.svg)



In my last blog post I looked at why you might need CDC. In this post I’m going to put it into practice with probably the most common use case—extracting data from an operational transactional database to store somewhere else for analytics. I’m going to show Postgres to Snowflake, but the pattern is the same for pretty much any combination, such as MySQL to BigQuery, SQL Server to Redshift, and so on.
The data is a set of tables that take inspiration from Gunnar’s recent article about the Outbox pattern. We’re developing systems for a pet-grooming company, Oh-My-Dawg. But in this version of the cat-cleaning, guinea pig-grooming universe, we went with a monolithic application with all the data held on a single Postgres instance.
We’ve got a set of transaction tables in Postgres:

Customers have pets, pets need grooming and so they have appointments, and finally appointments are for pets and their owners. A straightforward data model, perfect for a transactional system. But for analytics, we don’t want to query it in place. Not only is querying the production database a bit of a no-no (for reasons including security of access and performance), it turns out that Oh-My-Dawg is a subsidiary of a larger pet care company which means analytics are done centrally on the Snowflake data warehouse platform.
So how do we get the data out of Postgres and over to Snowflake? We want it to be:
- Easy—we’ve got better things to do than mess about with complex tools and pipelines (however much fun they might be)
- Low impact on the source
- Low latency
This is where Decodable comes in. The Postgres CDC source connector (built on the industry-standard Debezium) captures changes to the source tables as they happen and writes them to Snowflake using the (guess what) Snowflake sink connector.
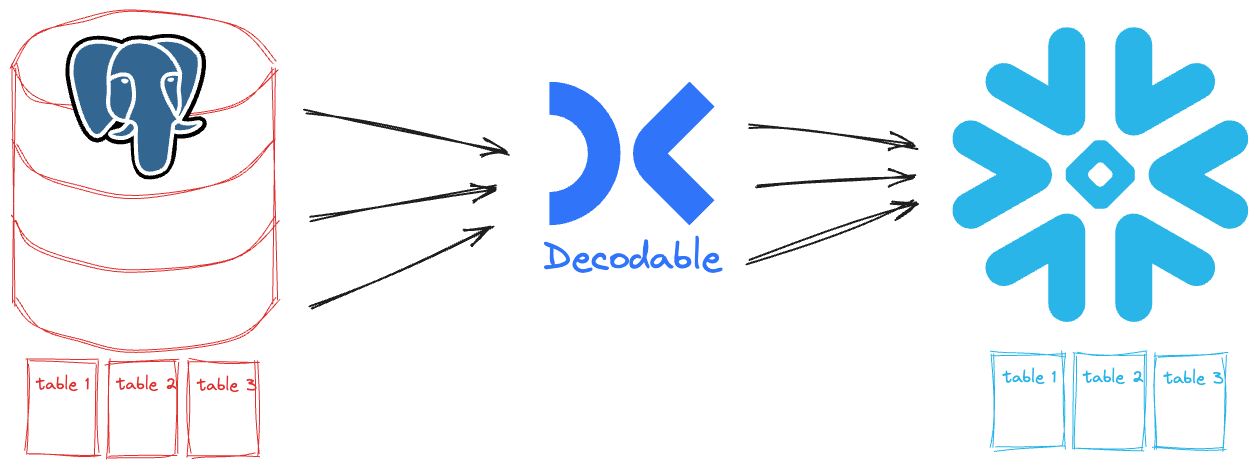
My Postgres database exists already, as does my Snowflake one. All we need to do in Decodable is connect them together. I want to show you two different ways you can do this, with the same end result. The first is point & click in the web interface, and the second is using our YAML-based declarative interface. As I said, the end result is the same, but you get to choose your own adventure.
Let’s start off with the visual approach since this also gives you a clear idea of what components we’re building with. In this post I’m going to give you an overview of what’s involved in building the pipelines. For a hands-on guide, sign up today and try out the quickstart.
Getting data out of Postgres with CDC
For CDC to work, the Postgres tables need to have replica identity set to <span class="inline-code">FULL</span>. This is so that the complete (i.e., the <span class="inline-code">FULL</span>) contents of the row are captured for each change.
Let’s go ahead and do this from the Postgres SQL prompt:
We’ll check it worked too—<span class="inline-code">relreplident</span> should be <span class="inline-code">f</span> (i.e., “full”):
