.svg)



Over the last few years, the outbox pattern has become a common solution for implementing data exchange flows between microservices. It allows services to safely and reliably update their own local datastore and at the same time send out notifications to other services via data streaming platforms such as Apache Kafka. But time isn’t standing still: people ask about disadvantages of the pattern (is the database becoming a bottleneck?), alternative solutions such as “listen-to-yourself” have been proposed, Kafka is about to get support for participating in 2-phase commit (2PC) transactions, and more. It’s time to take another look at the outbox pattern, what it is and how to implement it, whether it’s still relevant in 2024, and which alternatives exist!
Recap: What’s The Outbox Pattern?
Congrats! You’ve landed that job as a software engineer at Oh-my-Dawg, the nation’s latest and hottest franchise in beauty care for our four-pawed friends. Pedicure for poodles, lathering for labradors, grooming for greyhounds—there’s a lot of money to be made in this business, and your task is gonna be to build robust and reliable backend systems for that.
Let’s look at one of the business processes, the creation of appointments for a treatment, and how it could be implemented. Oh-my-Dawg runs a microservices architecture, with one service for managing appointments, and another one for managing inventory. When the appointment service receives a request via its REST API, it must persist the information about the requested treatment in its own database. We’re members of the boring technology club, so Postgres is used as a data store. At the same time, the appointment service needs to notify the inventory service about the new appointment, so that shampoo and whatever else is needed can be reserved, and backordered, if needed. To decouple the two services, the notification is sent via Apache Kafka.
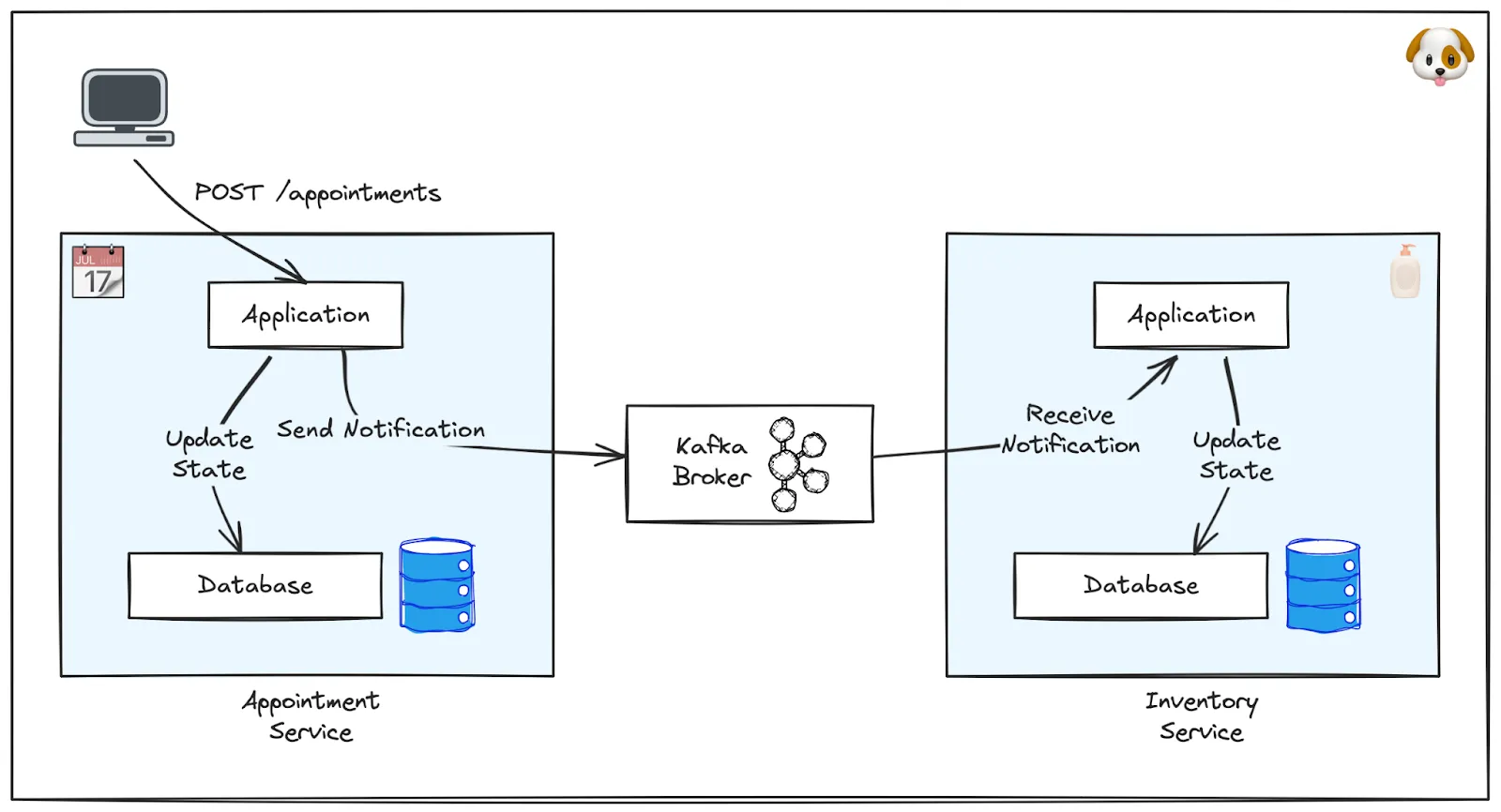
Now, it is vital that these two operations, updating the appointment database and sending the notification, happen atomically—that is, they either both happen, or neither of them does. Otherwise, the overall state of the system would be inconsistent:
- If the database transaction commits but the inventory notification isn’t sent, we’d end up without shampoo for the appointment. Our furry customers won’t be happy!
