Testing Flink jobs can be challenging for a number of reasons, one of them being the fact that we typically have to interact with external data systems or services. In this article we are picking up the custom Apache Flink job from one of our recent blog posts and dive into different aspects related to testing. More specifically, we'll discuss how to (re)write (existing) Flink jobs in a more modular way by defining job-specific interfaces for the actual processing logic and by making the source and sink components which talk to external data systems pluggable. Doing so allows us to not only unit test certain job components in isolation, but instead test the full processing logic of said jobs without the stringent necessity to always have access to any external services our Flink jobs almost certainly depend on.
Quick Recap of the Flink Job
The example job in question reads JSON payloads from a Kafka topic which describe fruit intake events that look as follows:
{
"name": "Banana",
"count": 1
}
These events are supposed to be enriched with the respective nutrition values of the various fruits which can be retrieved from a 3rd party service. The enriched events are written back to another Kafka topic and are expected to result in a payload shape like this:
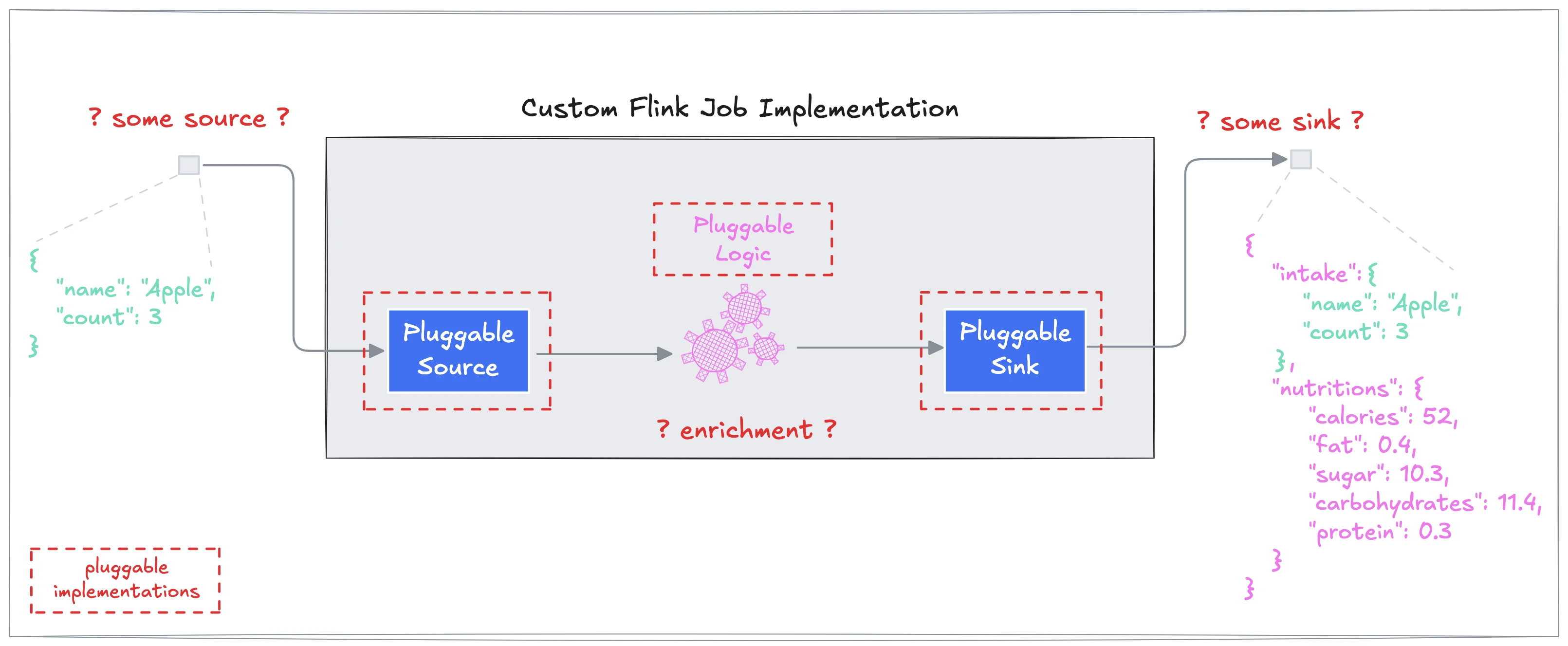
The illustration below shows a high level view of how the Flink job at hand is currently implemented:
It is immediately visible that the job implementation as-is contains three components which directly depend on external services. Source and sink both need Kafka while the processing logic relies on the availability of a 3rd party HTTP service. This is anything but convenient from a job testing perspective because it means we are basically forced to always perform integration tests against all external service dependencies to be able to test a full end-to-end flow for this Flink job. While these types of job tests are absolutely vital, there are good reasons why you might want to only test the actual data processing in isolation at different levels.