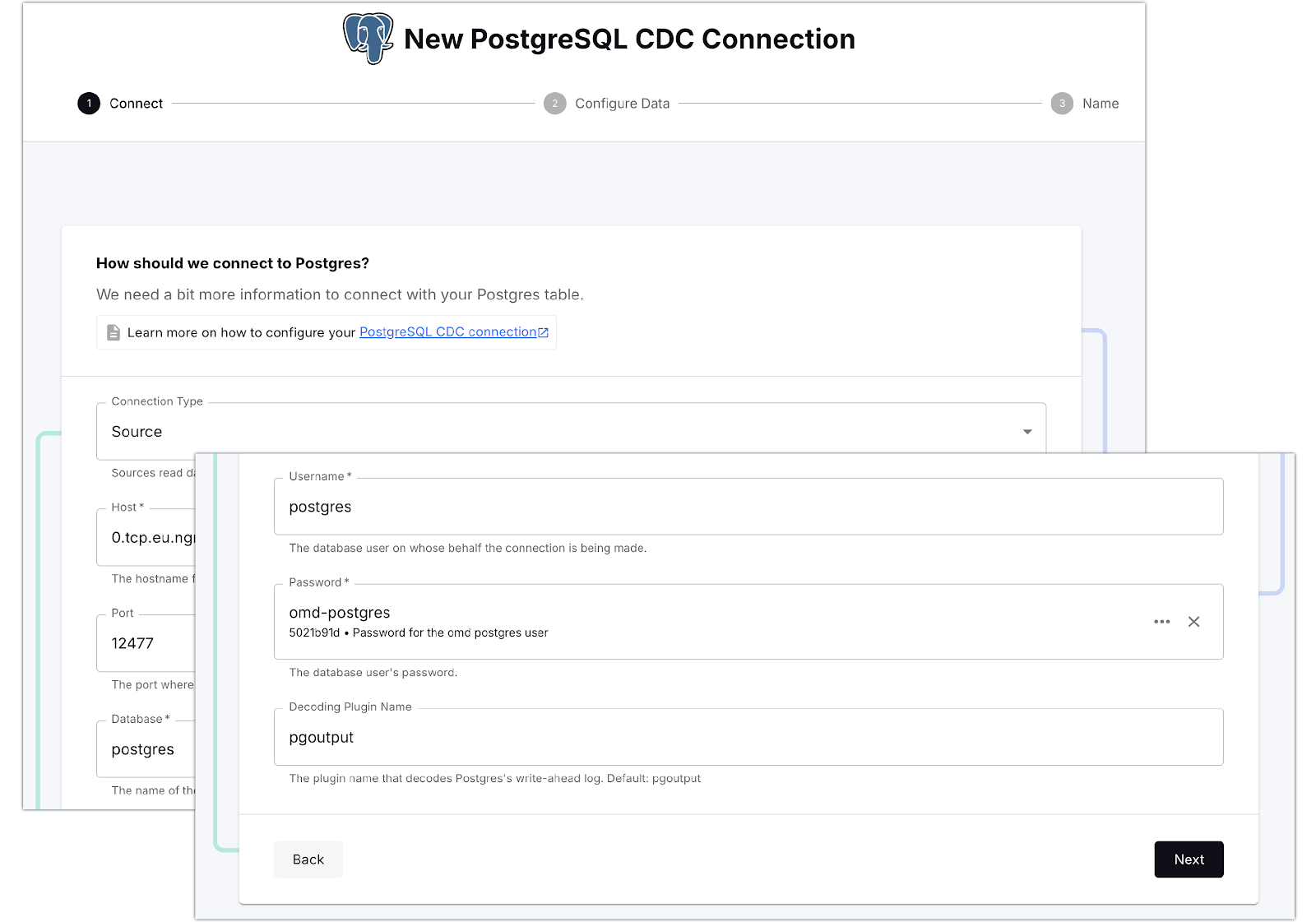
Now to connect Decodable to Postgres. In order for Decodable to authenticate to Postgres, it’ll need the user’s password. Decodable treats authentication credentials as first-class resources called secrets, so let’s add a secret that holds the Postgres user’s password:
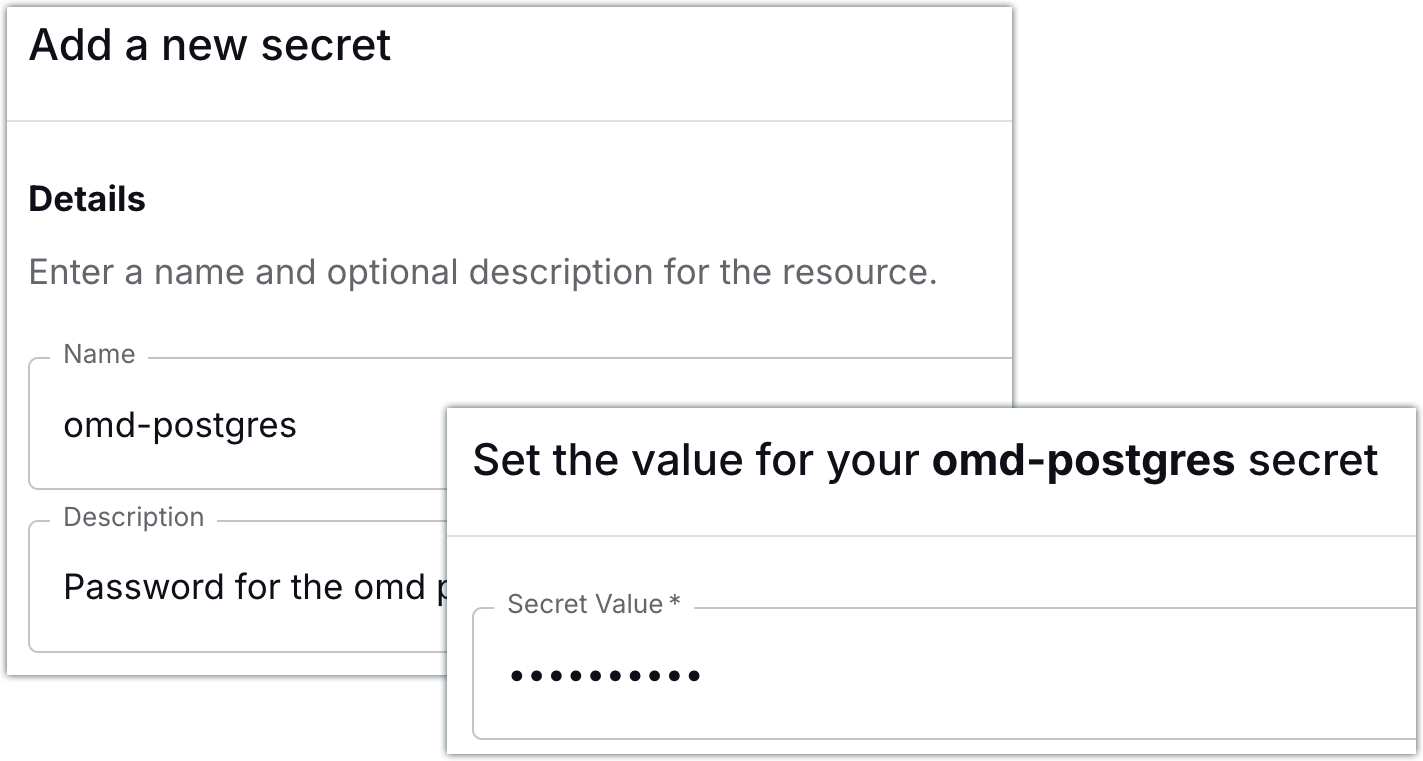
All set! Now we can go ahead and create our connection to Postgres.
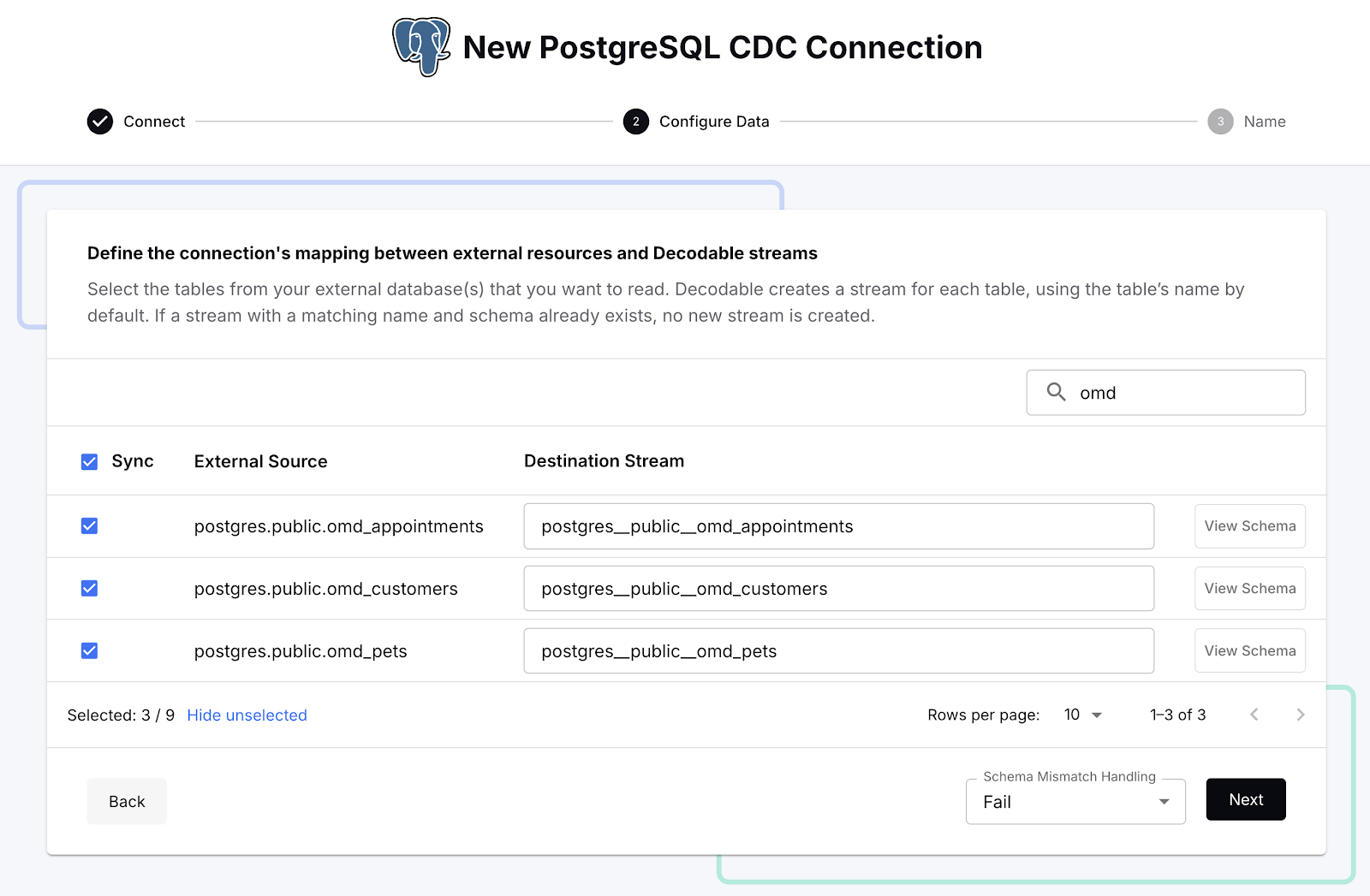
Once Decodable has connected to Postgres, it gives us a list of the available tables. There are quite a lot of tables in the database, and for our purpose we only want the Oh-My-Dawg (omd) ones, so let’s search for those and select them:
With that done we can create the connection, start it, and see in the Decodable console a nice visual representation of the three streams that are populated from the Postgres data that we selected. A stream in Decodable is a series of records similar in concept to a Kafka topic or Kinesis stream, and used to connect connectors and pipelines together:
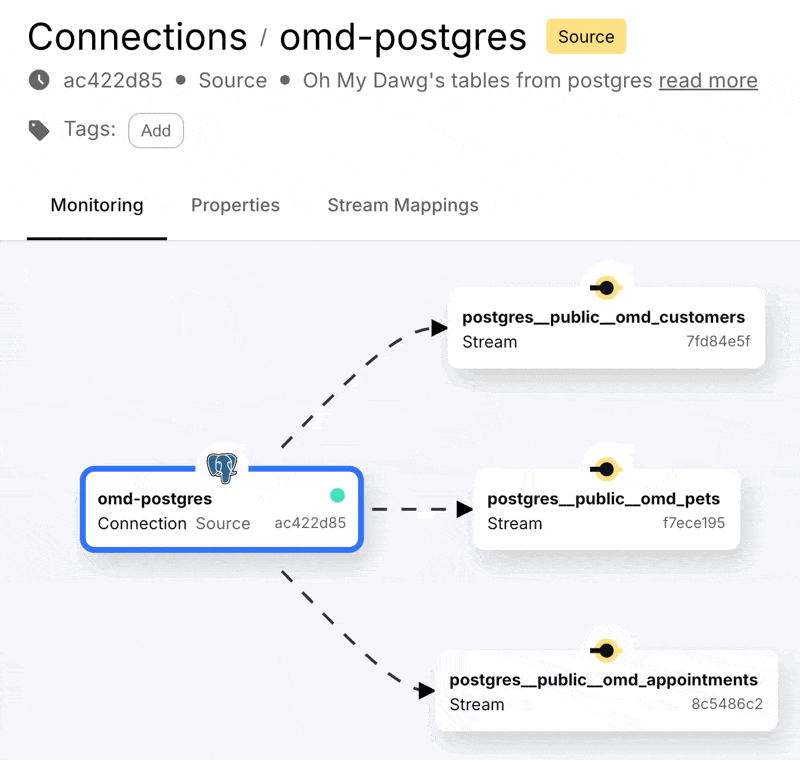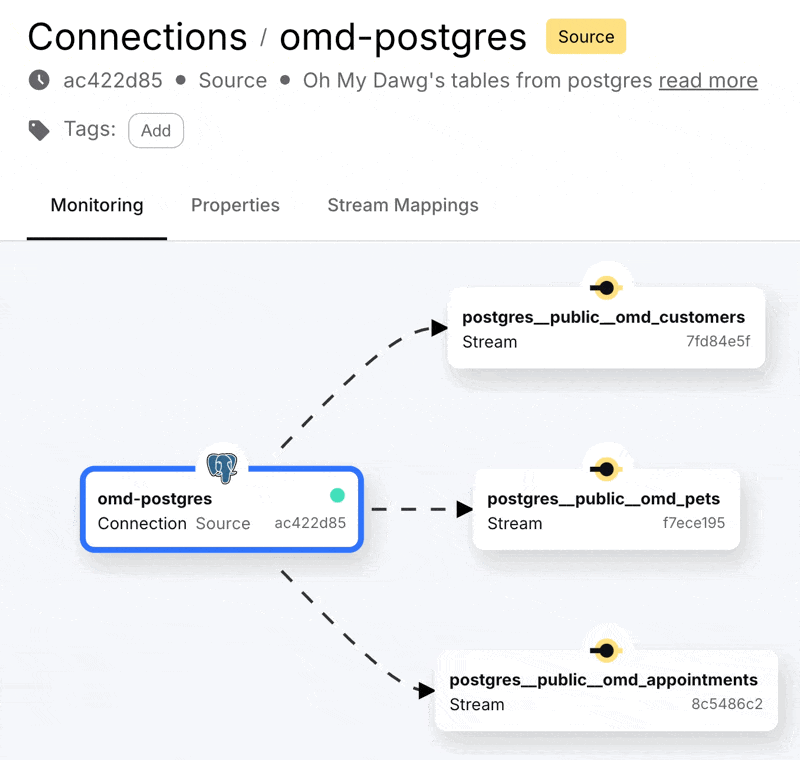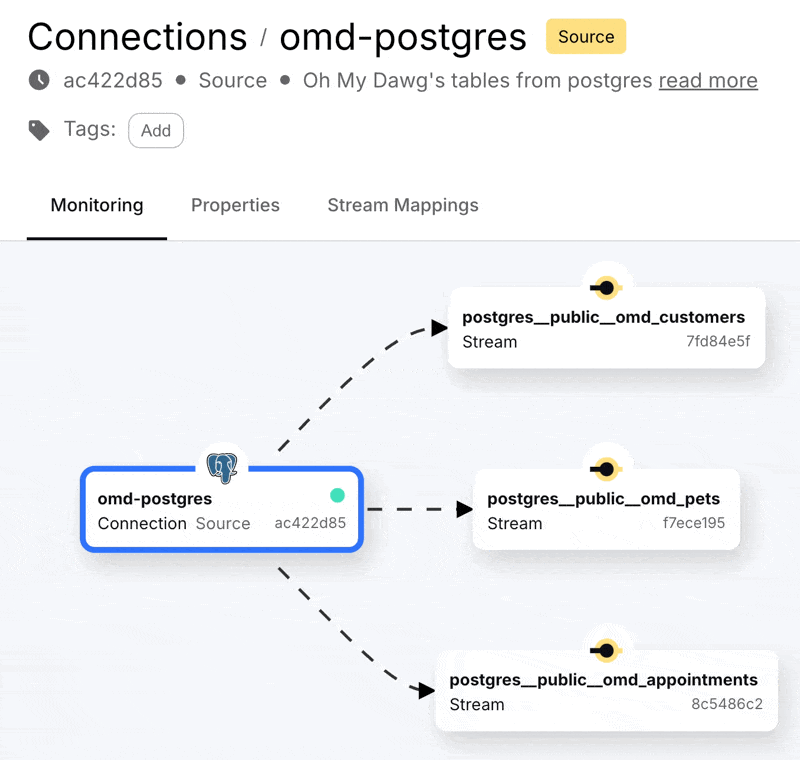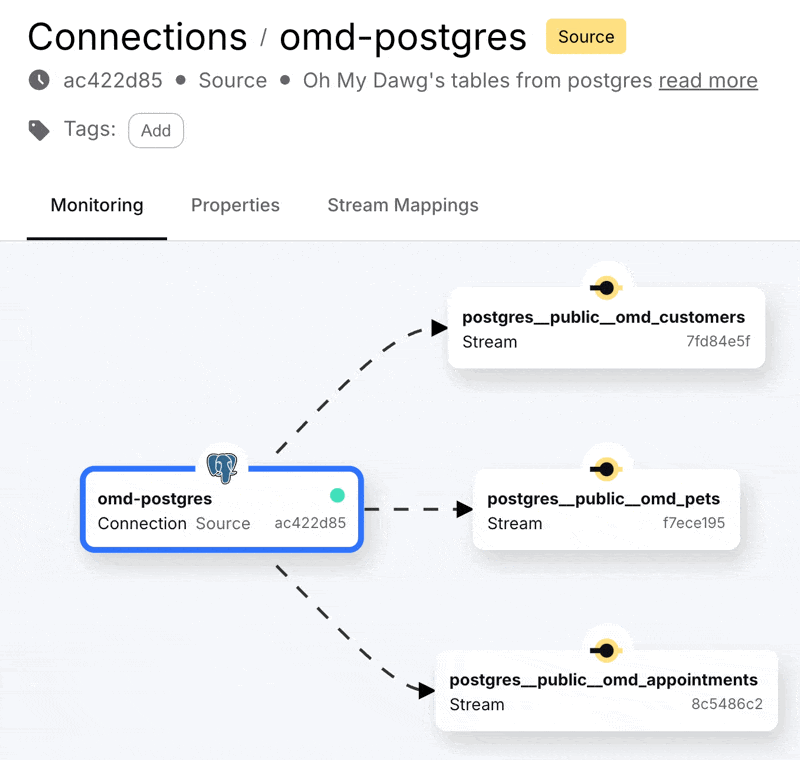
Clicking on one of these streams we can see the full snapshot of the data is in the stream, along with the changes as they happen. Here’s a happy pooch who was first booked in for an appointment <span style="display:inline-block">(<span class="inline-code">Scheduled</span>)</span>, and then attended the appointment (<span class="inline-code">Completed</span>):
