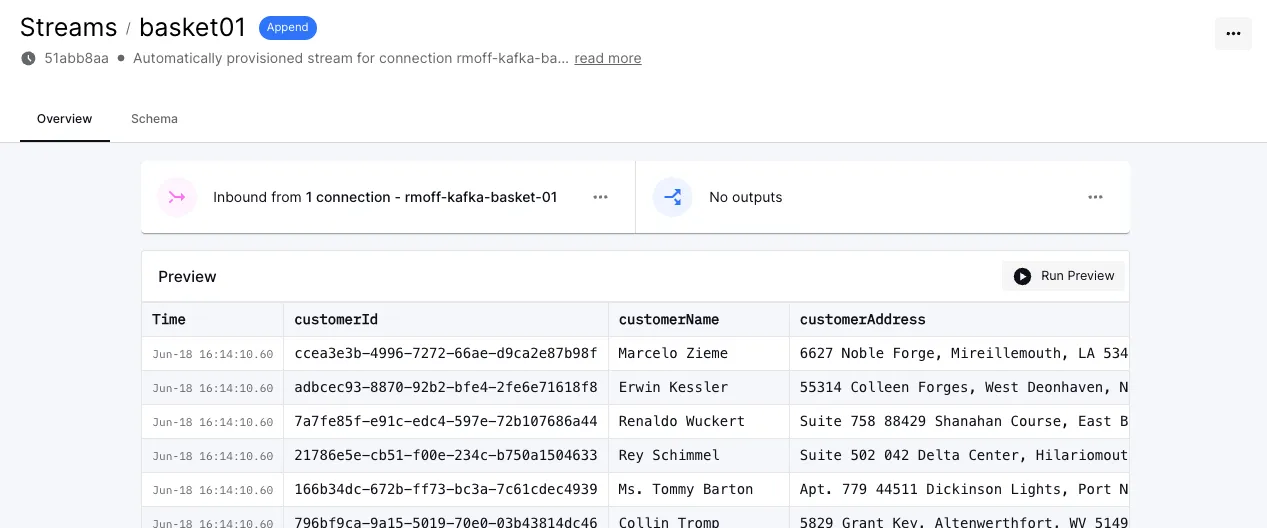
Looking good!
Let’s now look at the next bit of the pipeline; processing the data to create aggregates.
Flink SQL in Decodable
From the stream view of the data, I click on the Outputs and Create a pipeline
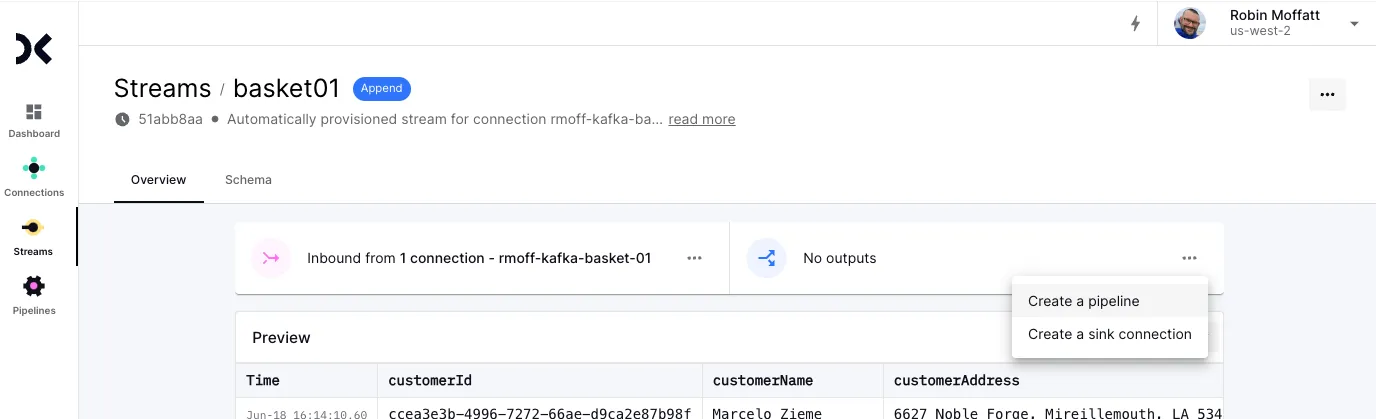
This takes me to a SQL editor. I’m using pretty much the same SQL as I did originally with MSF above. The preview is useful to make sure my SQL compiles and returns the expected data:
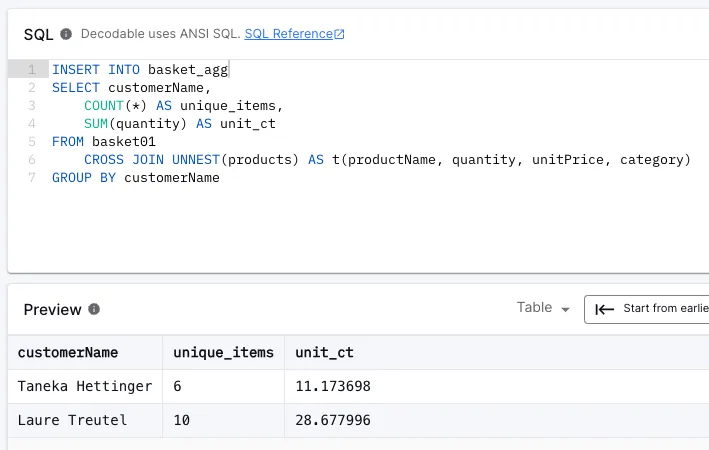