That said, this job would ideally allow for swapping out any of these three components and instead plugging in dummy implementations or mocks for the sake of easier and isolated testability. Let's figure out ways to improve this situation and address the shortcomings induced by the tight coupling to external service dependencies.
Refactoring for Better Job Testability
Using the original code example as a starting point, we are going to refactor this job and its components step by step to make certain aspects of the implementation pluggable and thereby achieve better job testability. The full source and test code for this article can be found in our examples repository here.
Adapt Job Processing Logic
Let's begin with the core processing logic for the event payload enrichment which originally looked like this:
public class HttpServiceEnricher implements MapFunction<FruitIntake, FruitEnriched> {
public static final String API_SERVICE_ENDPOINT = "https://fruityvice.com/api/fruit/%s";
private static transient ObjectMapper OBJECT_MAPPER = new ObjectMapper();
private static transient HttpClient HTTP_CLIENT = HttpClient.newHttpClient();
@Override
public FruitEnriched map(FruitIntake intake) throws Exception {
// original enrichment implementation here
// doing HTTP calls against the API …
}
}
While being relatively straightforward, the code is inherently tied to making HTTP calls against a 3rd party service. This makes it unnecessarily hard to properly test it in isolation or plug in other implementations based on, for instance, static test data. One way, to improve this is by extracting the core logic i.e. the enrichment aspect of this function into a separate class which implements this custom interface:
//interface
public interface NutritionEnricher {
FruitEnriched enrich(FruitIntake intake);
}
//default implementation
public class HttpNutritionEnricher implements NutritionEnricher, Serializable {
public static final String API_SERVICE_ENDPOINT = "https://fruityvice.com/api/fruit/";
private static final transient ObjectMapper OBJECT_MAPPER = new ObjectMapper();
private static final transient HttpClient HTTP_CLIENT = HttpClient.newHttpClient();
private String apiServiceEndpoint;
public HttpNutritionEnricher() {
this.apiServiceEndpoint = API_SERVICE_ENDPOINT;
}
public HttpNutritionEnricher(String apiServiceEnpoint) {
Objects.requireNonNull(apiServiceEnpoint);
this.apiServiceEndpoint = apiServiceEnpoint;
}
@Override
public FruitEnriched enrich(FruitIntake intake) {
/* pretty much the same implementation here */
}
}
With this in place, the <span class="inline-code">MapFunction</span> in our Flink job doesn't do much any longer but rather delegates its work to any implementation that follows this <span class="inline-code">NutritionEnricher</span> interface.
public class FruitNutritionMapper implements MapFunction<FruitIntake, FruitEnriched> {
private final NutritionEnricher nutritionEnricher;
public FruitNutritionMapper() {
this.nutritionEnricher = new HttpNutritionEnricher();
}
public FruitNutritionMapper(NutritionEnricher nutritionEnricher) {
this.nutritionEnricher = nutritionEnricher;
}
@Override
public FruitEnriched map(FruitIntake intake) throws Exception {
return nutritionEnricher.enrich(intake);
}
}
Test New Job Processing Logic
Testing this <span class="inline-code">MapFunction</span> now becomes essentially a matter of testing the different interface implementations, first and foremost our <span class="inline-code">HttpNutritionEnricher</span> which acts as the default and for which you can find a basic test here. This particular test class still relies on access to the 3rd party service. However, by using tools or libraries such as WireMock, you could mock selected API calls and write a test class in the following way:
public class MockNutritionEnricherTest {
@RegisterExtension
static WireMockExtension WIRE_MOCK = WireMockExtension.newInstance()
.options(wireMockConfig().dynamicPort())
.configureStaticDsl(true).build();
@ParameterizedTest(name = "nutrition enrichment for valid fruit ''{0}'' with mocked api")
@ValueSource(strings = { "raspberry", "melon", "banana" })
public void testValidFruitWithMockedApi(String validFruitName) throws Exception {
// given
var fruitIntake = new FruitIntake(validFruitName, 1);
stubFor(
get("/"+validFruitName).willReturn(
jsonResponse(TestData.WIRE_MOCK_JSON_RESPONSES.get(validFruitName),200)
)
);
// when
var mockedEnricher = new HttpNutritionEnricher(WIRE_MOCK.getRuntimeInfo().getHttpBaseUrl());
var enrichedActual = mockedEnricher.enrich(fruitIntake);
// then
var enrichedExpected = new FruitEnriched(fruitIntake, TestData.FRUIT_NUTRITION_LOOKUP_TABLE.get(validFruitName));
assertEquals(enrichedExpected, enrichedActual);
}
/* more tests e.g. for invalid/unavailable fruit names here */
}
While there are of course other ways and means to come up with tests similar to this, the important aspect in the context of this article is to be able to independently test (parts of) our Flink job processing logic without relying on external service access all the time, here the 3rd party API.