- If the database transaction fails but the notification is sent, we’d inform the customer about the failed request but still have allocated inventory for a non-existent appointment. The folks over at Oh-my-Dawg accounting won’t like that!
As of today, there’s no way for Kafka to participate in a distributed transaction shared with a database (more on that, in particular whether it is a good idea or not, later on). Fortunately, the outbox pattern provides a solution which doesn’t require distributed transactions to begin with. As part of its local database transaction, the appointment service inserts the notification message which it wants to send into a table in that database. The transaction ensures atomicity for writing the actual data and that message.
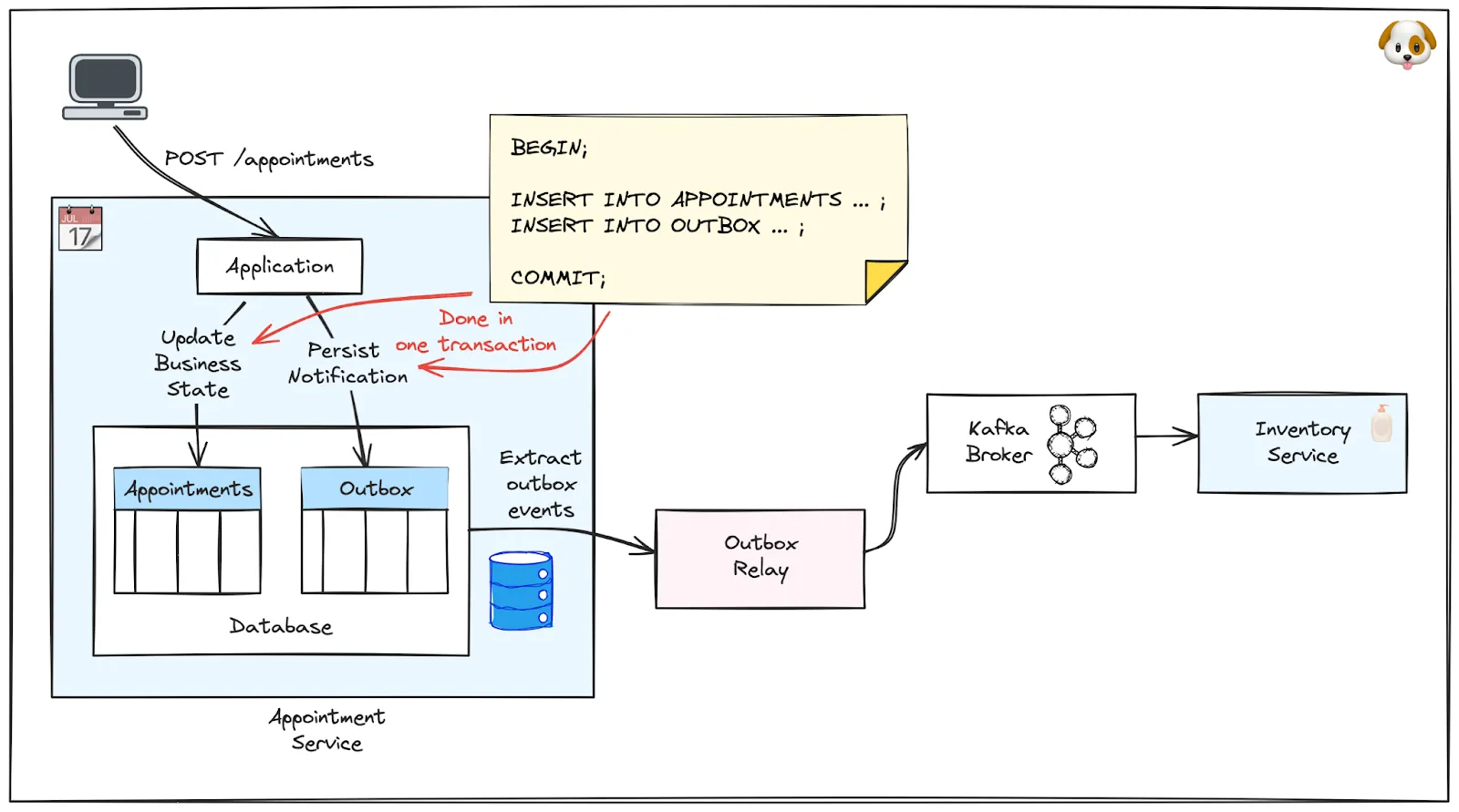
A separate process, called the outbox relay, picks up that message from this outbox table and sends it to Kafka. This happens asynchronously and can be retried if needed, without impacting the clients of the appointment service in any way. Different approaches exist for implementing the outbox relay, with one popular option being log-based change data capture (CDC), using tools such as Debezium. You can learn more about the foundations of the outbox pattern in this article, while this post provides an in-depth hands-on example.
