.svg)



Apache Iceberg is an open table format. It combines the benefits of data lakes (open standards, cheap object storage) with the good things that data warehouses have, like first-class support for tables and SQL capabilities including updates to data in place, time-travel, and transactions. With the recent acquisition by Databricks of Tabular—one of the main companies that contribute to Iceberg—it’s clear that Iceberg is winning out as one of the primary contenders in this space.
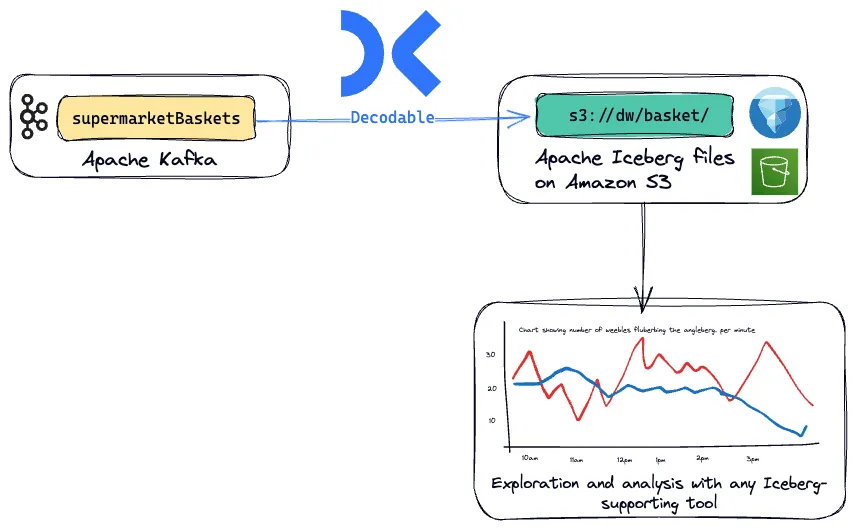
With all these benefits, who wouldn't want to use Iceberg? And so getting data into it from the ubiquitous real-time streaming tool, Apache Kafka, is a common requirement. Perhaps you've got data from your microservices that use Kafka as the message broker and you want to land that data to Iceberg for analysis and audit. Maybe you're doing data movement between systems with Kafka as the message bus. Whatever the data you've got in Kafka, streaming it in real-time to Iceberg is a piece of cake with Decodable.
Decodable is built on Apache Flink and Debezium, but the beauty of it being a fully managed platform is that you don't even need to know that. I mean, you can know that, because I've just told you. And in fact, you can bring your own Flink jobs and run them directly on Decodable. But I'm going off on a tangent here…to do data movement and processing with Decodable, you use a web interface, CLI, or API to define connections, and that's it. You can add some processing with SQL along the way if you want to, and if you do it's again just web, CLI or API. Not a jot of code to be written!
So let's get started. In this scenario we've got point of sale (PoS) data from multiple stores streaming into a Kafka topic. It is at the basket level, telling us for a particular transaction who the customer was, which store it was at, and what the customer bought. We're going to stream this to Amazon S3 in Iceberg format so that we can then build some analyses against it to answer business questions such as the number of baskets processed during the day, and volume of items sold.