Adapt Job Setup
What about the rest of this job's components and their testability? To remind ourselves, the Flink job reads the raw fruit intake events from an Apache Kafka source topic and writes enriched fruit events according to our processing logic into another sink topic. From a testing perspective, this means we have in total three components to consider, namely:
- the Flink connector source (here Kafka) to read from
- the map function representing the processing logic which we just covered in the previous section
- the Flink connector sink (also Kafka) to write to
The fact that our original Flink job uses the Decodable Pipeline SDK and operates on <span class="inline-code">DecodableStreamSource</span> / <span class="inline-code">DecodableStreamSink</span>—which are convenient wrappers to abstract away any Kafka specific data access—doesn't change anything about Kafka being used as an external dependency. This holds true not only for running but more importantly also for testing the Flink job at hand.
Taking a look at the existing job implementation, we can see at first glance that it is inflexible with regard to the above mentioned components because the whole job topology is rigidly assembled in the main method like so:
public static void main(String[] args) {
try {
var env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DecodableStreamSource<FruitIntake> source = DecodableStreamSource.<FruitIntake>builder()
.withStreamName(FRUIT_INTAKE_STREAM)
.withDeserializationSchema(new JsonDeserializationSchema<>(FruitIntake.class))
.build();
DecodableStreamSink<FruitEnriched> sink = DecodableStreamSink.<FruitEnriched>builder()
.withStreamName(FRUIT_INTAKE_ENRICHED_STREAM)
.withSerializationSchema(new JsonSerializationSchema<>())
.build();
// read the fruit intake events
env.fromSource(
source,
WatermarkStrategy.noWatermarks(),
"[stream-fruit-intake] fruit intake source")
// enrich the fruit intake events
.map(new HttpServiceEnricher())
// write the resulting events into the sink i.e. the enriched stream
.sinkTo(sink);
env.execute("fruit enricher cupi job with sdk");
} catch (Exception e) {
e.printStackTrace();
}
}
How could we fully test such a job run without depending on Kafka? More so, even if there is some (containerized) Kafka available wherever we plan to run any such tests, how should we go about the 3rd party HTTP service needed by the <span class="inline-code">MapFunction</span>? For the latter, one option would be to try and duplicate pretty much the whole job setup again in a test class and then only swap out the actual <span class="inline-code">MapFunction</span> for some other implementation which does the enrichments, for instance, based on some in-memory lookup table.
In general though, this is probably undesirable and might be better addressed by making all or at least selected job components pluggable right from the beginning, such that we can additionally provide testing-specific sources and sinks, thereby getting rid of the external Kafka dependency during test runs.
Another little refactoring leads us to a new Flink job class. The main difference to the original job class is that we now have:
- three pluggable job components defined as class members
- a constructor which allows to set these components according to our needs
- another method to set up the execution environment and define the job topology which was previously done in the main method directly</li>
All that is left to adapt is the main method which instantiates the pluggable components, feeds them into the job class’ constructor, and calls the <span class="inline-code">run()</span> method on the job instance:
@SourceStreams(FruitEnricherJob.FRUIT_INTAKE_STREAM)
@SinkStreams(FruitEnricherJob.FRUIT_INTAKE_ENRICHED_STREAM)
public class FruitEnricherJob {
public static final String FRUIT_INTAKE_STREAM = "fruit-intake";
public static final String FRUIT_INTAKE_ENRICHED_STREAM = "fruit-intake-enriched";
private final Source<FruitIntake, ?, ?> source;
private final Sink<FruitEnriched> sink;
private final MapFunction<FruitIntake,FruitEnriched> mapper;
public FruitEnricherJob(Source<FruitIntake, ?, ?> source, Sink<FruitEnriched> sink, MapFunction<FruitIntake,FruitEnriched> mapper) {
this.source = source;
this.sink = sink;
this.mapper = mapper;
}
public void run() {
try {
var env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// create and read data stream from source
env.fromSource(
source,
WatermarkStrategy.noWatermarks(),
"[stream-fruit-intake] fruit intake source")
// enrich the fruit intake events
.map(mapper)
// write the result into the sink i.e. the enriched stream
.sinkTo(sink);
env.execute("fruit enricher cupi job with sdk");
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
DecodableStreamSource<FruitIntake> source = DecodableStreamSource.<FruitIntake>builder()
.withStreamName(FRUIT_INTAKE_STREAM)
.withDeserializationSchema(new JsonDeserializationSchema<>(FruitIntake.class))
.build();
DecodableStreamSink<FruitEnriched> sink = DecodableStreamSink.<FruitEnriched>builder()
.withStreamName(FRUIT_INTAKE_ENRICHED_STREAM)
.withSerializationSchema(new JsonSerializationSchema<>())
.build();
MapFunction<FruitIntake,FruitEnriched> mapper = new FruitNutritionMapper();
var job = new FruitEnricherJob(source, sink, mapper);
job.run();
}
}
Test New Job Setup
With this refactored job class in place, we can come up with any testing-specific dummy implementations for source, sink, and mapper function and plug these into the job to test it without any external service dependencies.