<div class="side-note">Note that, while the outbox pattern ensures atomicity of a local database update and sending out a message to external consumers, it does not provide complete ACID transactional guarantees. Specifically, the pattern provides eventual consistency semantics: changes to the local datastore of the writing service become visible immediately, while the notification of other services happens asynchronously.</div>
Implementation Considerations
Having discussed what the outbox pattern is and what it is used for, let’s dive into some of the implementation details.
Polling vs. Log-Based CDC
One key component to an outbox pattern implementation is the mechanism for retrieving messages from the outbox table. A commonly suggested solution is polling: Some background process queries the outbox table at regular intervals for newly inserted messages and sends them to Kafka. Once that’s done, all emitted messages are marked as processed in the database, or they are deleted right away.
While deceptively simple, there’s a number of problems with this approach. For one, it can be resource-intensive, creating spikes of high load on the database upon each polling attempt. There’s a natural conflict between achieving low latency and not overwhelming the database due to polling too frequently.
The biggest challenge of this approach though, as pointed out by Martin Kleppmann, are its poor ordering semantics. If there are multiple transactions running in parallel, and each one emits an outbox message, it can’t be guaranteed that the order of messages in the outbox table—e.g., designated by timestamps or a sequence field—is the same as the order of commits. This can have severe implications. When not being very careful, it can cause the relay to miss outbox messages, providing consumers with an incomplete feed of events (Oskar Dudycz does a great job in explaining the problem and describing one potential solution; the basic idea is to consider an outbox event only once there are no more transactions running which are older than the one emitting the outbox event). But this also means that there can be inconsistencies between the state of the writing service’s local database and the external state as represented by its published messages. While serialization may be enforced in some cases, for instance using optimistic locking on a specific record, the problem can’t be solved generically in the presence of concurrent writers.
A much better solution is to retrieve the outbox events via log-based CDC. By tailing the database’s transaction log (e.g. the write-ahead log, WAL, in case of Postgres), events are emitted in the exact same order as transactions were committed to the database, ensuring consistency between internal and external representation of the data. Log-based CDC comes with a few other advantages: it avoids the polling overhead and ensures a low latency (typically, changes can be propagated from Postgres to Kafka within a two-digit milliseconds timeframe). It should be the preferred option whenever possible.
The Outbox Table
At the center of the outbox pattern is a table for storing the outbox events. The writing service—such as the appointment service in the Oh-my-Dawg example—only ever makes inserts into this table, but it never updates. Existing events are immutable and cannot be altered after the fact. In that sense, the outbox table represents an append-only log, not unlike the actual transaction log of the database itself.
Besides the actual event payload (often JSON, but you can use any format of your choosing) an outbox table typically has columns for message id (allowing consumers to identify messages sent more than once, more on that later) and event type, allowing you to route events of different types (e.g. “Appointment”) to different topics. When using a partitioned streaming platform such as Kafka, you’ll also need a column for the id of the represented entity (for instance, the appointment id), so that all events pertaining to the same record will be written to the same partition, thus ensuring correct ordering of these events.
As an example, here is the default outbox table format when using Debezium as a log-based outbox relay:
- id (<span class="inline-code">UUID</span>): unique event identifier
- aggregatetype (<span class="inline-code">VARCHAR(255)</span>): the type of domain object described by an event, e.g. “appointment”; used for routing outbox events of different types to different Kafka topics
- aggregateid (<span class="inline-code">VARCHAR(255)</span>): the id of the represented domain object, e.g. the appointment id; used as message key to ensure correct event ordering with partitioned Kafka topics
- type (<span class="inline-code">VARCHAR(255)</span>): The type of event, e.g. “appointment created”; can be used by consumers to trigger specific event handlers
- payload (<span class="inline-code">JSONB</span>): The actual event payload
Housekeeping
One detail which can be easy to ignore at first but which is critical in production scenarios is housekeeping for the outbox table: once events have been picked up from the outbox table, they can and should be removed from the outbox table, preventing it from growing larger and larger. With a polling-based approach as described above this can be done as part of the polling loop (which has to issue read-write transactions to do this, though).