You may notice the <span class="inline-code">INSERT INTO</span> there too. This creates another stream which holds the continually-computed result of my query. As new records are sent to the Kafka topic, they’re read by Decodable, processed by my SQL pipeline, and the <span class="inline-code">basket_agg</span> stream updated. This is the stream that we’re going to send to Iceberg in the next section.
The final thing to do, since we want to use <span class="inline-code">customerName</span> as the primary key for the results (that is, the one by which the aggregate values are summarised), is use a <span class="inline-code">COALESCE</span> on <span class="inline-code">customerName</span> so that it is by definition a <span class="inline-code">NOT NULL</span> field. The final SQL looks like this:
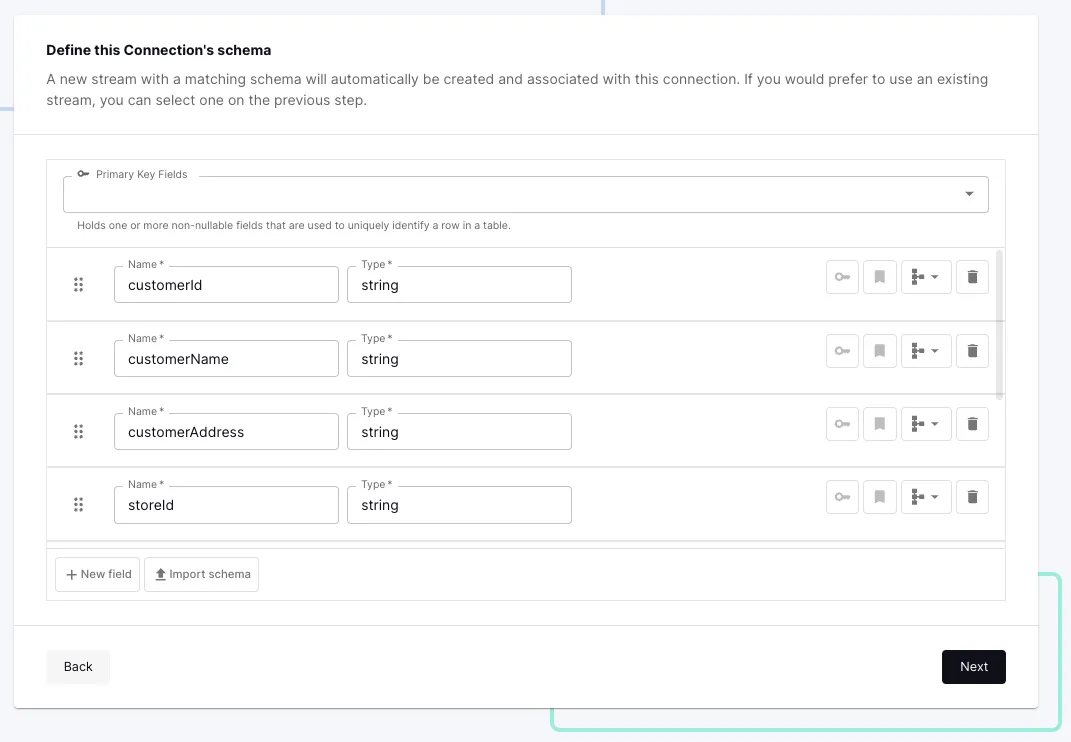
With the SQL created and tested, on the next screen we define the stream and set its primary key explicitly:
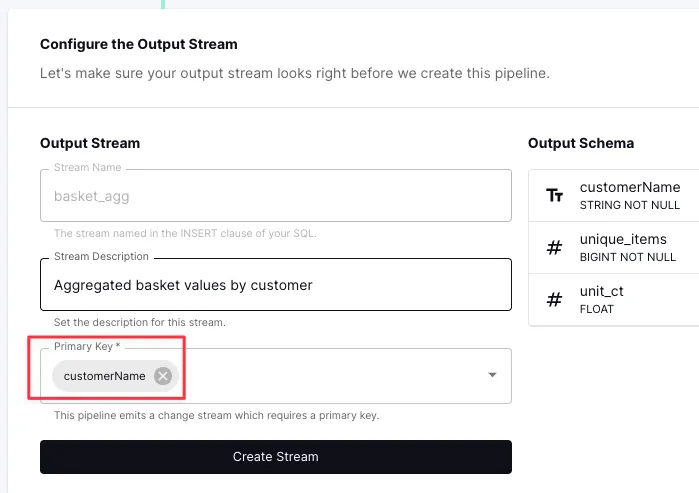
Finally, I’ll save the pipeline:
and then start it. Depending on the amount of data being processed and the complexity of the pipeline calculations, I could adjust the number and size of the tasks used for processing, but the defaults are fine for now:
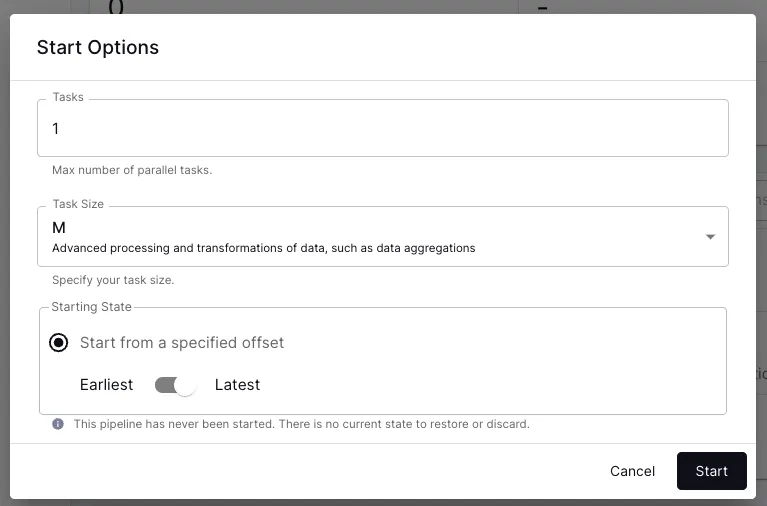
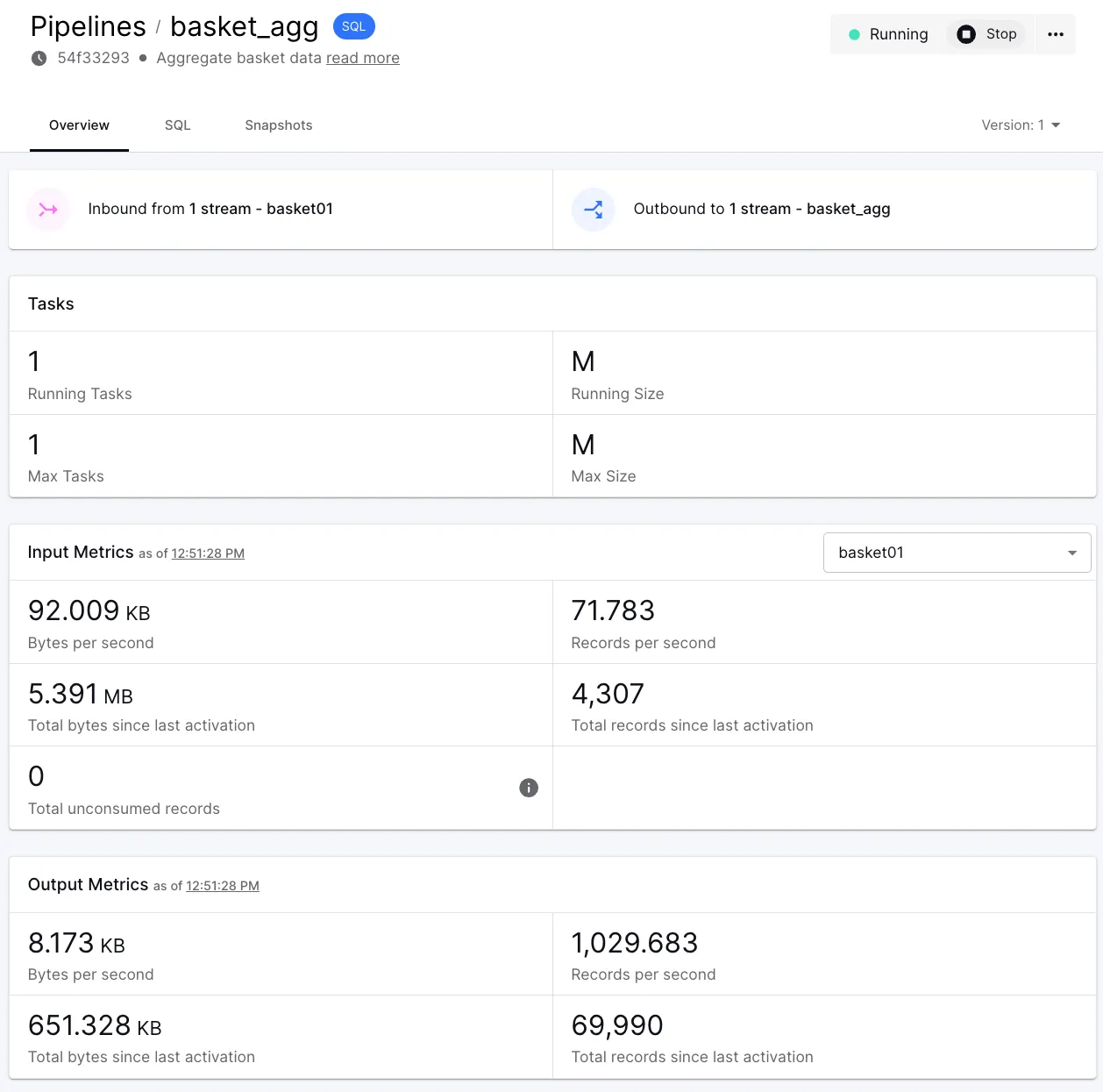
Now I can see data coming in from my Kafka source (<span class="inline-code">basket01</span>) and out to an aggregate stream (<span class="inline-code">basket_agg</span>):
Writing to Apache Iceberg from Decodable
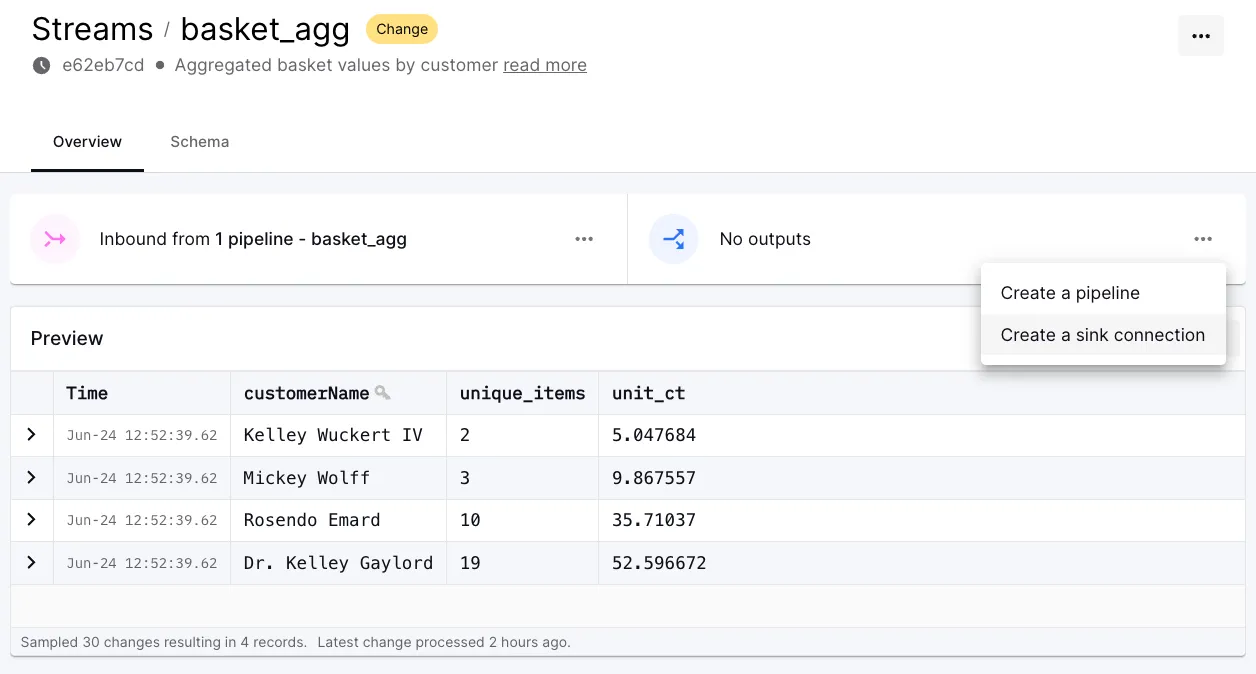
The final part here is to wire up our new stream, <span class="inline-code">basket_agg</span>, to the Apache Iceberg sink. From the stream we can directly add a sink connection:
Then it’s just a matter of entering the type of catalog (AWS Glue), table details, and an IAM role with the necessary permissions:
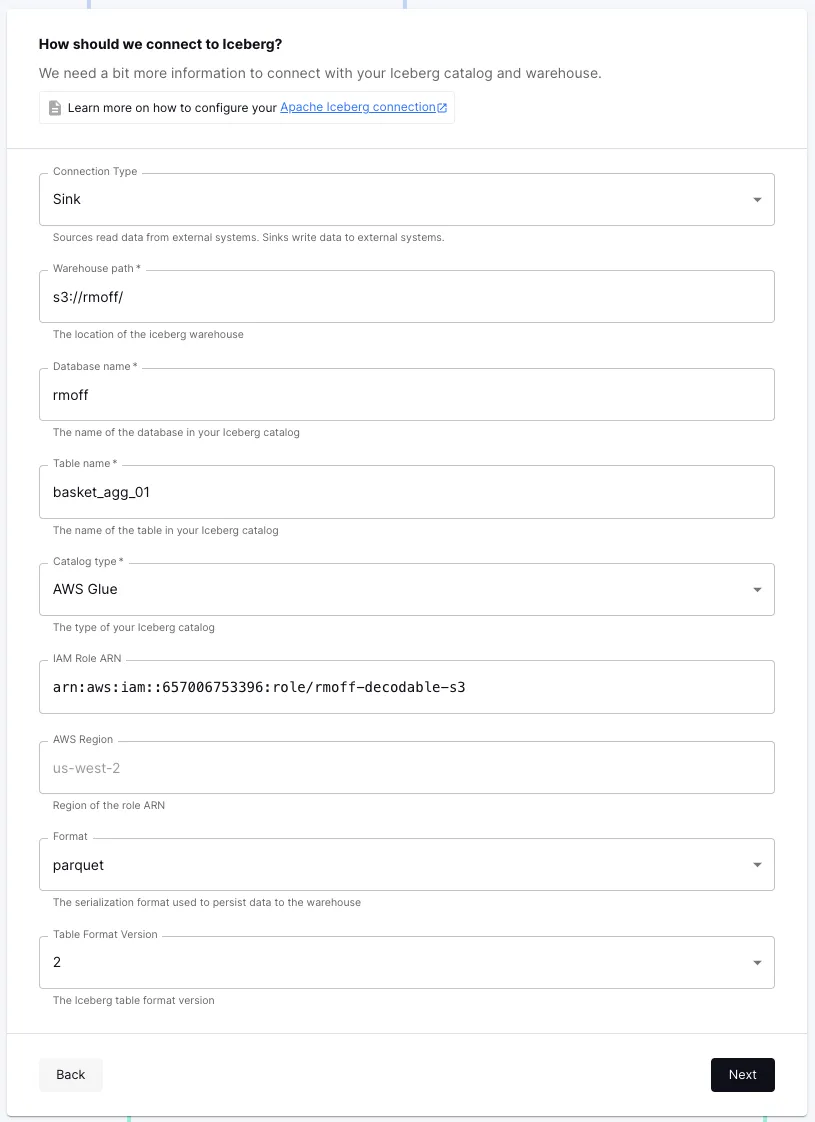
Finally, save the connection
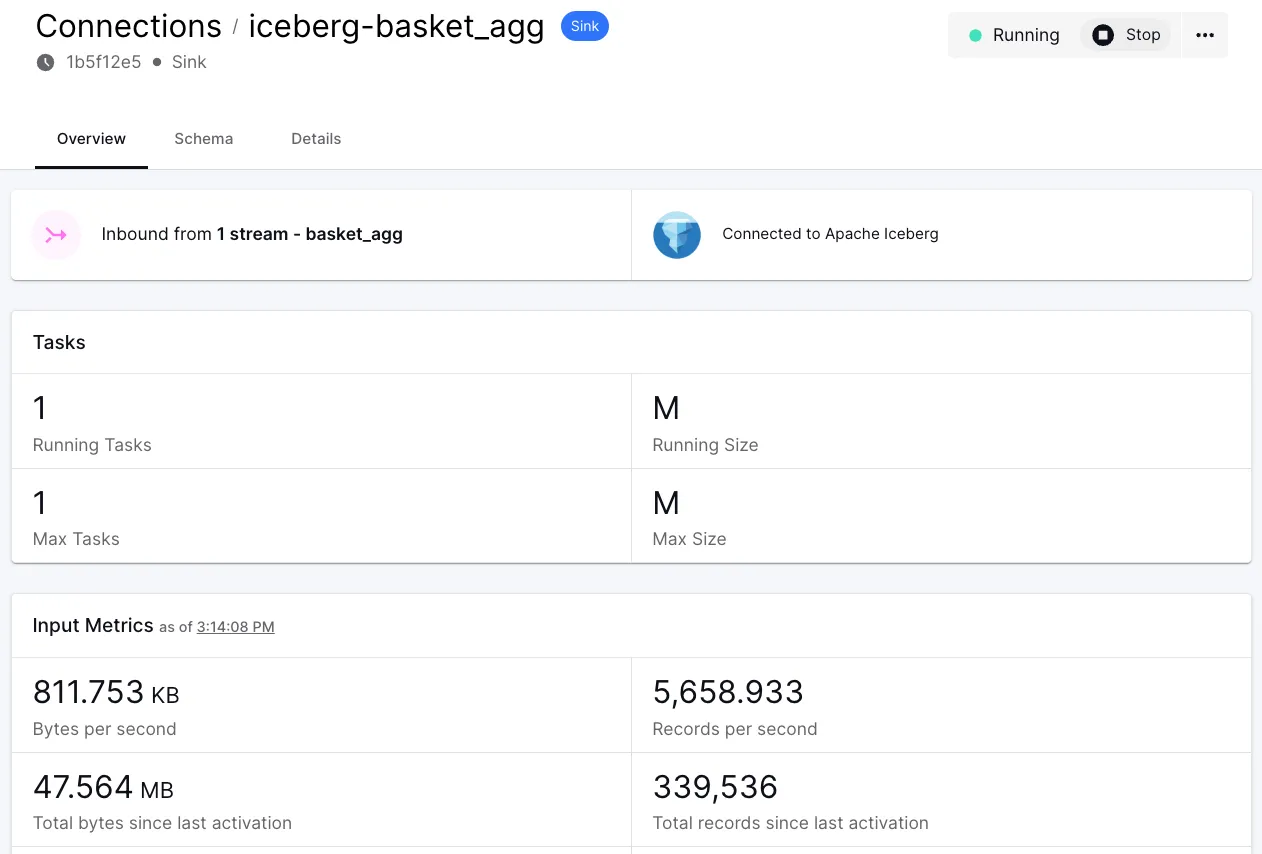
and start it. With that, we’re up and running!
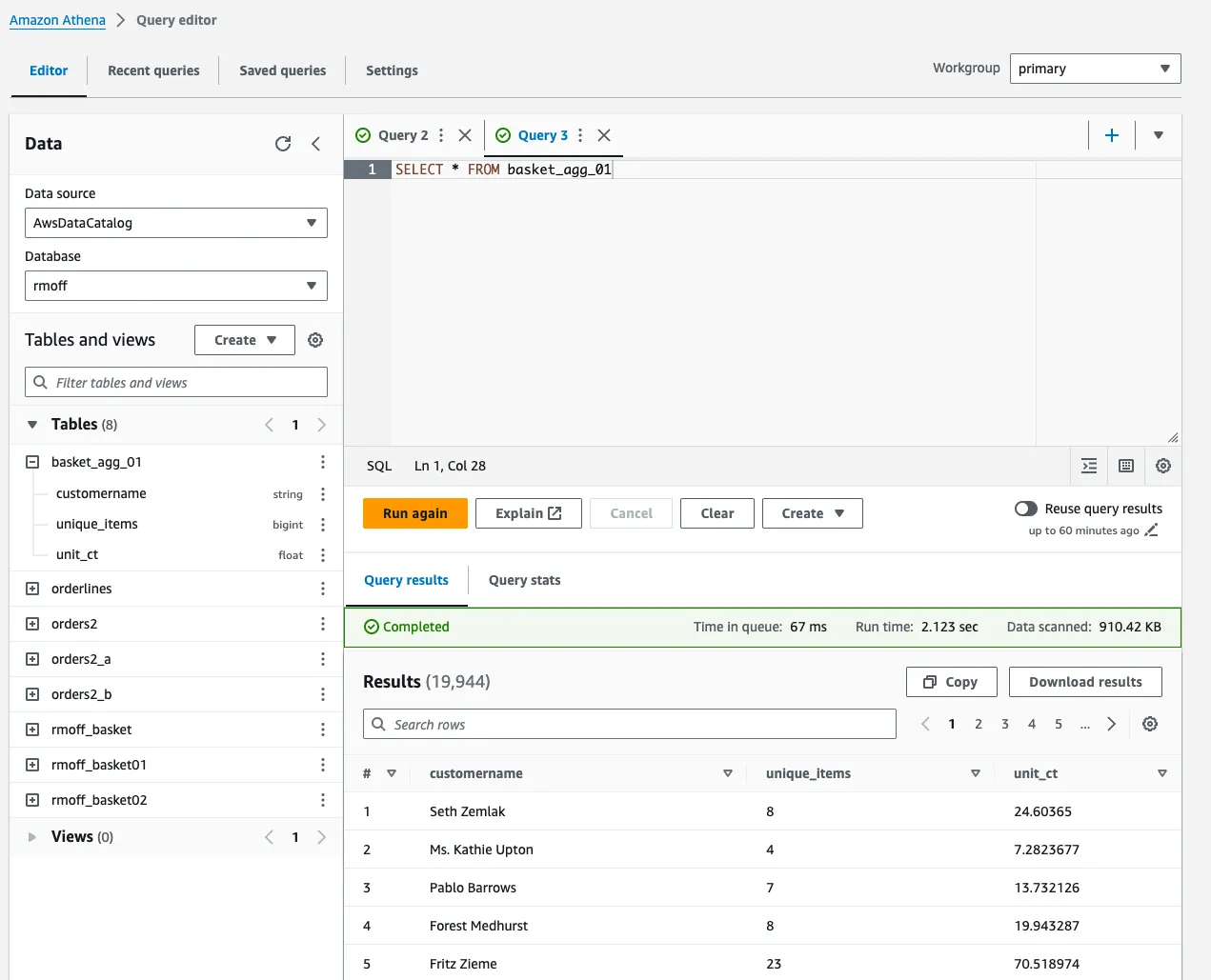
For completeness, here’s the Iceberg data queried through Amazon Athena:
Running real-time ETL on Decodable in production
In the same way that I looked at what it means to move an MSF notebook through to deployment as an application, let’s see what that looks like