A basic test for doing this could look as follows:
public class FruitEnricherJobTest {
@Test
@DisplayName("testing FruitEnricherJob")
public void shouldEnrichFruitIntakeEvents() throws Exception {
// given
var fruitIntakes = List.of(
new FruitIntake("raspberry", 1), new FruitIntake("unknown", 10),
new FruitIntake("melon", 2), new FruitIntake("banana", 3),
new FruitIntake("", 10), new FruitIntake("nofruit", 10)
);
// when
var dummySource = new TestCollectionSource<FruitIntake>(FruitIntake.class,
fruitIntakes, TypeInformation.of(FruitIntake.class));
var dummySink = new TestCollectionSink<FruitEnriched>();
var dummyMapper = new FruitNutritionMapper(new FakeNutritionEnricher());
var job = new FruitEnricherJob(dummySource, dummySink, dummyMapper);
job.run();
// then
var fruitEnrichedActual = dummySink.getElements();
var fruitEnrichedExpected = fruitIntakes.stream().map(
intake -> new FruitEnriched(intake,TestData.FRUIT_NUTRITION_LOOKUP_TABLE.get(intake.name))
).collect(Collectors.toList());
assertThat(fruitEnrichedActual, hasSize(fruitEnrichedExpected.size()));
assertThat(fruitEnrichedActual, containsInAnyOrder(fruitEnrichedExpected.toArray(new FruitEnriched[0])));
}
// additional dummy source, sink, and mapper implementations here…
}
Find further details including the dummy implementations in the <span class="inline-code">FruitEnricherJobTest</span> class.
Integration Testing the Job
The good news is that none of the refactorings suggested above get into the way of proper integration testing. Given that there is a Kafka dependency for this job, the Testcontainers project is an obvious choice to bootstrap an on-demand Kafka container as part of the job test lifecycle. Additionally, the Decodable Pipeline SDK provides a handy PipelineTestContext utility class. It allows for high-level interaction with Decodable Streams i.e. Kafka topics from within test code as well as asynchronously running the main method of a Flink job to finally inspect and assert its results. Find below an example of such an integration test, which runs against this job's real external dependencies, namely, the Kafka source / sink, and the 3rd HTTP service to enrich the incoming fruit intake events.
@Testcontainers
public class FruitEnricherJobIntegrationTest {
static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
@Container
public RedpandaContainer broker = new RedpandaContainer("docker.redpanda.com/redpandadata/redpanda:v23.1.2");
@Test
@DisplayName("testing FruitEnricherJob")
public void shouldEnrichFruitIntakeEvents() throws Exception {
TestEnvironment testEnvironment = TestEnvironment.builder()
.withBootstrapServers(broker.getBootstrapServers())
.withStreams(FruitEnricherJob.FRUIT_INTAKE_STREAM, FruitEnricherJob.FRUIT_INTAKE_ENRICHED_STREAM)
.build();
try (PipelineTestContext ctx = new PipelineTestContext(testEnvironment)) {
// given
var fruitIntakes = List.of(
new FruitIntake("raspberry", 1),
new FruitIntake("unknown", 10),
new FruitIntake("melon", 2),
new FruitIntake("banana", 3),
new FruitIntake("", 10),
new FruitIntake("nofruit", 10)
);
var intakePayloads = fruitIntakes.stream()
.map(fi -> {
try {
return OBJECT_MAPPER.writeValueAsString(fi);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
})
.collect(Collectors.toList());
intakePayloads.forEach(
payload -> ctx.stream(FruitEnricherJob.FRUIT_INTAKE_STREAM).add(new StreamRecord<>(payload)));
// when
ctx.runJobAsync(FruitEnricherJob::main);
List<StreamRecord<String>> results =
ctx.stream(FruitEnricherJob.FRUIT_INTAKE_ENRICHED_STREAM)
.take(intakePayloads.size()).get(30, TimeUnit.SECONDS);
// then
var fruitEnrichedActual =
results.stream().map(sr -> {
try {
return OBJECT_MAPPER.readValue(sr.value(), FruitEnriched.class);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}).collect(Collectors.toList());
var fruitEnrichedExpected = fruitIntakes.stream().map(
intake -> new FruitEnriched(intake,TestData.FRUIT_NUTRITION_LOOKUP_TABLE.get(intake.name))
).collect(Collectors.toList());
assertThat(fruitEnrichedActual, hasSize(fruitEnrichedExpected.size()));
assertThat(fruitEnrichedActual,containsInAnyOrder(fruitEnrichedExpected.toArray(new FruitEnriched[0])));
}
}
}
Happy Flink job testing!