When retrieving outbox messages via log-based CDC, the removal can actually be done right away after inserting a message into the outbox table. More specifically, the <span class="inline-code">INSERT</span> and <span class="inline-code">DELETE</span> can be two subsequent operations within one and the same transaction. As both operations are represented as entries in the append-only transaction log, the outbox message can be safely retrieved from the <span class="inline-code">INSERT</span> change event, while the outbox table always is empty when running a <span class="inline-code">SELECT</span> against it. This mitigates at least in parts the concern about storage overhead that is occasionally brought up against the outbox pattern (see below for details).
<span class="inline-code">pg_logical_emit_message()</span>
What if, instead of implementing what is, in effect, an append-only log in a custom table, you could just use the database’s actual transaction log itself for relaying outbox events? Turns out you can—at least with Postgres!
Through its function <span class="inline-code">pg_logical_emit_message()</span>, Postgres lets you write arbitrary messages to the WAL. This is exactly what you need for the outbox pattern: instead of inserting the outbox messages into a dedicated table, you just store them in the transaction log by means of a simple function call:
<div style="text-align: center">Listing 1.: Writing an outbox message to the transaction log with <span class="inline-code">pg_logical_emit_message()</span></div><br/>
These messages never materialize in any tables (and thus don’t cause any database growth apart from the WAL itself) and you also don’t need to take care of housekeeping, as any obsolete WAL segments will automatically be disposed of. If you are on Postgres, such a log-only outbox implementation is the one I’d recommend to use; you can learn more about the details in this article. It shows how to implement the outbox pattern with Postgres logical decoding messages, using Flink CDC and Debezium as a log-based outbox relay.
For services using MySQL as a datastore, the <span class="inline-code">BLACKHOLE</span> storage engine can be used in a similar way. Akin to writing something to /dev/null, any data written to a table with this storage engine will be immediately thrown away. The writes will reflect in records appended to the binlog (MySQL’s transaction log) though, allowing you to retrieve them using log-based CDC. Note you can use <span class="inline-code">BLACKHOLE</span> and <span class="inline-code">InnoDB</span> tables in one shared transaction, ensuring atomicity for the writes to your actual data tables and the outbox table. If you are aware of similar capabilities for other databases, I’d love to hear from you!
Format Considerations
Whether you are using an actual outbox table or are storing outbox events only in the transaction log, you’ll need to decide on the format for the actual event payload. As far the logical format is concerned, it’s completely up to you how the events should be structured. Being independent from the schema of a service’s actual data tables, the schema of outbox messages can be considered as a form of a data contract, allowing you to evolve your internal table model without impacting or even breaking any external services. The event format should be evolved in a forward-compatible manner, i.e. you can add new fields and drop existing optional fields. That way, the data producer can evolve the schema without having to synchronize with consumers, as consumers with an old schema version will still be able to process events adhering to a new schema version.
As for a physical message format, JSON continues to be a popular choice. It is verbose though, so you may consider using compression, or working with a binary format such as Apache Avro or Google Protocol Buffers instead. With the latter option it can be interesting— instead of connecting to a schema registry from within the writing service—to use a registryless serializer. As schemas won’t change while a service is running, they can be statically defined at build time. That way, there’s no runtime dependency from the application to a schema registry and thus one less failure point on the synchronous request processing path. If required, schemas can still be published to a registry (for instance, the Confluent schema registry, or Apicurio) via a CI/CD pipeline when deploying a new version of the source microservice, making them available for discovery and consumption by downstream processes.
Another interesting option to consider can be whether to adopt CloudEvents for your event payloads. It’s a specification for describing events in a standardized way, allowing consumers to uniformly access common attributes such as event id, source, and timestamp.
Backfills
One of the most common questions I’ve seen around the outbox pattern is how to deal with backfills. Let’s assume Oh-my-Dawg has been operating for a while already, and only now the need comes up for notifying other services about appointment updates. So you adjust the appointment service to use the outbox pattern for that purpose, but how do you emit messages describing the appointments already existing in the database at this point? Or maybe disaster has struck, and you’ve lost the topic with appointment events on the Kafka cluster so now your inventory is going to be out of sync.