Step 1: Set up a connection to Kafka
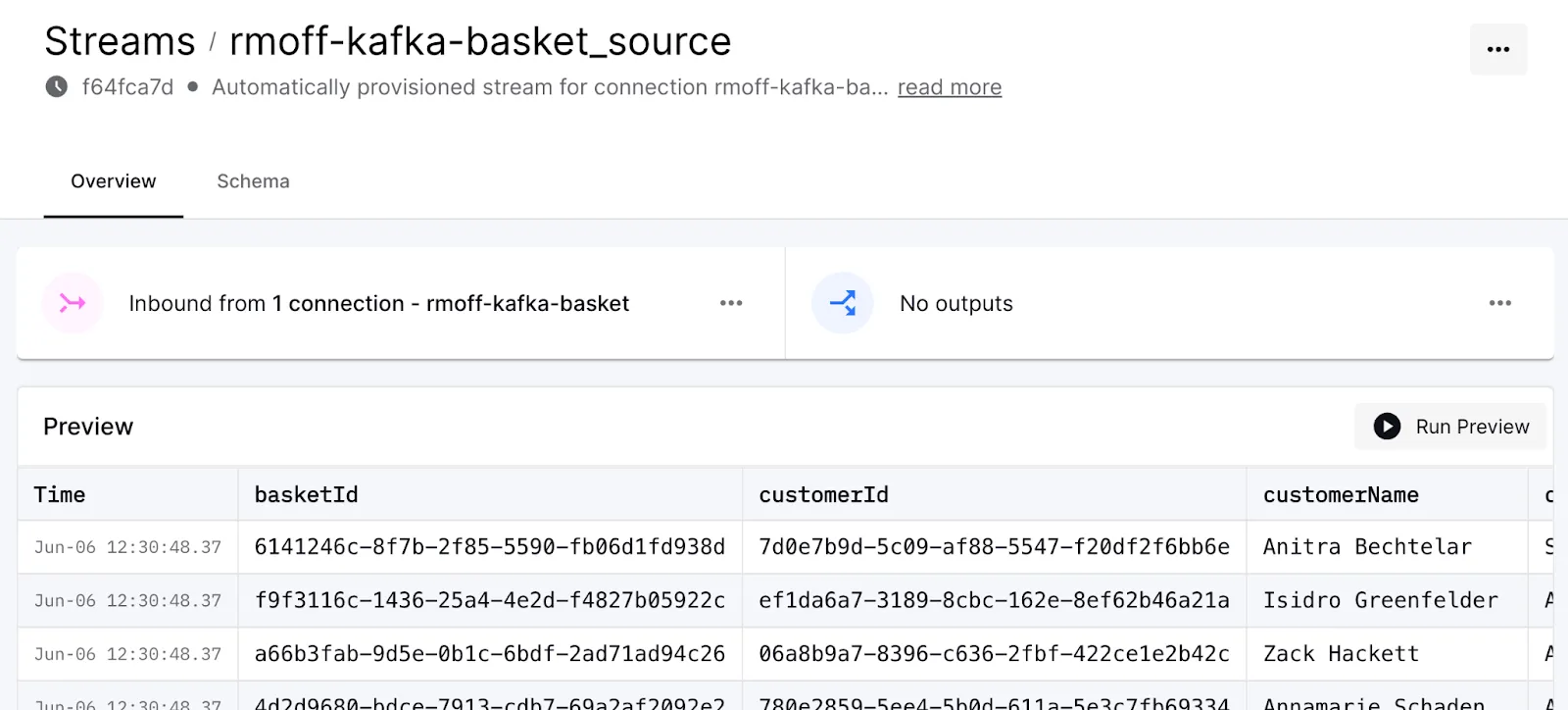
Our Kafka broker has a topic called <span class="inline-code">supermarketBaskets</span> with data in each record that looks like this:
Using the Decodable CLI we'll create a source connection for ingesting the messages from the Kafka topic into Decodable:
From this we get the id of the connection that’s been created:
With the connection defined we can now start it:
At this point let's hop over to the Decodable web UI and look at the data being brought in.
Step 2: Set up a connection to Iceberg
I've already created an S3 bucket, Glue catalog, and done the necessary IAM configuration. Now I just need to tell Decodable to send the data that we're ingesting from Kafka over to Iceberg by creating a sink connection:
One thing to point out here is that the stream id is dynamically derived. You can also hard code it based on the id shown in the web UI (as shown above when previewing the data).