📫 Email signup 👇
Did you enjoy this issue of Checkpoint Chronicle? Would you like the next edition delivered directly to your email to read from the comfort of your own home?
Simply enter your email address here and we'll send you the next issue as soon as it's published—and nothing else, we promise!
👍 Got it!
Oops! Something went wrong while submitting the form.
Hans-Peter Grahsl
Hans-Peter Grahsl is a Staff Developer Advocate at Decodable. He is an open-source community enthusiast and in particular passionate about event-driven architectures, distributed stream processing systems and data engineering. For his code contributions, conference talks and blog post writing at the intersection of the Apache Kafka and MongoDB communities, Hans-Peter received multiple community awards. He likes to code and is a regular speaker at developer conferences around the world.
Testing Flink jobs can be challenging for a number of reasons, one of them being the fact that we typically have to interact with external data systems or services. In this article we are picking up the custom Apache Flink job from one of our recent blog posts and dive into different aspects related to testing. More specifically, we'll discuss how to (re)write (existing) Flink jobs in a more modular way by defining job-specific interfaces for the actual processing logic and by making the source and sink components which talk to external data systems pluggable. Doing so allows us to not only unit test certain job components in isolation, but instead test the full processing logic of said jobs without the stringent necessity to always have access to any external services our Flink jobs almost certainly depend on.
Quick Recap of the Flink Job
The example job in question reads JSON payloads from a Kafka topic which describe fruit intake events that look as follows:
{
"name": "Banana",
"count": 1
}
These events are supposed to be enriched with the respective nutrition values of the various fruits which can be retrieved from a 3rd party service. The enriched events are written back to another Kafka topic and are expected to result in a payload shape like this:
The illustration below shows a high level view of how the Flink job at hand is currently implemented:
It is immediately visible that the job implementation as-is contains three components which directly depend on external services. Source and sink both need Kafka while the processing logic relies on the availability of a 3rd party HTTP service. This is anything but convenient from a job testing perspective because it means we are basically forced to always perform integration tests against all external service dependencies to be able to test a full end-to-end flow for this Flink job. While these types of job tests are absolutely vital, there are good reasons why you might want to only test the actual data processing in isolation at different levels.
That said, this job would ideally allow for swapping out any of these three components and instead plugging in dummy implementations or mocks for the sake of easier and isolated testability. Let's figure out ways to improve this situation and address the shortcomings induced by the tight coupling to external service dependencies.
Refactoring for Better Job Testability
Using the original code example as a starting point, we are going to refactor this job and its components step by step to make certain aspects of the implementation pluggable and thereby achieve better job testability. The full source and test code for this article can be found in our examples repository here.