One solution to this is to use the same machinery and communication channel—i.e. outbox, CDC, Kafka—and emit backfill events which essentially describe the current state of the data. This is relatively easy if there are no concurrent writes. At Oh-my-Dawg, you’d scan the existing dataset and insert an event for each existing appointment into the outbox table. Unfortunately, in a live production system you usually won’t have the luxury of exclusive write access. In which case you’ll need to deal with concurrent updates and make sure that any backfill events don’t overwrite updates to a record which is happening in parallel.
This can be done by implementing the watermark-based snapshotting approach introduced in the DBLog paper (which since then has been implemented by Debezium, Flink CDC, and others). The high-level intuition for this algorithm is to incrementally step through the dataset to be backfilled in ordered chunks, consuming change events from the transaction log in parallel, and apply a deduplication step for giving any events from the log precedence over backfill events. Chunks are segmented by marker events which are inserted into the log by the snapshotting mechanism. A backfilling job for outbox events could look like this:
- Insert a “chunk start” event into the outbox
- Select the next chunk of data to be backfilled, for instance appointments with ids 1-1,000, and insert corresponding backfill events into the outbox
- Insert a “chunk end” event into the outbox
- Repeat at 1.) until all data has been backfilled
When extracting events from the outbox, for each of the windowed chunks, processing happens in a buffered way. All the regular, non-backfill events are propagated. A backfill event will only be propagated if there’s no non-backfill event for the same record (for instance, the appointment with id 42) in the current chunk, otherwise it will be discarded. This buffering could happen in different ways, for instance using a Kafka Connect SMT, or using a Flink stream processing job. To learn more about this approach to concurrent incremental backfilling, refer to this post on the Debezium blog.
Idempotency for Consumers
Let’s spend a few minutes thinking about how event consumers such as the inventory service could be implemented. A key requirement there is to make sure that each event is processed not more than once. Otherwise, we might end up allocating too much inventory, say two portions of shampoo for one and the same treatment. The challenge is that these kinds of data pipelines have at-least-once semantics typically. If, for instance, the CDC process crashes after emitting an event to Kafka, but before acknowledging that event as consumed with the source database, it will be emitted a second time after restarting.
One option for detecting—and discarding—such duplicates, is adding a unique identifier to each event, such as a UUID. Consumers keep track of the UUIDs of the events they have processed successfully, for instance by storing them in a journal table in their database. When an event comes in, they check whether they’ve seen its UUID before, and if so ignore that duplicate event. The problem though is: for how long should a consumer keep these UUIDs before removing them from its journal? Keeping them for too long may cause the journal to grow unwieldy, dropping them too early may cause duplicate events to go unnoticed if they arrive after the retention period of the journal.
A better approach is using a monotonically increasing value, i.e. a value that only ever increases and never decreases between different events. That way, consumers need to store only the latest value they’ve seen, just like a watermark. When they receive an event with a sequence value which is the same as or lower than the current watermark (and transport semantics are not at-most-once, i.e. events are guaranteed to not get lost), this must be a duplicate which can be discarded. Now, as discussed above, you can’t use a standard database sequence for creating that value, as you can’t guarantee that it is going to be monotonically increasing for events created in multiple concurrent transactions. Instead, the records position (offset) in the source database’s transaction log can be used, for instance the LSN (log sequence number) in case of Postgres, a “byte offset into the [transaction log], increasing monotonically with each new record”. Similar ids exist in other databases too, check their documentation on the exact format and semantics.
Criticisms of the Outbox pattern
The outbox pattern definitely fulfills its purpose: allowing a service to update its own database and send out notifications to other services via streaming platforms such as Kafka, in a safe and reliable way, without requiring distributed transactions. When it comes to critique on this pattern, I mostly see two things being mentioned: overhead on the database, and complexity. A less commonly brought up concern is latency. Let’s take a look at all of these in turn.
Database Overhead
This concern is about the additional load put onto a service’s database by using it for storing and emitting outbox messages. The potential impact is twofold: more data needs to be stored in the database (adding to the overall size of the database), and transactions have a larger payload, as besides the actual table writes, there’s also the outbox inserts (adding to the overall I/O of the database, thus potentially impacting latency and throughput).
While true, it depends on the actual situation whether these things actually are a problem or not. When it comes to the size overhead, this can be mitigated by using a log-only outbox implementation, instead of having an actual outbox table, as described above. That way, outbox messages are only present in the transaction log from where they can be discarded as soon as they have been picked up by the outbox relay, i.e. they are typically short-lived. As for the overhead on transactions, each transaction has a given baseline cost anyways. Doing one more insert for an outbox event probably won’t be significant in most cases, but in the end it’s something you can only determine in your actual environment with your actual workload and its characteristics.
So far I have seen this mostly as a theoretical concern rather than as an actual, empirically demonstrated problem.
Complexity
The complexity argument needs consideration from two different angles: an external perspective looking from the outside at a service landscape such as Oh-my-Dawg’s as a whole, and an internal perspective looking at how individual services are implemented.