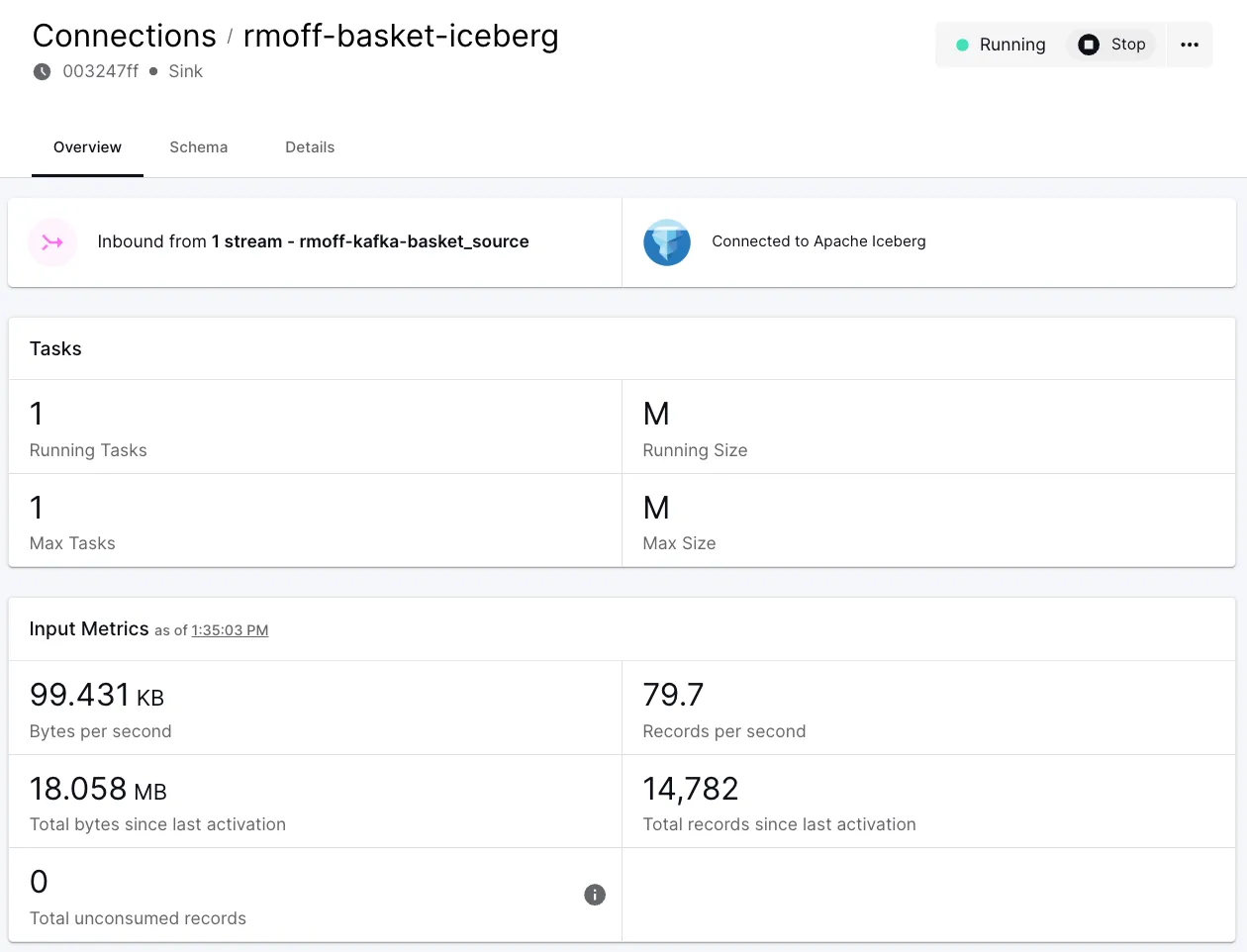
As before, once created, we need to start the connection. Because we want to send all of the data that we've read (and are reading) from Kafka to Iceberg, we'll use <span class="inline-code">--start-position earliest</span>:
Over in the Decodable web UI we can see that the connection is running, and metrics about the records processed
Let's check that the data is indeed being written:
Using the Iceberg data
DuckDB
The wonderful thing about open formats is the proliferation of support from multiple technologies that they often prompt. Iceberg has swept through the data ecosystem, with support from distributed compute such as Flink and Spark, and query engines including Presto, and DuckDB.
Using DuckDB we can quickly do a row count check to make sure we're seeing what we'd expect:
We can also sample the data:
Amazon Athena and Quicksight
There are a variety of tools available for working with Iceberg data to build queries. With the data in S3 and wanting a web UI (rather than CLI like DuckDB above) I reached for the obvious tool—Amazon Athena (which is built on PrestoDB).