Adapt Job Processing Logic
Let's begin with the core processing logic for the event payload enrichment which originally looked like this:
public class HttpServiceEnricher implements MapFunction<FruitIntake, FruitEnriched> {
public static final String API_SERVICE_ENDPOINT = "https://fruityvice.com/api/fruit/%s";
private static transient ObjectMapper OBJECT_MAPPER = new ObjectMapper();
private static transient HttpClient HTTP_CLIENT = HttpClient.newHttpClient();
@Override
public FruitEnriched map(FruitIntake intake) throws Exception {
// original enrichment implementation here
// doing HTTP calls against the API …
}
}
While being relatively straightforward, the code is inherently tied to making HTTP calls against a 3rd party service. This makes it unnecessarily hard to properly test it in isolation or plug in other implementations based on, for instance, static test data. One way, to improve this is by extracting the core logic i.e. the enrichment aspect of this function into a separate class which implements this custom interface:
//interface
public interface NutritionEnricher {
FruitEnriched enrich(FruitIntake intake);
}
//default implementation
public class HttpNutritionEnricher implements NutritionEnricher, Serializable {
public static final String API_SERVICE_ENDPOINT = "https://fruityvice.com/api/fruit/";
private static final transient ObjectMapper OBJECT_MAPPER = new ObjectMapper();
private static final transient HttpClient HTTP_CLIENT = HttpClient.newHttpClient();
private String apiServiceEndpoint;
public HttpNutritionEnricher() {
this.apiServiceEndpoint = API_SERVICE_ENDPOINT;
}
public HttpNutritionEnricher(String apiServiceEnpoint) {
Objects.requireNonNull(apiServiceEnpoint);
this.apiServiceEndpoint = apiServiceEnpoint;
}
@Override
public FruitEnriched enrich(FruitIntake intake) {
/* pretty much the same implementation here */
}
}
With this in place, the <span class="inline-code">MapFunction</span> in our Flink job doesn't do much any longer but rather delegates its work to any implementation that follows this <span class="inline-code">NutritionEnricher</span> interface.
public class FruitNutritionMapper implements MapFunction<FruitIntake, FruitEnriched> {
private final NutritionEnricher nutritionEnricher;
public FruitNutritionMapper() {
this.nutritionEnricher = new HttpNutritionEnricher();
}
public FruitNutritionMapper(NutritionEnricher nutritionEnricher) {
this.nutritionEnricher = nutritionEnricher;
}
@Override
public FruitEnriched map(FruitIntake intake) throws Exception {
return nutritionEnricher.enrich(intake);
}
}
Test New Job Processing Logic
Testing this <span class="inline-code">MapFunction</span> now becomes essentially a matter of testing the different interface implementations, first and foremost our <span class="inline-code">HttpNutritionEnricher</span> which acts as the default and for which you can find a basic test here. This particular test class still relies on access to the 3rd party service. However, by using tools or libraries such as WireMock, you could mock selected API calls and write a test class in the following way:
public class MockNutritionEnricherTest {
@RegisterExtension
static WireMockExtension WIRE_MOCK = WireMockExtension.newInstance()
.options(wireMockConfig().dynamicPort())
.configureStaticDsl(true).build();
@ParameterizedTest(name = "nutrition enrichment for valid fruit ''{0}'' with mocked api")
@ValueSource(strings = { "raspberry", "melon", "banana" })
public void testValidFruitWithMockedApi(String validFruitName) throws Exception {
// given
var fruitIntake = new FruitIntake(validFruitName, 1);
stubFor(
get("/"+validFruitName).willReturn(
jsonResponse(TestData.WIRE_MOCK_JSON_RESPONSES.get(validFruitName),200)
)
);
// when
var mockedEnricher = new HttpNutritionEnricher(WIRE_MOCK.getRuntimeInfo().getHttpBaseUrl());
var enrichedActual = mockedEnricher.enrich(fruitIntake);
// then
var enrichedExpected = new FruitEnriched(fruitIntake, TestData.FRUIT_NUTRITION_LOOKUP_TABLE.get(validFruitName));
assertEquals(enrichedExpected, enrichedActual);
}
/* more tests e.g. for invalid/unavailable fruit names here */
}
While there are of course other ways and means to come up with tests similar to this, the important aspect in the context of this article is to be able to independently test (parts of) our Flink job processing logic without relying on external service access all the time, here the 3rd party API.
Adapt Job Setup
What about the rest of this job's components and their testability? To remind ourselves, the Flink job reads the raw fruit intake events from an Apache Kafka source topic and writes enriched fruit events according to our processing logic into another sink topic. From a testing perspective, this means we have in total three components to consider, namely:
- the Flink connector source (here Kafka) to read from
- the map function representing the processing logic which we just covered in the previous section
- the Flink connector sink (also Kafka) to write to
The fact that our original Flink job uses the Decodable Pipeline SDK and operates on <span class="inline-code">DecodableStreamSource</span> / <span class="inline-code">DecodableStreamSink</span>—which are convenient wrappers to abstract away any Kafka specific data access—doesn't change anything about Kafka being used as an external dependency. This holds true not only for running but more importantly also for testing the Flink job at hand.