From the external perspective, you’re looking at things such as the overall number of moving parts of the solution as well as their interactions. In a microservices architecture, there’ll be a database for each service and a streaming platform for inter-service messaging in any case. When implementing the outbox pattern, you’ll also need the outbox relay. If you don’t do CDC yet, adding a system like Debezium—for instance by standing up a Kafka Connect cluster—for this purpose will add one more component indeed. This component needs to be operated, updated, kept secure, etc. On the other hand, chances are you need CDC anyways, in which case configuring it for also capturing outbox events doesn’t change the consideration much. Another option can be to run the outbox relay within the writing service yourself: via its embedded engine, Debezium can be used as a library in Java-based applications, thus avoiding the need for running the outbox relay in a separate process.
The other, internal, angle to the complexity argument is primarily about the programming model, i.e. how hard or simple is it to make use of the outbox pattern from an application development perspective. For that I’d argue, when done right, the outbox pattern can actually reduce complexity. Instead of dealing with database APIs such as JDBC and the Kafka client, developers of the writing service only need to concern themselves with the database access. As the Kafka access happens behind the scenes via the CDC process, they don’t need to be aware of the intricacies of Kafka producers, how to configure and tune them, etc. The key thing here is to find the right abstractions, so as to simplify the process of emitting outbox messages as much as possible. As an example, Debezium’s extension for implementing the outbox pattern within Quarkus-based microservices allows you to use CDI events for doing so:
<div style="text-align: center">Listing 2.: Persisting an appointment and emitting an outbox message in a Quarkus-based microservice</div>
Similar solutions exist for other stacks, for instance for Spring Boot, and programming languages. Whether using a ready-made solution or implementing something from scratch, the required infrastructure for enabling the outbox pattern within an application can and should be encapsulated in an easy-to-use component, shielding application logic from the implementation details.
Latency
A minor disadvantage of the outbox pattern is the increased latency of messages sent to external consumers. This will take longer when routing them through the database than when publishing them to Kafka directly. While that’s true, I don’t think this is really significant in practice. The notification of external processes is designed as an asynchronous process anyways, and the publication of messages via log-based CDC can be really fast. If it is a problem in a microservices architecture when one service receives a message sent by another service with a delay of a few hundred milliseconds, then probably there’s something not quite right with how the services are cut in the first place.
Discussion
If you want to achieve consistency in a distributed system, such as an ensemble of cooperating microservices, there is going to be a cost. This goes for the outbox pattern, as well as for the potential alternatives discussed in the next section. As such, there are valid criticisms of the outbox pattern, but in the end it’s all about trade-offs: does the outbox put an additional load onto your database? Yes, it does (though it usually is insignificant, in particular when using a log-based outbox relay implementation). Does it increase complexity? Potentially. But this will be a price well worth paying most of the time, in order to achieve consistency amongst distributed services. In the next section, we are going to take a look at other solutions to this problem and the trade-offs they make.
Alternatives to the Outbox Pattern
The outbox pattern isn’t the only solution for implementing reliable data exchanges between different systems in a microservices architecture. Let’s explore some of the options and their specific pros and cons.
Dapr
Not so much an alternative as a variation of the outbox pattern is provided by Dapr, a distributed platform for building reliable microservices. In its outbox pattern implementation, Dapr first writes the message to be published to an internal Pub/Sub topic. If that succeeds, it updates the local state, also writing an identifier of that previously sent message.
A separate Dapr process reads from the internal topic and looks for the identifier in the state store. If present, it re-publishes the message on a user-facing topic—from where it can be read by the consuming service—and removes the identifier from the state store. If the message identifier cannot be found in the state store, this indicates that the state store update failed and the internal Pub/Sub message will not be propagated.
The advantage is that the outbox event doesn’t have to be written to the state store, addressing the overhead concern discussed above. That is being paid for though by having two Pub/Sub writes (internal and external) instead of one, plus the additional look-up and removal of the identifier in the state store (when compared to a purely log-based outbox implementation). So the trade-offs are slightly different, but not clearly advantageous to me.
Read-yourself
Instead of having a service write to its database and drive the update to Kafka from there via an outbox, a commonly suggested alternative is to reverse this order. When handling a request, the service writes only to Kafka. Thanks to transactional producers, writes to an internal data topic and a public topic for external consumption can happen atomically. The service subscribes to this data topic and updates data views in its local state store based on that (Event Sourcing).
This provides the same characteristics in terms of availability and consistency across services as the original outbox pattern. The downside of this approach is that there are no synchronous read-your-own-write guarantees. As consumption via Kafka is asynchronous, it is not guaranteed that a service will be able to retrieve a record from the data store right after it has been published to Kafka. This can make for confusing user experiences, if for instance a user can’t see their appointment right after creating it. Also other tasks which are trivial when writing to a database first—such as enforcing unique constraints—are becoming challenging with this approach. While some techniques for mitigation exist, it’s not an approach I’d recommend due to the inherent complexities.