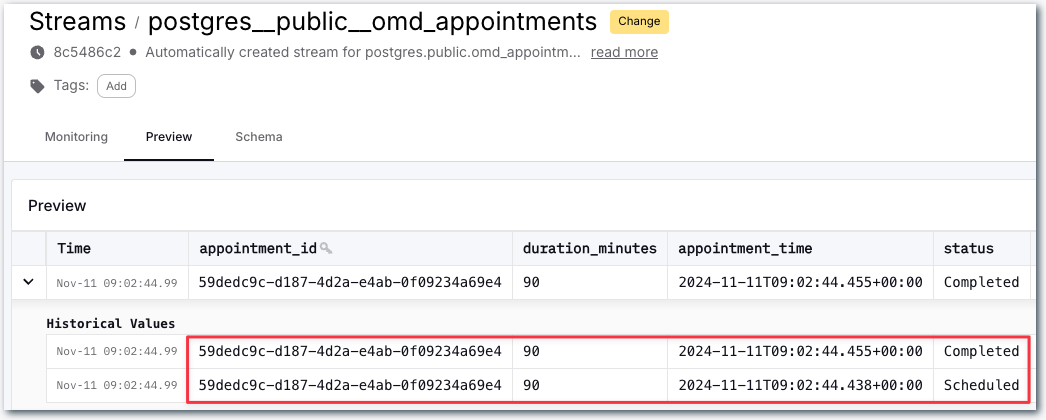
OK, so that’s the data coming from Postgres. Let’s now see about sending it over to Snowflake.
Loading data into Snowflake
Configuring authentication
Similar to when we set up the Postgres connector, we need to store the authentication credentials for Snowflake as a Decodable secret before setting up the connector itself.
The documentation is comprehensive, so I’ll not cover all the details here. In short, we need to generate a new key pair so that Decodable can authenticate as our Snowflake user.
This writes two files:
- <span class="inline-code">rsa_key.p8</span> - the private key. This is the bit that we need to keep secure as it confirms us as being us. We’ll store that as a secret in Decodable.
- <span class="inline-code">rsa_key.pub</span> - the public key. This is not sensitive and we can give to anyone—in this case, it’s what we attach to the Snowflake user.
To attach the public key to the Snowflake user, you need to extract the raw key itself, without the header and footer:
Then in Snowflake run an <span class="inline-code">ALTER USER</span> like this:
The <span class="inline-code">DECODABLE</span> user has just an arbitrary name; you can use an existing user if that suits your organization’s standards, or create a new one dedicated for this sink. Check the rest of the connector documentation for the additional authorisations that need configuring in Snowflake.