Since I'm using the Glue catalog it's easy to find the table that I've loaded:

From here I can write a SQL query in Athena to look at the data and expand out the nested <span class="inline-code">products</span> field using <span class="inline-code">CROSS JOIN</span>:
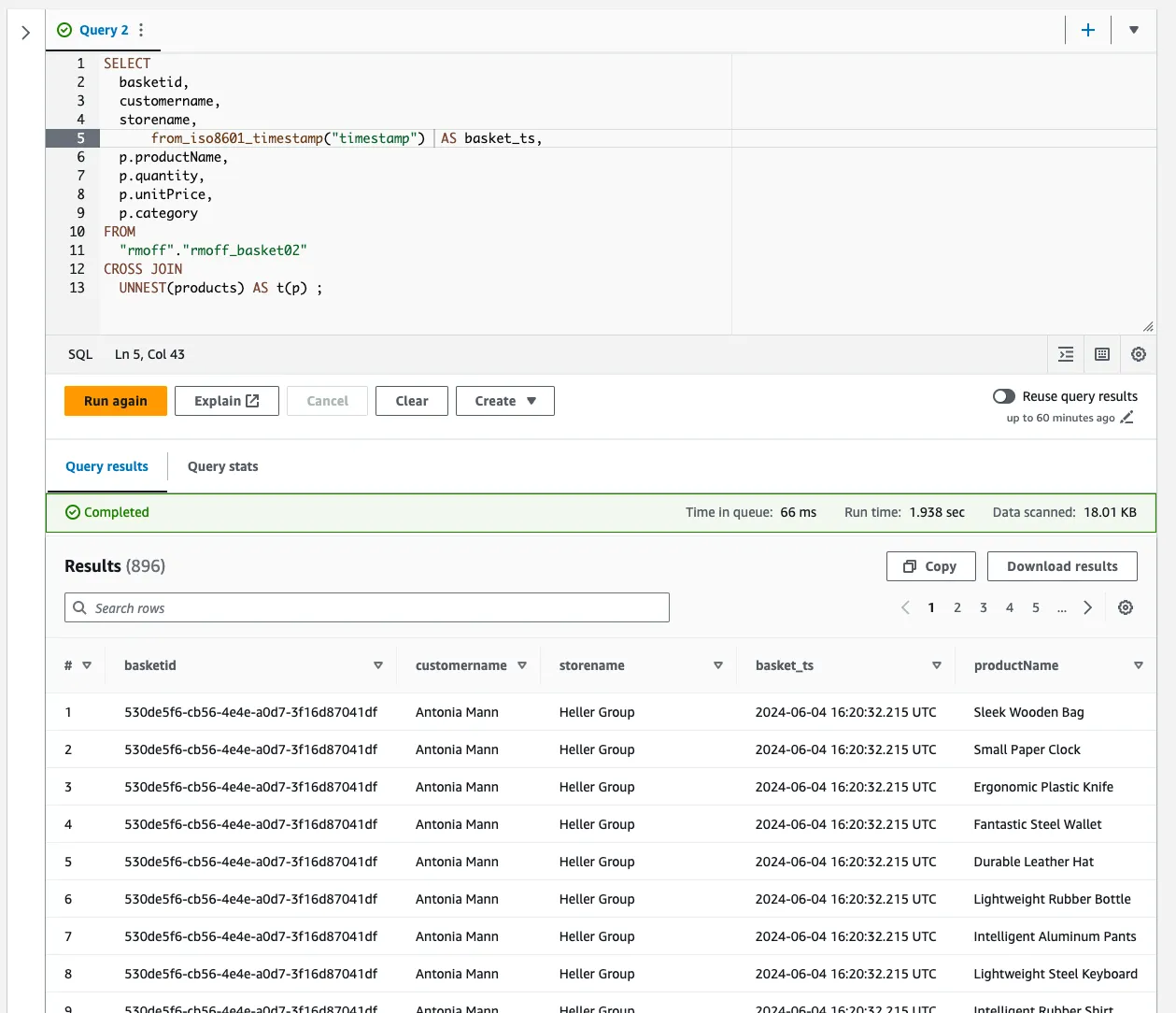
Using this query, I then put together a simple dashboard in Amazon Quicksight (again; easiest tool to hand since I had the AWS console already open…). This uses a slightly modified version of the SQL shown above to split out the date and time components:
Using this, I can plot the number of baskets (transactions) and products sold over time at different granularities, as well as a breakdown of unit sales by category.