Stream Processing on “Raw” Change Event Streams
Another alternative is to use change data capture not for an outbox table, but for the actual data tables of the service itself, such as the “Appointment” table in the Oh-my-Dawg example. Exposing these change event streams across service—and team—boundaries can be problematic, as it exposes a service's internal data model and its structure to external consumers. In particular when it comes to changes to the data schema, this can cause friction and disruption. Stream processing, for instance via Apache Flink or Kafka Streams, can be a way out, establishing consciously crafted data contracts between the providing service and event consumers. With tools like Flink SQL, you can apply data transformations for shaping the published events, limit which events get published, create denormalized events by joining multiple change event streams, and much more. Flink CDC can be used to run Debezium natively within Flink, essentially letting a Flink job take the role of the outbox relay.
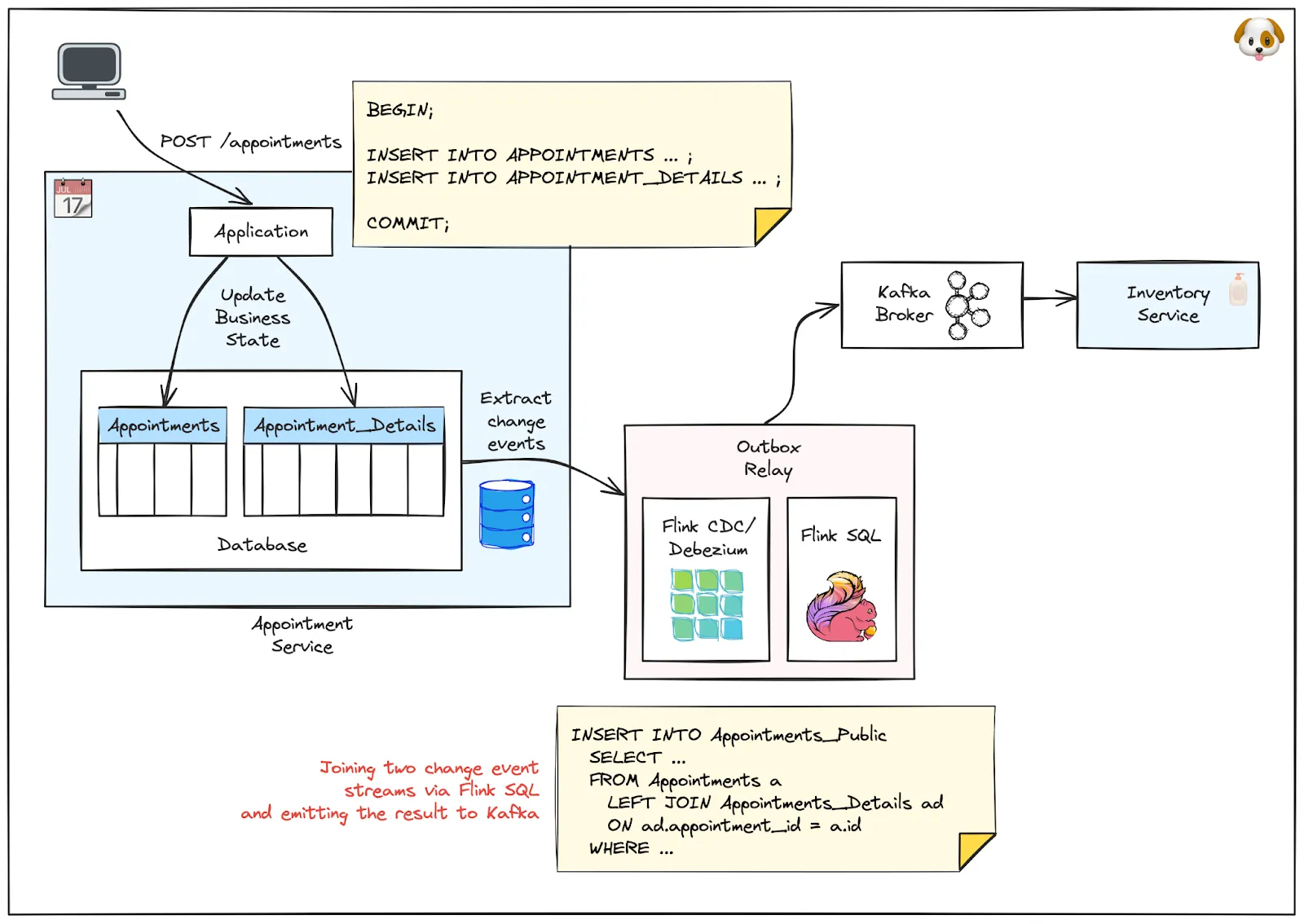
The big advantage of this over the outbox pattern is that no code changes to the source application itself are required. Also there is no impact on the source database, as it only contains the actual data tables and nothing more. The shaping of published events sent to other services happens completely asynchronously. The downside is that you need to add a stream processing solution to the overall architecture (though managed services can help navigate this complexity), and stream processing has a learning curve on its own. Establishing transactional semantics—i.e. emitting a derived public event only once all relevant events from a source transaction have been processed—can be a challenging task, too. With the outbox pattern, which emits messages in the context of transactions in the source database, this comes for free.