Taking a look at the existing job implementation, we can see at first glance that it is inflexible with regard to the above mentioned components because the whole job topology is rigidly assembled in the main method like so:
public static void main(String[] args) {
try {
var env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DecodableStreamSource<FruitIntake> source = DecodableStreamSource.<FruitIntake>builder()
.withStreamName(FRUIT_INTAKE_STREAM)
.withDeserializationSchema(new JsonDeserializationSchema<>(FruitIntake.class))
.build();
DecodableStreamSink<FruitEnriched> sink = DecodableStreamSink.<FruitEnriched>builder()
.withStreamName(FRUIT_INTAKE_ENRICHED_STREAM)
.withSerializationSchema(new JsonSerializationSchema<>())
.build();
// read the fruit intake events
env.fromSource(
source,
WatermarkStrategy.noWatermarks(),
"[stream-fruit-intake] fruit intake source")
// enrich the fruit intake events
.map(new HttpServiceEnricher())
// write the resulting events into the sink i.e. the enriched stream
.sinkTo(sink);
env.execute("fruit enricher cupi job with sdk");
} catch (Exception e) {
e.printStackTrace();
}
}
How could we fully test such a job run without depending on Kafka? More so, even if there is some (containerized) Kafka available wherever we plan to run any such tests, how should we go about the 3rd party HTTP service needed by the <span class="inline-code">MapFunction</span>? For the latter, one option would be to try and duplicate pretty much the whole job setup again in a test class and then only swap out the actual <span class="inline-code">MapFunction</span> for some other implementation which does the enrichments, for instance, based on some in-memory lookup table.
In general though, this is probably undesirable and might be better addressed by making all or at least selected job components pluggable right from the beginning, such that we can additionally provide testing-specific sources and sinks, thereby getting rid of the external Kafka dependency during test runs.
Another little refactoring leads us to a new Flink job class. The main difference to the original job class is that we now have:
- three pluggable job components defined as class members
- a constructor which allows to set these components according to our needs
- another method to set up the execution environment and define the job topology which was previously done in the main method directly</li>
All that is left to adapt is the main method which instantiates the pluggable components, feeds them into the job class’ constructor, and calls the <span class="inline-code">run()</span> method on the job instance:
@SourceStreams(FruitEnricherJob.FRUIT_INTAKE_STREAM)
@SinkStreams(FruitEnricherJob.FRUIT_INTAKE_ENRICHED_STREAM)
public class FruitEnricherJob {
public static final String FRUIT_INTAKE_STREAM = "fruit-intake";
public static final String FRUIT_INTAKE_ENRICHED_STREAM = "fruit-intake-enriched";
private final Source<FruitIntake, ?, ?> source;
private final Sink<FruitEnriched> sink;
private final MapFunction<FruitIntake,FruitEnriched> mapper;
public FruitEnricherJob(Source<FruitIntake, ?, ?> source, Sink<FruitEnriched> sink, MapFunction<FruitIntake,FruitEnriched> mapper) {
this.source = source;
this.sink = sink;
this.mapper = mapper;
}
public void run() {
try {
var env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// create and read data stream from source
env.fromSource(
source,
WatermarkStrategy.noWatermarks(),
"[stream-fruit-intake] fruit intake source")
// enrich the fruit intake events
.map(mapper)
// write the result into the sink i.e. the enriched stream
.sinkTo(sink);
env.execute("fruit enricher cupi job with sdk");
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
DecodableStreamSource<FruitIntake> source = DecodableStreamSource.<FruitIntake>builder()
.withStreamName(FRUIT_INTAKE_STREAM)
.withDeserializationSchema(new JsonDeserializationSchema<>(FruitIntake.class))
.build();
DecodableStreamSink<FruitEnriched> sink = DecodableStreamSink.<FruitEnriched>builder()
.withStreamName(FRUIT_INTAKE_ENRICHED_STREAM)
.withSerializationSchema(new JsonSerializationSchema<>())
.build();
MapFunction<FruitIntake,FruitEnriched> mapper = new FruitNutritionMapper();
var job = new FruitEnricherJob(source, sink, mapper);
job.run();
}
}
Test New Job Setup
With this refactored job class in place, we can come up with any testing-specific dummy implementations for source, sink, and mapper function and plug these into the job to test it without any external service dependencies.