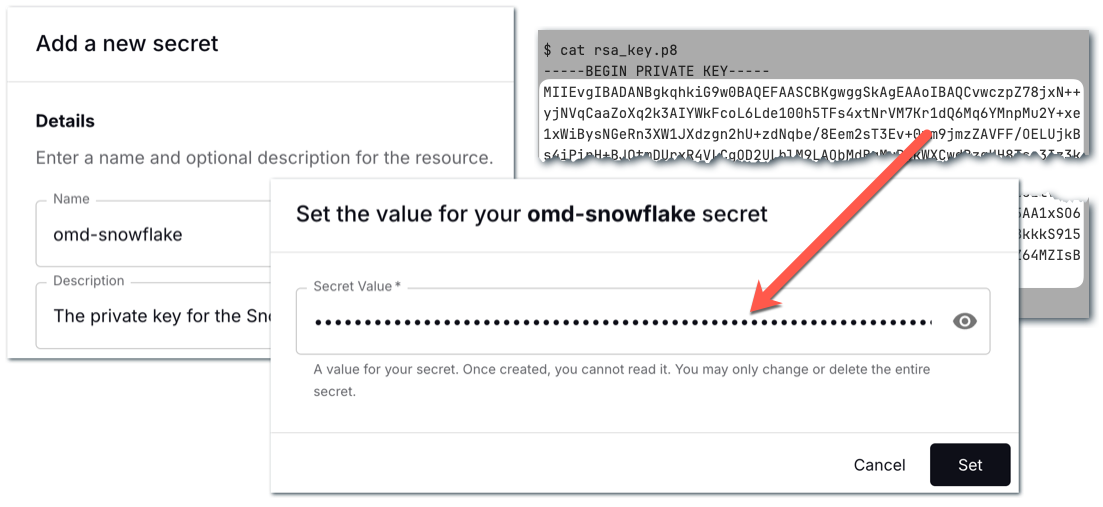
Now let’s add the private key to Decodable as a secret. The process is the same as when we set up the Postgres password above. As before, make sure you are only using the key itself and not the header or footer:
Creating the Snowflake connector
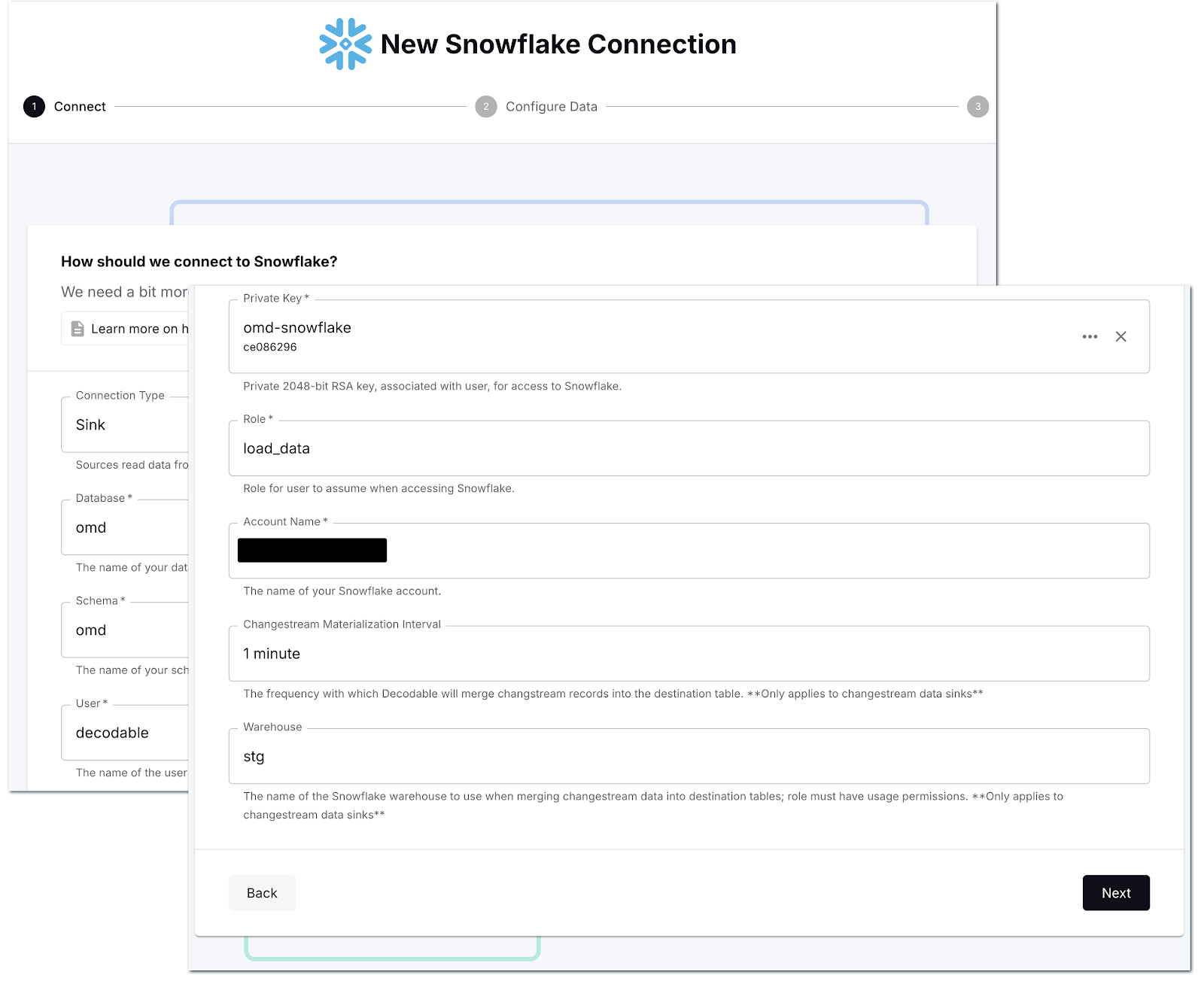
Now all that remains is to create the sink connector to send the data we’re ingesting from Postgres to Snowflake. First off we define the connection details, including the name of the secret that we created to hold the private key:
Then we select which streams we want to send to Snowflake—as before, there’s a search box to help us narrow it down so we can select just the ones that we want.