2PC
Some folks argue that the outbox pattern essentially is a work-around for the lack of 2PC (two-phase commit) support in Kafka. A spicy take, I like it! And indeed, there’s something to this. If you are using messaging infrastructure like a good ol’ JMS broker which supports enlisting in global transactions alongside databases, you’ll get the all-or-nothing semantics for writing to a service’s database and sending a message to other services which we’re after.
So it should be good news then that something similar will be possible with Kafka soon, as the Kafka community currently is working on KIP-939 (“Support Participation in 2PC”). But in my opinion, this KIP won’t render the outbox pattern obsolete; the reason being the implications on service availability. With the outbox pattern, a service only needs a single resource to be available in order to process an incoming request—its own database. Whereas with 2PC, it needs two resources, the database and the Kafka cluster, which means that the service’s overall availability actually is lower.
Also, there usually isn’t a good reason in the first place to make the process of emitting a notification to external services part of the synchronous call flow. This activity isn’t relevant for the client making the inbound request and you’re just unnecessarily extending request processing time. Another way to see this is as eating into your “synchrony budget” (a notion I am planning to discuss in more detail in a future blog post) without any benefit. Another, minor, advantage of the outbox pattern is that developers of the writing service only need to know one API (for interacting with the database) rather than two APIs, for database access and for message platform access, respectively.
Durable Execution
Using the outbox pattern and a bit of glue code, it is possible to orchestrate Sagas, long-running business transactions, across distributed services. Durable execution frameworks such as Temporal, Restate, or DBOS Transact aim to take things one step further with a higher-level programming experience. In a nutshell, they provide a form of persistent continuations, transparently retrying failed operations, keeping track of the execution state of a service, and automatically restoring it in case of failures.
There has been a fair amount of buzz around these solutions lately and their promise of drastically simplifying the creation of robust and fault-tolerant distributed workflows. Whether they’ll gain widespread adoption in the industry remains to be seen at this point. In particular the requirement to implement workflows using particular SDKs—potentially creating a lock-in effect—and the need for framework-specific execution runtimes such as the Temporal Service or the Restate server, typically with bespoke state store implementations, may pose a challenge for proliferation. But if they manage to live up to their promise, they may free developers from having to deal with details such as outboxes, retries, etc.
Summary
So, where does all that leave us? Is the outbox pattern still relevant and should the development team at Oh-my-Dawg use it for implementing data exchanges between their microservices? Or are there clearly superior alternatives, rendering the pattern obsolete?
As far as I am concerned, the outbox pattern continues to deserve a very central spot in the toolbox of development teams building microservices architectures.
While alternatives do exist, they each come with their own specific trade-offs, around a number of aspects such consistency, availability, queryability, developer experience, operational complexity, and more. The outbox pattern puts a strong focus on consistency and reliability (i.e. eventual consistency across services is ensured also in case of failures), availability (a writing service only needs a single resource, its own database) and letting developers benefit from all the capabilities of their well-known datastore (instant read-your-own-writes, queries, etc.). But each situation comes with its own context, if for instance you are not in a position to modify a given service, stream processing on table-level change event streams may be the way to go for you.
Whenever possible, the outbox pattern should be implemented via log-based CDC rather than polling, thus ensuring correct ordering of outbox events and mitigating concerns around overhead on the database. A log-only implementation, for instance using Postgres’ <span class="inline-code">pg_logical_emit_message()</span> is particularly appealing.
In any case, whether you are using the outbox pattern, or any of the alternatives, what you should never do is just write to a database and a messaging broker without global transactional guarantees, hoping for the best. Unfortunately, there are many blog posts and articles out there, advocating for exactly that, either knowingly or unknowingly of the implications. In particular, in the absence of distributed transactions, it is not sufficient to trigger a Kafka message using a local database transaction synchronization, which is a commonly described approach. Processes will shut down uncleanly, machines will crash, and networks will stop working. So inconsistencies are bound to happen when not taking the right precautions.
Better don’t go there and always remember: Friends don’t let friends do dual writes!