A basic test for doing this could look as follows:
public class FruitEnricherJobTest {
@Test
@DisplayName("testing FruitEnricherJob")
public void shouldEnrichFruitIntakeEvents() throws Exception {
// given
var fruitIntakes = List.of(
new FruitIntake("raspberry", 1), new FruitIntake("unknown", 10),
new FruitIntake("melon", 2), new FruitIntake("banana", 3),
new FruitIntake("", 10), new FruitIntake("nofruit", 10)
);
// when
var dummySource = new TestCollectionSource<FruitIntake>(FruitIntake.class,
fruitIntakes, TypeInformation.of(FruitIntake.class));
var dummySink = new TestCollectionSink<FruitEnriched>();
var dummyMapper = new FruitNutritionMapper(new FakeNutritionEnricher());
var job = new FruitEnricherJob(dummySource, dummySink, dummyMapper);
job.run();
// then
var fruitEnrichedActual = dummySink.getElements();
var fruitEnrichedExpected = fruitIntakes.stream().map(
intake -> new FruitEnriched(intake,TestData.FRUIT_NUTRITION_LOOKUP_TABLE.get(intake.name))
).collect(Collectors.toList());
assertThat(fruitEnrichedActual, hasSize(fruitEnrichedExpected.size()));
assertThat(fruitEnrichedActual, containsInAnyOrder(fruitEnrichedExpected.toArray(new FruitEnriched[0])));
}
// additional dummy source, sink, and mapper implementations here…
}
Find further details including the dummy implementations in the <span class="inline-code">FruitEnricherJobTest</span> class.
Integration Testing the Job
The good news is that none of the refactorings suggested above get into the way of proper integration testing. Given that there is a Kafka dependency for this job, the Testcontainers project is an obvious choice to bootstrap an on-demand Kafka container as part of the job test lifecycle. Additionally, the Decodable Pipeline SDK provides a handy PipelineTestContext utility class. It allows for high-level interaction with Decodable Streams i.e. Kafka topics from within test code as well as asynchronously running the main method of a Flink job to finally inspect and assert its results. Find below an example of such an integration test, which runs against this job's real external dependencies, namely, the Kafka source / sink, and the 3rd HTTP service to enrich the incoming fruit intake events.
@Testcontainers
public class FruitEnricherJobIntegrationTest {
static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
@Container
public RedpandaContainer broker = new RedpandaContainer("docker.redpanda.com/redpandadata/redpanda:v23.1.2");
@Test
@DisplayName("testing FruitEnricherJob")
public void shouldEnrichFruitIntakeEvents() throws Exception {
TestEnvironment testEnvironment = TestEnvironment.builder()
.withBootstrapServers(broker.getBootstrapServers())
.withStreams(FruitEnricherJob.FRUIT_INTAKE_STREAM, FruitEnricherJob.FRUIT_INTAKE_ENRICHED_STREAM)
.build();
try (PipelineTestContext ctx = new PipelineTestContext(testEnvironment)) {
// given
var fruitIntakes = List.of(
new FruitIntake("raspberry", 1),
new FruitIntake("unknown", 10),
new FruitIntake("melon", 2),
new FruitIntake("banana", 3),
new FruitIntake("", 10),
new FruitIntake("nofruit", 10)
);
var intakePayloads = fruitIntakes.stream()
.map(fi -> {
try {
return OBJECT_MAPPER.writeValueAsString(fi);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
})
.collect(Collectors.toList());
intakePayloads.forEach(
payload -> ctx.stream(FruitEnricherJob.FRUIT_INTAKE_STREAM).add(new StreamRecord<>(payload)));
// when
ctx.runJobAsync(FruitEnricherJob::main);
List<StreamRecord<String>> results =
ctx.stream(FruitEnricherJob.FRUIT_INTAKE_ENRICHED_STREAM)
.take(intakePayloads.size()).get(30, TimeUnit.SECONDS);
// then
var fruitEnrichedActual =
results.stream().map(sr -> {
try {
return OBJECT_MAPPER.readValue(sr.value(), FruitEnriched.class);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}).collect(Collectors.toList());
var fruitEnrichedExpected = fruitIntakes.stream().map(
intake -> new FruitEnriched(intake,TestData.FRUIT_NUTRITION_LOOKUP_TABLE.get(intake.name))
).collect(Collectors.toList());
assertThat(fruitEnrichedActual, hasSize(fruitEnrichedExpected.size()));
assertThat(fruitEnrichedActual,containsInAnyOrder(fruitEnrichedExpected.toArray(new FruitEnriched[0])));
}
}
}
Happy Flink job testing!
📫 Email signup 👇
Did you enjoy this issue of Checkpoint Chronicle? Would you like the next edition delivered directly to your email to read from the comfort of your own home?
Simply enter your email address here and we'll send you the next issue as soon as it's published—and nothing else, we promise!
Hans-Peter Grahsl
Hans-Peter Grahsl is a Staff Developer Advocate at Decodable. He is an open-source community enthusiast and in particular passionate about event-driven architectures, distributed stream processing systems and data engineering. For his code contributions, conference talks and blog post writing at the intersection of the Apache Kafka and MongoDB communities, Hans-Peter received multiple community awards. He likes to code and is a regular speaker at developer conferences around the world.
.svg)