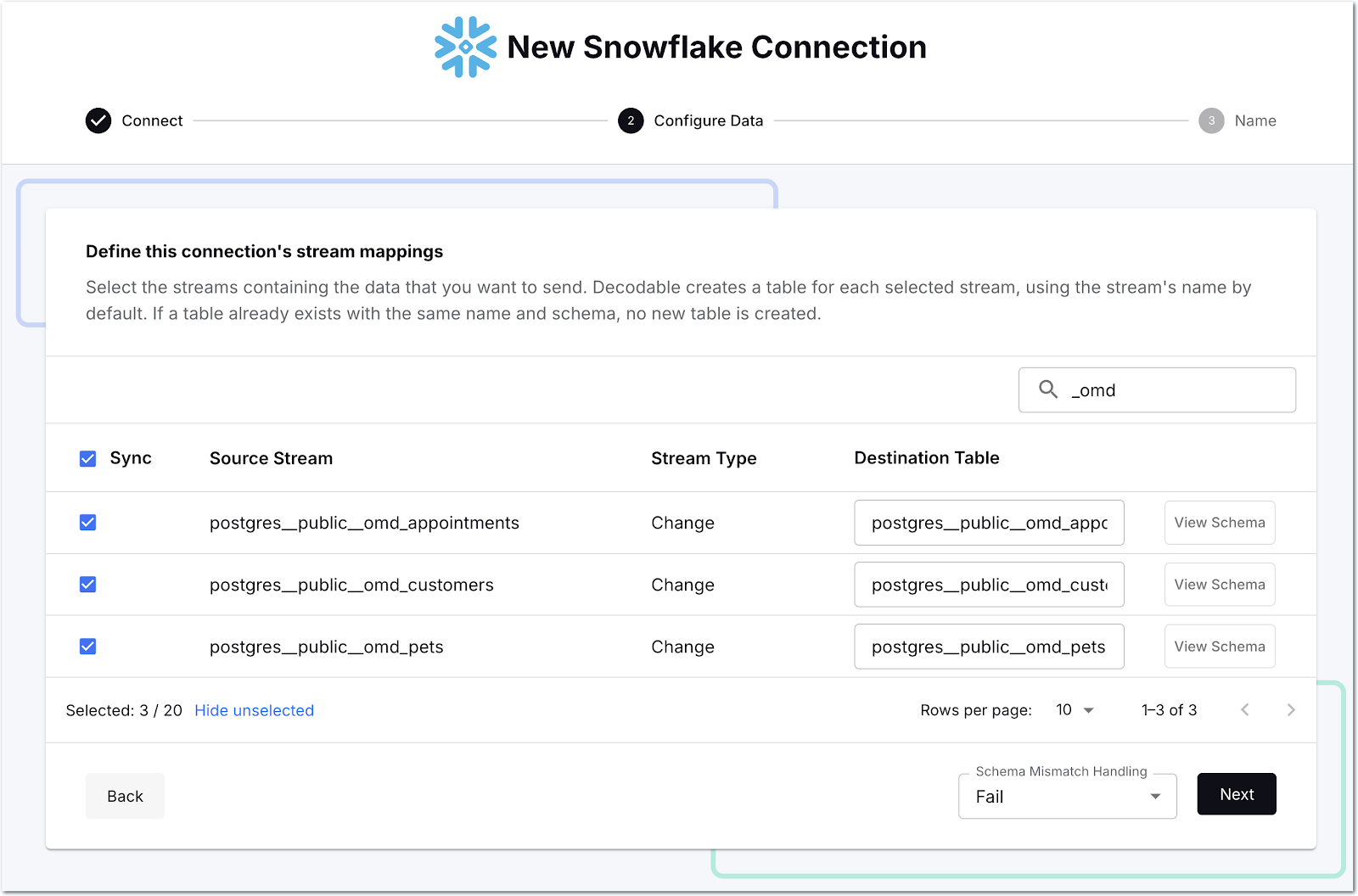
One thing you can change if you want is the name of the target table; since there’s a bunch of Postgres namespace stuff in there, I’m going to tidy it up a bit:
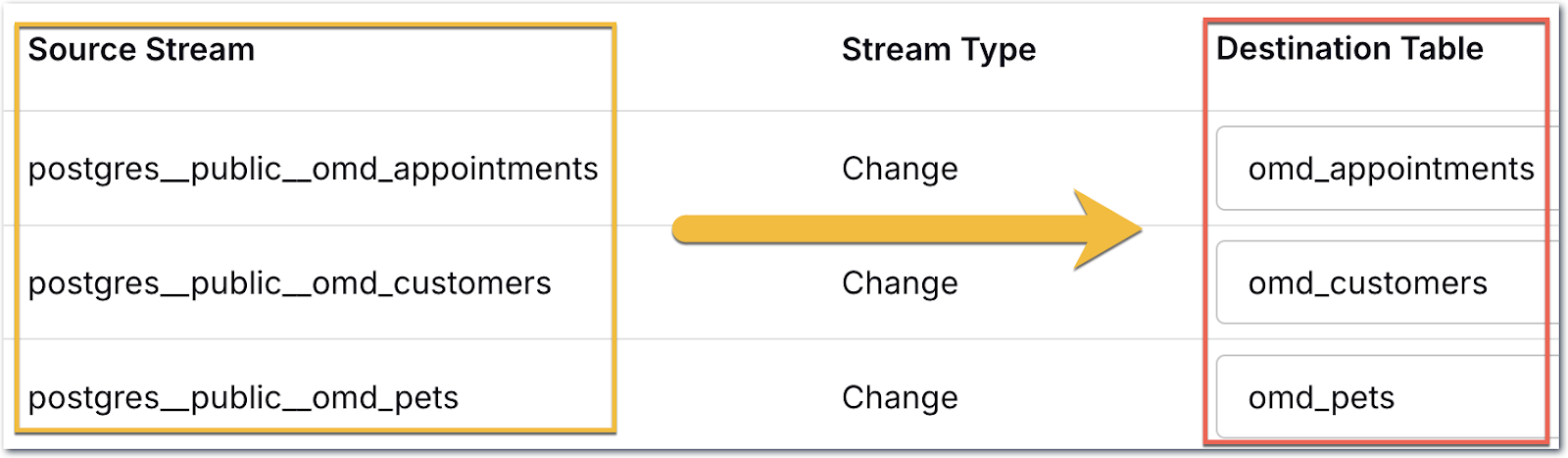
The connector will create the table for me in Snowflake since they don’t exist already. Now we start the connection, and off it goes!
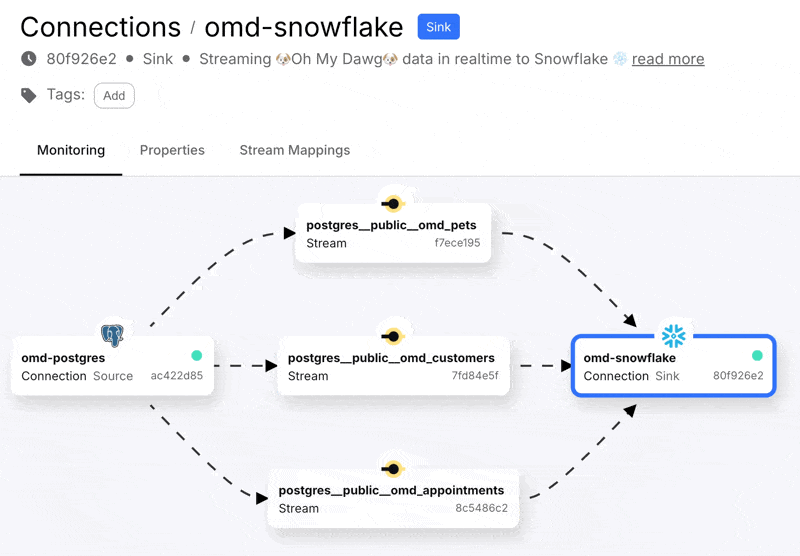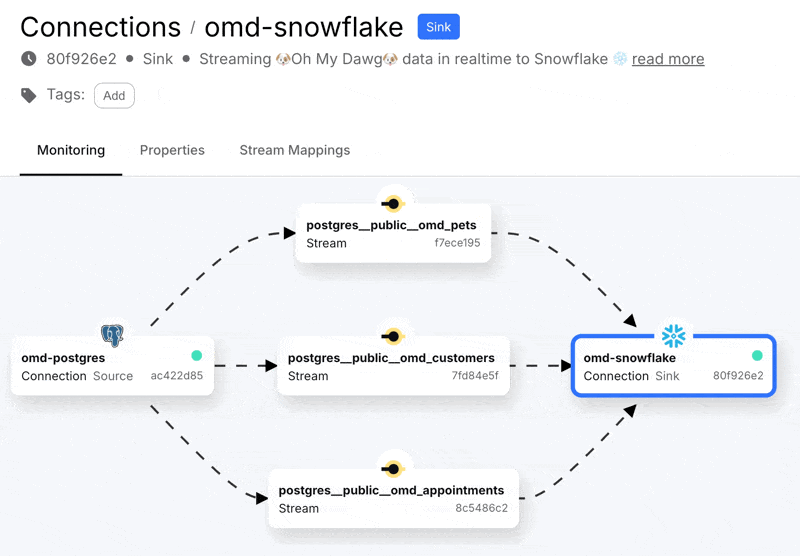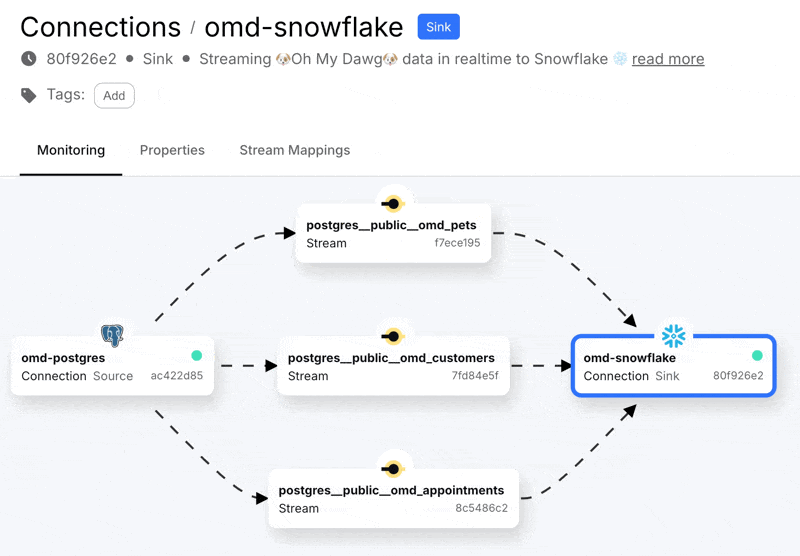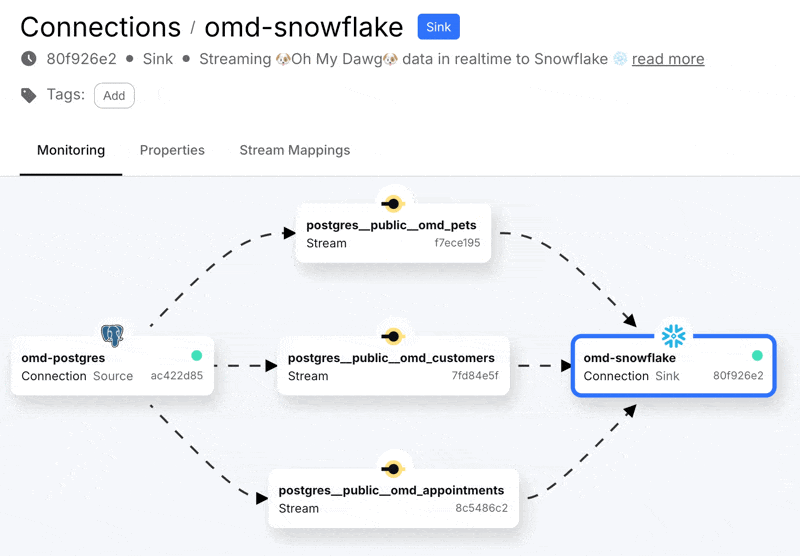
Heading over to Snowflake we can see we’ve got data:
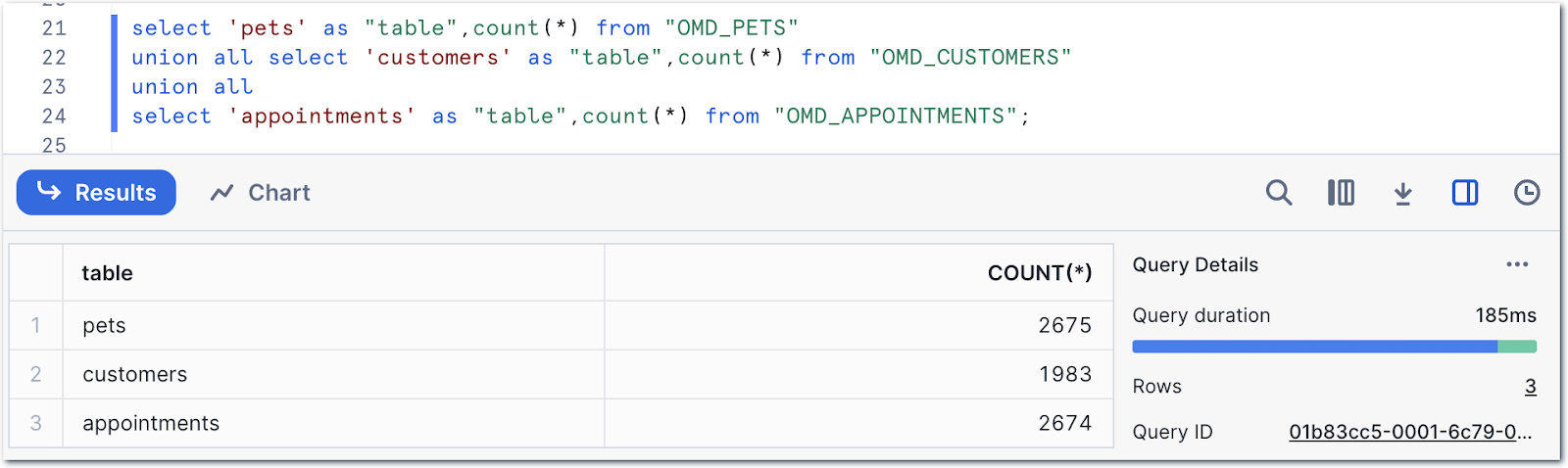