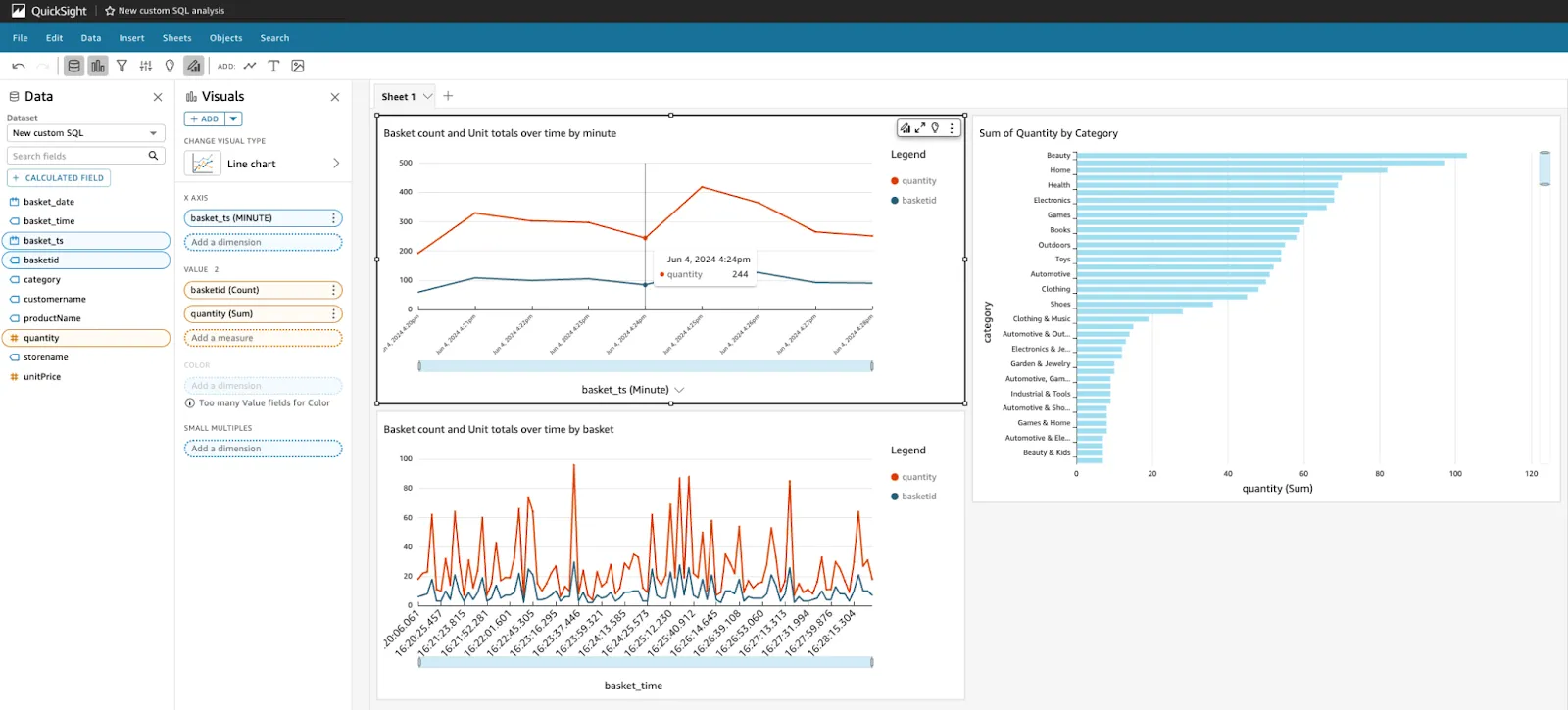
The brilliant thing here is that this is not a batch process, in which I need to rerun a job to see the latest data. As new sales are made in the stores, the data will flow into a Kafka topic and through to Iceberg, ready to query and drive my dashboard.
Learn more
Ready to dive deeper into Flink and looking to avoid some of the more common technical pitfalls? Check out the Top 5 Mistakes When Deploying Apache Flink.
Resources
- Sign up to Decodable and try the Iceberg sink for free today—no credit card required.
- Apache Kafka source connector
- Apache Iceberg sink connector
- Code used to generate this example