on Decodable. In practice, what we’ve built is an application. There are no further steps needed. We can monitor it and control it through the web interface (or CLI/API if we’d rather).
Decodable has comprehensive declarative resource management built into the CLI. This means that if we want to store the resource definitions in source control we can download them easily. This could be to restore to another environment, or to promote through as part of a CI/CD process.
Conclusion
We’ve seen how two platforms built on Apache Flink offer access to Flink SQL.
On Decodable, the only SQL you need to write is if you want to transform data. The ingest and egress of data is done with connectors that just require configuration through a web UI (or CLI if you’d rather). Everything is built and deployed for you, including any dependencies. You just bring the config and the business logic; we do the rest. Speaking of REST, there’s an API to use too if you’d like :)
On Amazon MSF, SQL is used for building connectors as well as transforming data. To use a connector other than what’s included means making the JAR and dependencies available to MSF. Each time you change a dependency means restarting the notebook, so iteration can be a frustratingly slow process. The version of Flink (1.15) also doesn’t help as several features (such as<span class="inline-code">CREATE TABLE…AS SELECT</span>) aren’t available. Lastly, once you’ve built your pipeline in SQL using the Studio Notebooks, to deploy it as an application means bundling it as a PyFlink ZIP and deploying it—something that for me didn’t work out of the box.
Ready to give it a go for yourself? You can find Amazon MSF here, and sign up for Decodable here.