Referring to the data model at the top of the post, we can construct a query to start to denormalise the data:
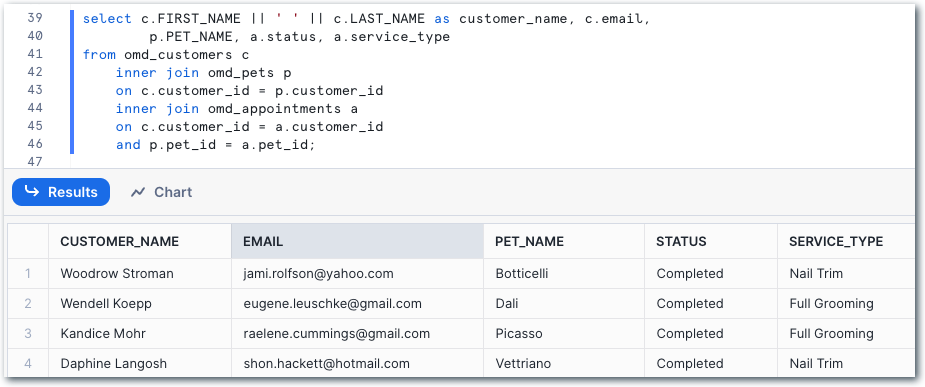
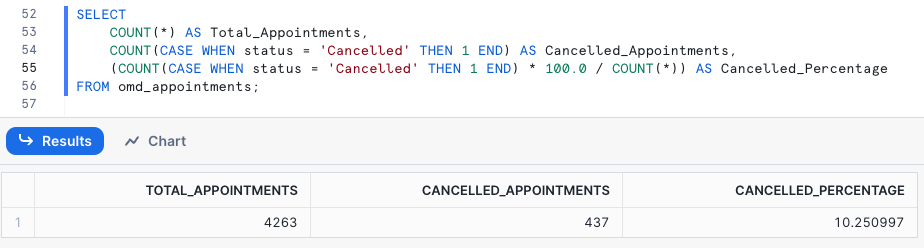
and build analytical queries on it, such as looking at the proportion of appointments that get canceled:
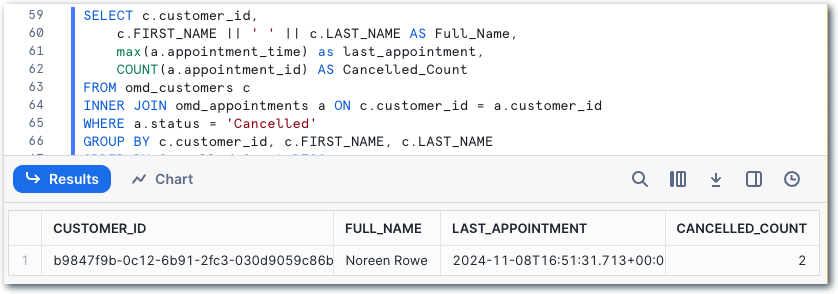
or which customer has canceled appointments the most:
Let’s do the same thing, but declaratively
If the mouse, or trackpad, is your thing, look away now. If, on the other hand, nothing gets you more excited than the idea of a keyboard, a CLI, and a git repository, then this section is for YOU.
Declarative resource management in Decodable will be familiar to anyone who has worked with tools such as Terraform. Instead of giving a set of imperative instructions (“Do this!”, “Create this!”, “Change this!”) you declare how things should look, and the declarative process then makes it so.

What this means in the context of Decodable is that we can build a set of YAML documents that describe the resources that we created above (two secrets, two connectors, three streams), and then run a command to make sure that our Decodable account reflects this. If it doesn’t, it’s updated by the declarative process until it is. This is perfect for things like putting your data pipelines into source control, as well as automating deployments.
To start off, we’ll create YAML documents that describe the secrets. Whether you create one YAML file for everything, one per resource, or somewhere in between (e.g. one per set of secrets, or per pipeline) is entirely up to you. Here I’ll create one per resource just to make it clear. Note that embedding secret values like this in plain text is not a great idea—better is to provide the value as a file (which could be populated from your organization’s secrets manager) or an environment variable.
The Postgres secret looks like this:
Whilst the Snowflake one is a bit more complex because of the private key (don’t bother trying to hack into my Snowflake account, this is not my actual key 😉):
Declarative resource management in Decodable is provided by commands under the Decodable CLI - primarily <span class="inline-code">decodable apply</span> and <span class="inline-code">decodable query</span>. Let’s use the first of these to make sure the secrets we’ve defined are present and up to date.
Now we can create the YAML resource definitions for the Postgres and Snowflake connections. We could write the YAML by hand. But who has time for that? Wouldn’t it be nice if we could find out the data that’s available and generate the resource definition from that instead? That’s where <span class="inline-code">decodable connection scan</span> comes in. We pass it the details of the connection that we want to create (name, type, host, etc.), as well as information about which tables we want <span style="display:inline-block">(<span class="inline-code">--include-pattern</span>)</span>, and finally what the target should be called <span style="display:inline-block">(<span class="inline-code">--output-resource-name-template</span>)</span>. The <span class="inline-code">-02</span> suffix is just to show things here and keep it separate from the web-based approach earlier.
Notice how the <span class="inline-code">password</span> property is passed by reference to the <span class="inline-code">omd-postgres</span> secret that was created above using command substitution. You don’t have to do this—you could also specify it directly.
Out of this scan command comes a nice set of YAML, describing the connection and its schemas:
We could make changes here to tweak things if needed, but let’s go ahead and apply this:
Now we’ve created the connection. But what if we realize we missed something, such as including a description for the connection? This is what the relevant section of the YAML looks like:
To make the change to the connection all we need to do is update the YAML file:
and then apply it again. Declarative resource management compares the file to the current state and makes the needed changes. This is a lot nicer than the regular drop/create route that you’d need to go if you were doing things imperatively.
Note here how only the connection has <span class="inline-code">result: updated</span> — the resources that didn’t change (the streams) are <span class="inline-code">result: unchanged</span>.
Let’s check that the description of the connection is now as expected:
Having created the connection, we need to activate it. It’s actually possible to specify in the YAML that the connection should be active, but certainly whilst we’re finding our way, decoupling the creation from activation is useful. To activate it, we run:
Now let’s create the Snowflake connection. As before, we’re going to have Decodable generate the YAML for us, with all we need to do being to specify the connection details.
This time we’re not going to write it to an intermediate YAML file to then run through decodable apply, but just pipe it directly in. It’s up to you if you want to do this. For scratching around in development I find it’s quicker (and you can always get the YAML at a later date with <span class="inline-code">decodable query</span>). You may prefer to write it to a file for visibility of what’s being run and any troubleshooting.
With the above run, we get a connection writing to three Snowflake tables created:
So let’s activate the connection:
And now we have data in Snowflake!
Should you use a web interface or the declarative approach?

A pattern that we see users commonly adopting is that they’ll prototype and build pipelines in the web interface. Once they’ve tested them and ironed out any wrinkles, they then export these to YAML (using <span class="inline-code">decodable query</span>) and use them declaratively from there on, through staging environments and on into production. Decodable supports workflows in GitHub for exactly this approach. You can take it a step further and consider generating YAML resource files from a template driven with a tool like Jsonnet.
Summary
Getting data from Postgres into Snowflake needs not be hard work 😀. With Decodable and its comprehensive library of connectors you can get data from one system to another in a scalable, low-latency way.
In this post I showed two ways of creating this pipeline; using the web interface and using a YAML-based declarative approach. Both achieve the same result of a CDC connection to Postgres sending an initial full snapshot of the data followed by all subsequent changes to the data to Snowflake. With the data in Snowflake, we can perform whatever analytics on it that we want.
But Decodable is not just connectors, it also offers a powerful processing layer built on Flink SQL. With this, you could take the streams of data from Postgres and apply transformations before they’re written to Snowflake. For example, performing the denormalisation across the three source tables to then write One Big Table (OBT) to Snowflake, thus avoiding any need for subsequent pre-processing before analytical queries can be run.
Sign up for a free trial today and give Decodable a try.
You can find the source code used for the Postgres example, and sample YAML resource definitions, on GitHub.




